





Normalerweise erwarten wir nicht, dass wir aufwachen und die Markennamen von Majestic überall im Ahrefs-Blog auftauchen, aber genau das ist gestern (Donnerstag, 22.Mai 2025) passiert. Ein neuer Blogbeitrag von Patrick Stox und Xibeijia Guan tauchte auf unserem Radar auf, mit dem Titel “The SEO Bots That ~140 Million Websites Block the Most”.
Ahrefs war so großzügig, MJ12bot ein paar Erwähnungen zu geben. Neben MJ12Bot wurden eine Reihe von SEO-Crawlern erwähnt, vor allem Ahrefsbot und Semrushbot. Diese drei wurden als SEO-Crawler mit signifikanter Präsenz in der Ahrefs-Analyse von Millionen von robots.txt-Dateien hervorgehoben.
Bei Majestic hatten wir in letzter Zeit einige Diskussionen über die Analyse von robots.txt-Dateien, da wir an der Einführung eines neuen Projekts gearbeitet haben. OpenRobotsTxt.org soll ein lebendes Archiv von robots.txt-Dateien sein. Das Archiv wird häufig aktualisiert, wobei die Daten automatisch analysiert werden, was zu häufigen Analysen führt. Es gibt Ähnlichkeiten zwischen der Art der Analyse, die OpenRobotsTxt durchführt, und der Analyse, über die Ahrefs in seinem jüngsten Beitrag berichtet.
Wir sind uns nicht sicher, ob der Start von OpenRobotsTxt als Katalysator für Ahrefs diente, um ihre eigene Studie zu veröffentlichen, oder ob die beiden Studien zufällig gleichzeitig veröffentlicht wurden.
Bevor wir beginnen, möchten wir darauf hinweisen, dass Backlink-Indizes nicht unbedingt die beste Bilanz aufweisen, wenn es um vergleichende Analysen geht. Viele in unserer Branche kennen die reiche Geschichte der Studien von Backlink-Datenbank-Anbietern. Eine Annäherung an diesen Prozess ist, dass ein Anbieter eine Studie in Auftrag gibt. Die Studie kommt dann zu dem Ergebnis, dass der Anbieter, der die Studie sponsert, das beste Produkt hat. Dann streiten sich andere Anbieter darüber, warum die Studie unfair und voreingenommen ist. Die Kunden sind gelangweilt und ziehen weiter. Einige Zeit vergeht. Die vorherige Studie wird zu einer fernen, schwachen Erinnerung und irgendein Anbieter beschließt, dass jetzt ein guter Zeitpunkt ist, um eine weitere Studie in Auftrag zu geben. Der Prozess wiederholt sich. Und wiederholt sich. Und wiederholt sich. Sie verstehen, was ich meine.
Wir hoffen, dass das Folgende als konstruktiver Ansatz für Feedback verstanden wird, aber bitte lassen Sie uns wissen, wenn Sie der Meinung sind, dass wir das Ziel verfehlt haben. Wir hoffen, dass wir diese Gelegenheit nutzen können, um einige der zugrundeliegenden Annahmen, die bei der Analyse der Daten für das OpenRobotsTxt-Projekt gemacht wurden, zu beleuchten und gleichzeitig einen hoffentlich fairen Kommentar zu Ahrefs neuester Analyse abzugeben.
Ein kurzer Abstecher zu OpenRobotsTxt – und warum wir uns für einen Kommentar qualifiziert fühlen.
Am Donnerstag, den 15. Mai 2025, gab Majestic den Start des OpenRobotsTxt.org-Projekts bekannt. Ziel von OpenRobotsTxt ist die Archivierung und Analyse der weltweiten robots.txt-Dateien. Das Projekt wurde mit einem riesigen Datendump von Majestic gestartet und wird nun regelmäßig aktualisiert.
OpenRobotsTxt.org ist ein langfristiges Projekt. Es werden laufend neue Daten hinzugefügt. Diese Daten werden automatisch analysiert, um Berichte zu erstellen. Die erstellten robots.txt-Statistiken werden unter einer Creative-Commons-Lizenz mit der Community geteilt.
Das Projekt hat es sich zur Aufgabe gemacht, die robots.txt-Dateien der Welt zu archivieren und zu analysieren. OpenRobotsTxt zielt darauf ab, die Debatte über robots.txt, Benutzer-Agenten und Web-Crawling zu informieren.
Es gibt einige Überschneidungen zwischen dem OpenRobotsTxt-Projekt und der Ahrefs-Roboterstudie.
Ein Vergleich der Ergebnisse zwischen der Ahrefs-Roboterstudie und OpenRobotsTxt
Die wichtigsten Ergebnisse der Ahrefs-Studie werden anhand von drei Datenpunkten dargestellt, die in der folgenden Tabelle aufgeführt sind:
| Raupenfahrzeug: | MJ12Bot ( Majestic ) | SemrushBot | Ahrefs-Bot |
| % der Websites in der Studie, die auf der Grundlage einer Untersuchung von 140 Millionen “Root-Domains” blockiert werden | 6.49% | 6.34% | 6.31% |
Daraus ergibt sich ein Durchschnitt von ( 6,49 % + 6,34 % + 6,31 % ) / 3 = 6,38 % für die drei Nutzeragenten. Ahrefs und Semrush liegen unter dem Durchschnitt, MJ12bot liegt darüber.
Ahrefs gibt an, dass ihre Studie auf Daten basiert, die von ihrem eigenen Crawler, dem Ahrefsbot, gesammelt wurden. Wir gehen daher davon aus, dass die Studie Websites ausschließt, die einen serverseitigen Bot-Block für den Ahrefs-Bot durchführen. Dieser Aspekt kann die oben gezeigten Daten mit einer gewissen Fehlerquote versehen. In Anbetracht der relativ geringen Unterschiede zwischen den Zählungen und der Tatsache, dass es sich um eine Studie eines einzigen Anbieters handelt, kann die Ahrefs-Studie als allgemeiner Hinweis auf eine Blockierungsrate von ca. 6,4 % für führende SEO-Bots in den analysierten robots.txt-Dateien interpretiert werden. Dies ist ein nützlicher Richtwert für Crawler-Betreiber überall. Wir bedanken uns bei Ahrefs für die Bereitstellung dieser Ergebnisse.
Das OpenRobotsTxt-Projekt berichtet über Daten zu User-Agent-Blocks etwas anders als die Ahrefs-Studie, aber wir können verschiedene Spalten, die sich auf Disallow beziehen, zusammenzählen, um eine Gesamtsumme zu erhalten. Das Ergebnis ist eine prozentuale Zahl, die die Anzahl der Erwähnungen eines Bots in einem Disallow-Kontext im Verhältnis zu den untersuchten Websites angibt:
| Raupenfahrzeug: | MJ12Bot ( Majestic ) | SemrushBot | Ahrefs-Bot |
| Prozentualer Anteil der Websites, die etwas nicht zulassen, basierend auf einer Untersuchung der Benutzer-Agenten von ~600 Millionen Hostnamen | 0.5% | 0.46% | 0.93% |
Es ist anzumerken, dass die hohe Zahl für Ahrefs in dieser Tabelle eine unverhältnismäßig große Anzahl pfadbasierter Verbotsstatistiken enthält. Um die Auswirkungen dieser Richtlinien zu messen, wären weitere Analysen erforderlich.
Es besteht ein signifikanter Unterschied zwischen den beiden Datensätzen. Der Unterschied zwischen dem Ahrefs-Datensatz und dem Majestic-Datensatz liegt in einer Größenordnung.
Warum?
Es wäre unfair, wenn wir zu viele Annahmen über die Ahrefs-Studie machen würden. Wir können jedoch mehr Informationen über die Zusammensetzung der 600 Millionen Hostnamen geben, die im OpenRobotsTxt-Projekt verwendet werden.
Der wichtigste Grundsatz ist, dass die OpenRobotsTxt-Hostnamen-Statistik auf auflösbaren Hostnamen basiert. Eine robots.txt-Datei ist für die Aufnahme nicht zwingend erforderlich. Diese Zahl umfasst daher auch Hostnamen, die keine robots.txt-Datei haben. Das bedeutet, dass die obige Statistik darauf hindeutet, dass 0,5 % der Websites zumindest einen Teil von MJ12Bot in der robots.txt-Datei explizit nicht zulassen. Nicht alle Hostnamen haben robots.txt, und ein 404 auf robots wird von den meisten Crawlern als Erlaubnis zum Crawlen interpretiert.
Ein weiterer wichtiger Aspekt des OpenRobotsTxt-Datensatzes ist, dass er protokollunabhängig sein soll. Dies basiert auf der Theorie, dass die meisten HTTPS-Websites denselben Inhalt wie die HTTP-Äquivalente anbieten. Die Alternative zu einer protokollunabhängigen Analyse birgt die Gefahr, dass robots.txt-Dateien (und damit Blöcke) doppelt gezählt werden, wenn sie sowohl auf http- als auch auf https-Versionen einer Website erscheinen. Wir glauben nicht, dass es sinnvoll ist, 600 Millionen Hostnamen mit 1,2 Milliarden möglichen robots.txt-Dateien gleichzusetzen.
Wie bei jeder Studie ist zu beachten, dass die beiden Studien auf unterschiedlichen Datensätzen beruhen, die von verschiedenen Webcrawlern erzeugt wurden. Unterschiedliche Web-Crawler nehmen Websites auf unterschiedliche Weise wahr, interpretieren Root-Domain-Namen möglicherweise anders und haben auch ihre eigenen, unterschiedlichen Rauschunterdrückungstechniken, die sich darauf auswirken können, wie viele Subdomains für die Erstellung von Hostnamenlisten abgetastet werden.
Unsere Meinung zu Methodik und Berichterstattung in der Ahrefs-Studie
Der Beitrag enthält einige interessante Aspekte über die Methodik der Studie:
- Der Datensatz scheint nur Websites zu enthalten, die Robots.Txt-Dateien hosten. Wir gehen davon aus, dass die Aufnahme auf die Dateien beschränkt ist, die vom Ahrefsbot SEO Crawler gefunden wurden.
- In der Ahrefs-Studie werden “andere Blocktypen wie Firewalls oder IP-Blöcke” nicht berücksichtigt. Dies kann einen erheblichen Einfluss auf die Schlussfolgerungen haben. Ein wichtiges Merkmal dieser Auswirkung ist, dass, wenn Ahrefsbot auf einem Server IP-blockiert ist, dies bedeutet, dass der Crawler möglicherweise am Zugriff auf die robots.txt-Datei gehindert wird. Dieser fehlende Zugriff kann dazu führen, dass diese Websites in der Studie nicht berücksichtigt werden. Das heißt, dass Websites, die Ahrefsbot nur über den Server blockieren, von der Studie ausgeschlossen werden können und somit keinen positiven “allow”-Status für andere Crawler aufweisen.
- Der Blog-Beitrag scheint über drei verschiedene Beispielsätze zu berichten. Ein Test mit 140 Millionen Root-Domänen, ein Test mit 461 Millionen Hostnamen und ein Beispielsatz für Top-Sites (DR > 45).
- Die Analyse auf Hostnamen-Ebene umfasst 461 Millionen robots.txt-Dateien und zeigt, dass Semrush in diesem Datensatz am häufigsten blockiert wird.
- Der Bericht über die Top Sites zeigt, dass Semrush auch in diesem Datensatz am meisten blockiert ist.
- MJ12bot wird als der am meisten blockierte Bot für die 140 Millionen Datenpunkte umfassende Stichprobe gemeldet.
Es scheinen mindestens drei Datensätze analysiert worden zu sein. Bei der Untersuchung von zwei der Datensätze scheint Semrushbot als der am meisten blockierte Bot identifiziert worden zu sein. In einer der drei Studien wird MJ12Bot als der am meisten blockierte Bot genannt.
Einige Beobachtungen und Gedanken werden in dem Beitrag zu MJ12bot vorgestellt:
- “Sie sind ein verteilter Crawler, das heißt, man kann sie nicht nach IPs suchen oder blockieren, was sie weniger vertrauenswürdig macht.
- “Sie durchforsten das Internet schon länger.”
- “Sie haben eine kleinere Nutzerbasis als populärere SEO-Tools und daher weniger Einfluss, um Blockaden zu beseitigen.”
Was den dritten Punkt anbelangt, so geben wir zu, dass wir im Vergleich zu den SEO-Tool-Giganten Semrush und Ahrefs der glückliche Außenseiter sind. Wir sind uns nicht sicher, inwiefern die Größe für eine Hebelwirkung sorgt. Seien Sie jedoch versichert, dass wir nicht die Absicht haben, die Jungs loszuschicken, um Webmaster zu “erziehen”, die von Zeit zu Zeit Probleme mit Bots haben könnten.
Wir geben auch zu, dass wir das Web schon länger als Ahrefs und Semrush crawlen. Von den dreien war MJ12Bot der erste, Ahrefs kam einige Zeit später, und Semrush ist ein neuerer Marktteilnehmer im Bereich der Backlinkanalyse. In Anbetracht der Tatsache, dass Semrushbot erst seit kürzerer Zeit aktiv ist, erschien uns das Ausmaß der Ablehnungen bemerkenswert. Mit Interesse haben wir gelesen, dass Ahrefs herausgefunden hat, dass Semrushbot anscheinend in ähnlichem Umfang wie Ahrefsbot und MJ12Bot gesperrt wird. Es wird interessant sein zu sehen, ob und wann die Anzahl der Disallows von Semrushbot andere SEO-Crawler überholt.
Der letzte Punkt bezieht sich auf das verteilte Crawl-Modell, das Majestic verwendet. Es ist kein Geheimnis, dass MJ12bot mit einem verteilten, gemeinschaftlichen Crawling-Modell arbeitet. Die Vorliebe für robots.txt-Blöcke gegenüber serverseitigen Blöcken, die der MJ12Bot-Benutzeragent an den Tag legt, ist schon seit einiger Zeit bekannt.
Erwähnungen vs. Nicht-Erwähnungen
Nicht jeder Hinweis in einer robots.txt-Datei ist für einen SEO-Crawler problematisch. Einige können sogar gute Nachrichten sein.
Die Ahrefs-Studie konzentriert sich nur auf Disallows, während das OpenRobotsTxt-Projekt eine Reihe von Signalen aus robots.txt-Dateien erfasst.
Einige SEO-Crawler wie Ahrefs und Majestic weisen eine signifikante Anzahl von Allow-Direktiven auf. Bis zu einem gewissen Grad könnte der Anteil der Erwähnungen, die explizite Disallows sind, als Stimmungswert der Webmaster für User-Agenten interpretiert werden. Das heißt, eine Erwähnung in Robots, die kein Disallow ist, ist ein Beweis dafür, dass Webmaster über den Agenten Bescheid wissen, ihn aber nicht blockieren wollen.
OpenRobotsTxt erzeugt diese “Sentiment Score”-Zahl für alle User Agents. Für die “Großen Drei”, die wir bisher besprochen haben, meldet OpenRobotsTxt die folgende Stimmung:
| Raupenfahrzeug: | Ahrefsbot | SemrushBot | MJ12Bot ( Majestic ) |
| Stimmung (% der Erwähnungen sind abwertend) NIEDRIGER IST BESSER | 34% | 69% | 40% |
Diese Interpretation der OpenRobotsTxt-Daten deutet darauf hin, dass Ahrefsbot zwar der meistgenannte SEO-Crawler der drei ist, aber auch der beliebteste nach diesem Maßstab. Semrushbot scheint in dieser Wertung etwas hinterherzuhinken. Wir vermuten, dass der Grund für das gute Abschneiden von MJ12Bot und Ahrefsbot darin liegt, dass beide Tools den Inhabern von Domainnamen, die die Website verifizieren, einen erweiterten Service bieten.
Diese Übung zeigt, dass eine Erwähnung in der robots.txt nicht unbedingt schlecht ist.
Und, Ehre, wem Ehre gebührt. Glückwünsche gebühren dem gesamten Ahrefs-Team für seine Leistung. Ihr Bemühen, Webmaster für sich zu gewinnen, hat dazu geführt, dass die drei aufgelisteten SEO-Crawler die beste Webmaster-Stimmung aufweisen.
Verstehen der OpenRobotsTxt User-Agent Analysedaten
Für die auf OpenRobotsTxt bereitgestellte Analyse werden archivierte robots.txt-Dateien untersucht. Dabei werden die User Agents normalisiert, um das Rauschen zu reduzieren und die Absicht des Robots.txt-Autors anzuzeigen.
Nach dem Parsen der Dateien wird eine Reihe von Statistiken erstellt. Diese Statistiken können von der Website openrobotstxt.org heruntergeladen werden und stehen unter einer Creative-Commons-Lizenz zur Verfügung.
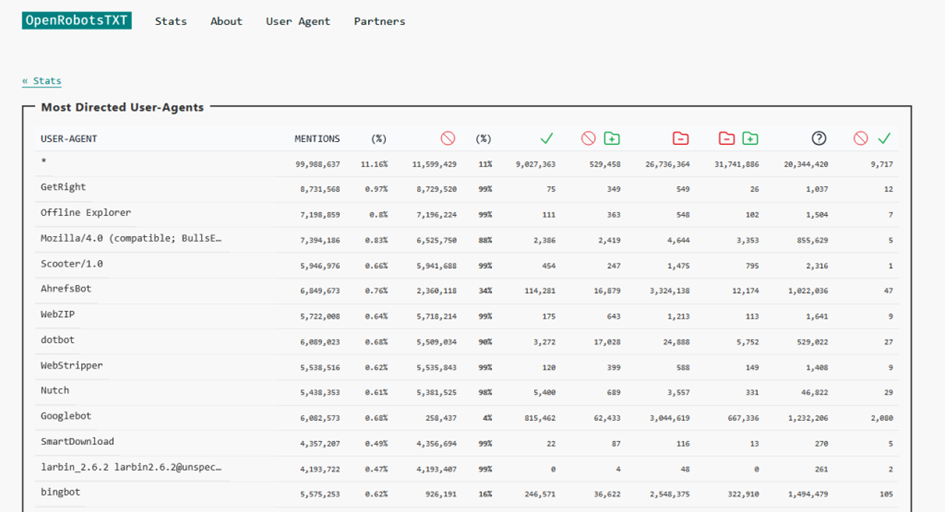
Die angezeigten Spalten sind:
- Erwähnungen (wenn der User-Agent in einer robots.txt-Richtlinie erwähnt wird)
- Erwähnungen in % der Gesamtstudie
- Alle verbieten
- Alle als Prozentsatz der Erwähnungen verbieten
- Erlaubt alle
- Eine Mischung aus allow-Direktiven nach einem expliziten disallow
- Eine Reihe von Verbotszeilen
- Eine Mischung aus verbotenen und erlaubten Zeilen
- Erwähnungen, die keine Auswirkungen auf das Zulassen oder Nichtzulassen haben, wie z. B. Crawl-Verzögerungen
- Konflikte zwischen den Vorschriften (glücklicherweise sind sie relativ gering)
Mit Ausnahme der Prozentzahlen ist die Spalte “Nennungen” die Summe aller Spalten auf der rechten Seite.
Die daraus resultierende Analyse von über 37.000 User-Agents (zum Zeitpunkt der Erstellung dieses Artikels) steht jetzt zum Download bereit. Die Daten liegen im CSV-Format vor und sind daher für Excel und Python geeignet. Um ein Gefühl für die Daten zu bekommen, wird eine kleine Anzahl von zusammenfassenden Tabellen auf der Website präsentiert.
Fazit
Datenstudien sind eine gute Sache. Sie helfen, unsere Branche zu informieren. Ein großes Lob gebührt Xibeijia Guan für diese großartige Analyse.
Dennoch können wir die in Ahrefs Beitrag dargelegten Schlussfolgerungen nicht vollständig akzeptieren. Unsere Einwände und Bedenken beziehen sich nicht auf die Studie, sondern auf die Präsentation der Studie. Es wurde eindeutig viel Arbeit in die Analyse gesteckt, was wir respektieren und bewundern. Wir haben versucht, in unserer Antwort konstruktiv zu sein und nehmen dies zum Anlass, unsere Sichtweise zu den Unterschieden in der Herangehensweise von Ahrefs und OpenRobotsTxt darzulegen.
Wir freuen uns über Ihre Meinung zu OpenRobotsTxt, der Ahrefs-Studie und unserer Antwort.
Viel mehr gibt es hier nicht zu sagen. Wenn Sie an einer robots.txt-Analyse interessiert sind, besuchen Sie bitte OpenRobotsTxt.org
- Wie SEO und SEA effektiver zusammenwirken können - May 6, 2026
- Wie man für den Google AI-Modus optimiert - March 4, 2026
- Erweiterte Filter im gesamten Site Explorer verfügbar - January 29, 2026