





Heute geben wir einen Sprung in die Qualität von unserem Index bekannt während wir auch URLs entfernen, die SO schlecht sind dass Google sie vor Jahre entfernt hat. In den letzten paar Monaten, müsstet Ihr gesehen haben wie stark sich die Größe unseres Indexes erhöht hat und jetzt sind wir zum Punkt gelangen wo wir uns entscheiden müssen ob wir schneller crawlen sollen…oder einfach nur schlauer crawlen.
Jeden Respekt an SEOMoz da sie dies schon vor einiger Zeit in ihr Modell eingebaut haben. Wir haben nicht vor unsere URL Zahlungen so stark zu verringern wie im Moz-Index (als dies geschrieben wurde hatten sie 89000 Millionen URLs während wir 498000 Millionen in unserem Fresh-Index alleine haben!), aber mit einem Index von dieser Größe, sind wir in der Lage gewesen eine Menge von URLs auf Domains zu finden, die dazu bestimmt sind (so sieht es zumindest aus) Crawler zu versauen.
Wir haben nicht vor, eine umfassende Liste von den URLs zu zeigen die wir weggewerft haben (was wäre eigentlich der Punkt von einem Index mit URLs die nicht mehr indexiert sind?), aber jede URL die Bedeutung hat wird nicht entfernt.
Was haben sie entfernt?
Hier ist ein Beispiel:
http://tbod.asia hatte 9,157,905 URLs in unserem alten Index von denen wir wussten. Aber – ihr Wert (und der Wert der Webseite) war so klein dass Google die ganze Domain fallengelassen hat:
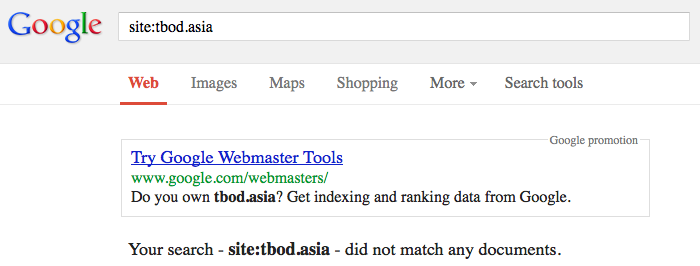
Leider scheint die Top-Level-Domain .asia besonders von diesem mechanischen Spam betroffen zu sein und wir haben diese gelöschte Seiten nur gefunden weil wir (wahrscheinlich) einige der internen Seiten gecrawlt haben. In der Tat – nachdem der Index gekeult wurde, werden wir Seiten auf gelöschte Domains sogar mit dem kleinsten Wert noch indexieren.
Wir dies Penguin-Untersuchungen beeinflussen?
Wir glauben nicht. Die URLs die wir gelöscht haben sind nicht wirklich anders als Session-Variablen, wenn wir von Wert sprechen. Google wird diese URLs nicht direkt bestrafen. Ein flüchtiger Blick deutet darauf hin, dass sie diese URLs aus ihrem Index (und wahrscheinlich auch aus ihrem Crawl) fallen lassen. Ob Sie es glauben oder nicht, gibt es eine Klasse von URLs die noch weniger Wert haben wie die die von Penguin bestraft werden. Diese URLs werden nie indexiert…und auch nicht bestraft…weil Google auch schlauer crawlen will. Crawlen ist teuer – effizienter und schlauer zu sein sollte die Mission von jedem Crawler sein.
Wieviele weniger Links werde ich jetzt zu meiner Seite sehen?
Für die meisten, keine! Um einen Link ZU Ihrer Seite zu sehen, müssen wir die Seite schon gecrawlt haben. Dies sind meistens URLs von denen wir schon etwas wissen, aber wo wir nie den Signal bekommen haben um diese URLs auch zu crawlen.
Warum macht diese Änderung Majestic noch besser?
Ganz einfach – Skala. Stellen Sie sich vor was wir noch für Sie tun könnten wenn wir die Maschinen die eigentlich nur crawlen und 150000 Millionen URLs indexieren, frei machen? Das ist ungefähr zweimal die Größe von SEOMoz’ gesamter Index.
Wenn wir diese entfernen wird:
- Alles anderes schneller machen
- Können wir in Zukunft noch mehr Daten sammeln
- Können wir unsere Flow Metrics und Indizen öfter aktualisieren
Was soll ich machen wenn meine Webseite in diese Änderung gelangt?
Wir hatten eine Support-Anfrage, die die Link-Zahl Änderungen seit dem Update befragt hat, wenn wir mehr bekommen können wir diese Änderung auch zwicken. Wir glauben aber nicht dass die meisten normalen Webseiten davon betroffen werden (auch Penguin Seiten) – Sie können unser Support zu jeder Zeit kontaktieren und wir können uns Ihre Webseite ansehen (Sie müssen aber genau sein). Nichts ist unwiederbringlich, aber schlauer crawlen ist ein Schritt auf dem Weg zu einem besseren Werkzeug.
- Bulk Backlink Checker Tutorial - August 1, 2013
- Der Osterei Release: Clique Hunter bei URL Ebene - July 29, 2013
- Umsetzbares SEO – Site Explorer und der Anker-Text Tab - July 25, 2013