






Im Mai haben wir OpenRobotsTXT gestartet, ein Projekt zur Archivierung und Analyse der robots.txt-Dateien weltweit. Wir freuen uns, ein neues Update der Website ankündigen zu können. Sie können jetzt das Archiv nach robots.txt-Dateien einzelner Websites durchsuchen und nach bestimmten Bot-Namen suchen.
Wenn Sie sich für den Projekthintergrund von OpenRobotsTXT interessieren, finden Sie viele Details auf der Seite Über OpenRobotsTXT.
Suche nach der robots.txt-Datei einer Website
Mit Site Search können Sie jetzt robots.txt-Dateien für einzelne Websites durchsuchen. Auf diese Weise können Sie sicherstellen, dass Ihr Server die robots.txt-Datei wie gewünscht bereitstellt.
Der Einstieg ist denkbar einfach. Klicken Sie oben auf der Seite auf den Link Site Search und geben Sie die Domain ein, die Sie überprüfen möchten.
Wenn Sie sich nicht sicher sind, wo Sie anfangen sollen, haben wir eine Starterliste mit Websites hinzugefügt, die wir bei der Entwicklung dieser neuen Funktionen als nützlich empfunden haben.
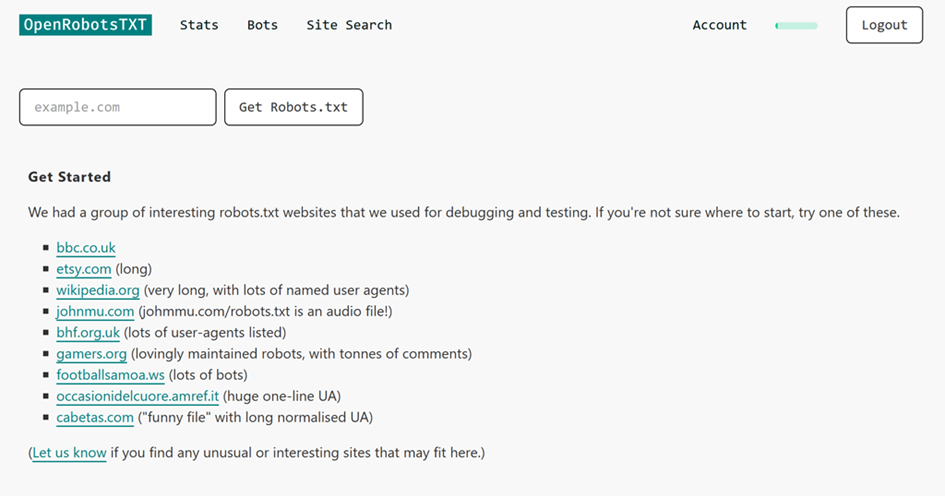
Suche nach Flickr. Wenn wir eine robots.txt-Datei finden, zeigen wir die zuletzt geladene und geparste Datei an, wobei jeder Bot in einen klickbaren Link umgewandelt wird.
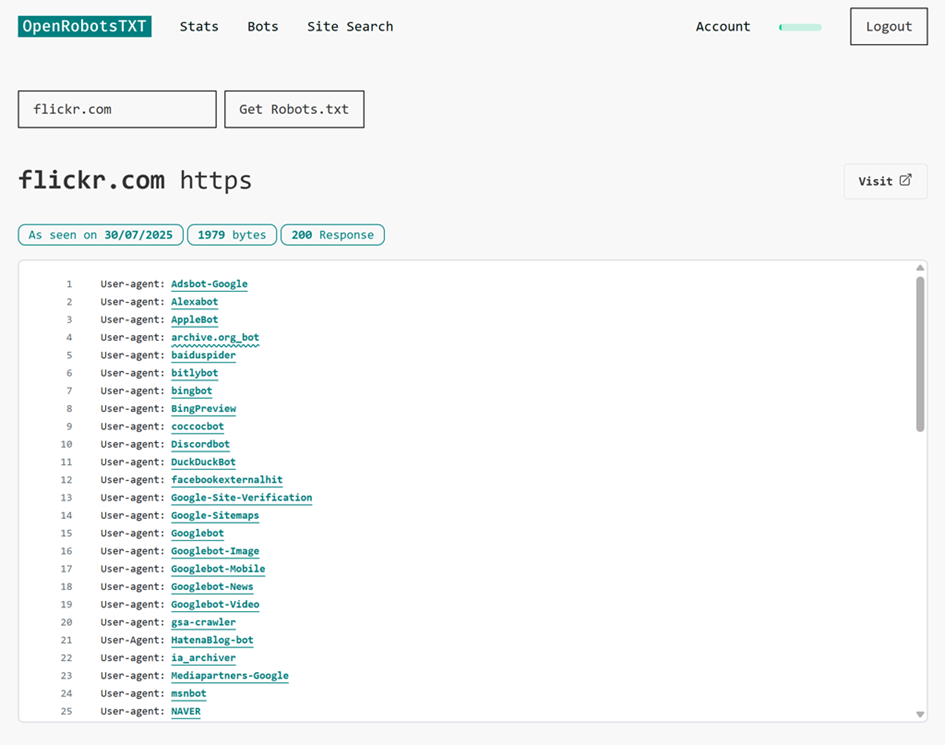
Neben der interpretierten robots.txt-Datei sehen Sie auch das Datum, an dem wir die Datei zuletzt abgerufen haben, die Größe der robots.txt-Datei und die letzte Crawl-Antwort.
Herausfinden, ob eine robots.txt-Datei nicht abgerufen werden konnte
Wenn wir keine robots.txt-Datei abrufen konnten, wird in der Regel eine “404 Response” angezeigt.
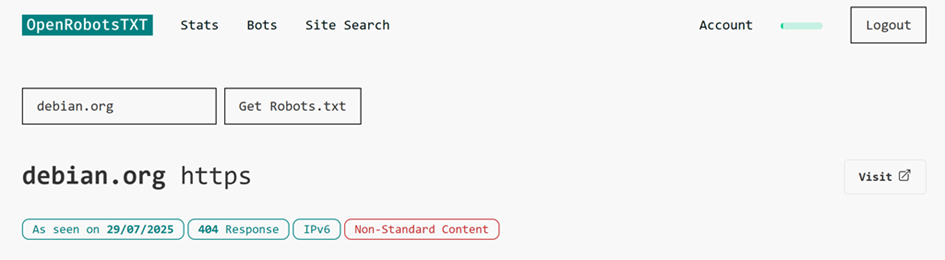
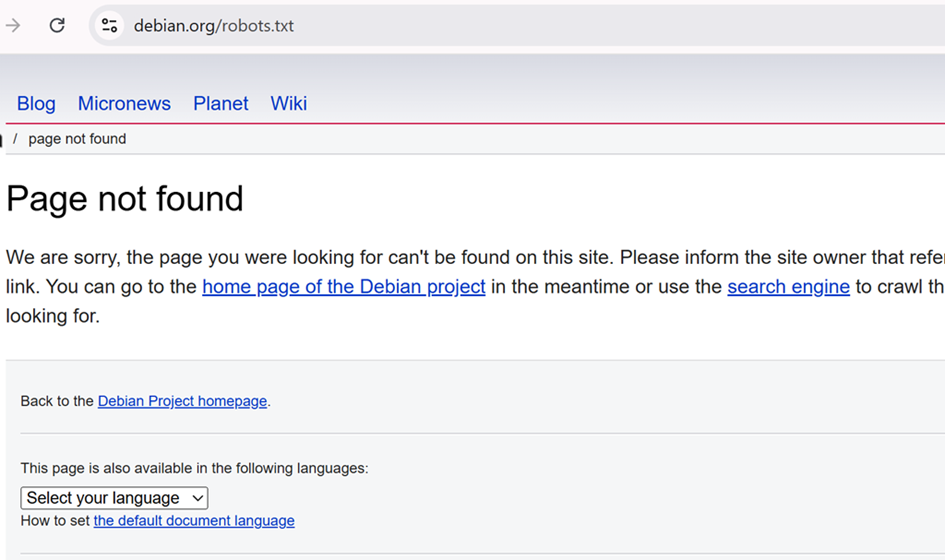
Für diese Suche nach debian.org gibt es einen zusätzlichen Hinweis, dass die Datei “Nicht-Standard-Inhalt” hatte. Diese Markierung ist typisch, wenn die robots.txt-Anfrage einen 404-Fehler erhält, da Websites dazu neigen, alle 404-Fehler an eine Standard-HTML-Seite weiterzuleiten.
Wenn Sie also eine Antwort erhalten, die Sie nicht erwartet haben, können Sie auf die Schaltfläche “Besuchen” auf der rechten Seite klicken, um die robots.txt selbst zu überprüfen. Im Fall von Debian bestätigt ein Klick darauf, dass unter der üblichen URL keine robots.txt-Datei verfügbar ist.
Bot-Namen in robots.txt-Dateien
Der Hauptgrund, warum die meisten Leute robots.txt-Dateien durchsuchen, ist natürlich, dass sie sehen wollen, welche spezifischen Bots enthalten sind. Und genau hier wird es ein wenig interessant.
Denn robots.txt-Dateien werden sehr, sehr selten validiert. Viele Dateien enthalten fehlerhafte Direktiven, falsche User-Agent-Namen oder veraltete Regeln.
Wussten Sie zum Beispiel, dass der RFC 9309: Robots Exclusion Protocol festlegt, dass Crawler-Namen NUR Groß- und Kleinbuchstaben (“a-z” und “A-Z”), Unterstriche (“_”) und Bindestriche (“-“) enthalten dürfen?
Um Crawler-Namen zu erkennen, die nicht diesem Standard entsprechen, haben wir die Benutzer-Agenten-Zeile mit einem wellenförmigen Unterstrich versehen.
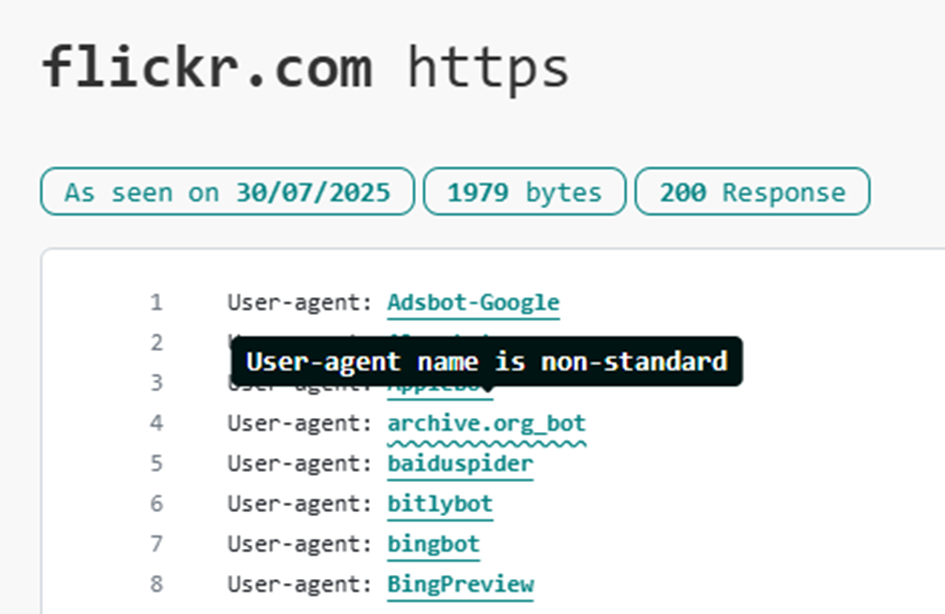
Beachten Sie, dass eine solche Wellenlinie allein noch nicht bedeutet, dass die robots.txt-Datei fehlerhaft ist.
Wenn der Name eines Bots beispielsweise eine Zahl enthält, sollten Sie seinen Vornamen weiterhin verwenden, auch wenn der Name, den er für sich selbst gewählt hat, nicht dem RFC 93009-Standard entspricht. Es gibt viele Crawler, deren Name aus der Zeit vor dem Standard stammt (z. B. MJ12Bot!) oder deren Besitzer nicht wussten, dass der Standard existiert. Die Wellenlinie ist zwar eine praktische Orientierungshilfe, aber wenn Sie nicht genau den Namen verwenden, den der Bot zu sehen erwartet, wird er seine Anweisungen nicht finden.
Die Wellenlinie ist nützlich, wenn es darum geht, fehlerhafte Einträge in der robots.txt-Datei zu erkennen. Nehmen Sie zum Beispiel diese nächste Website.
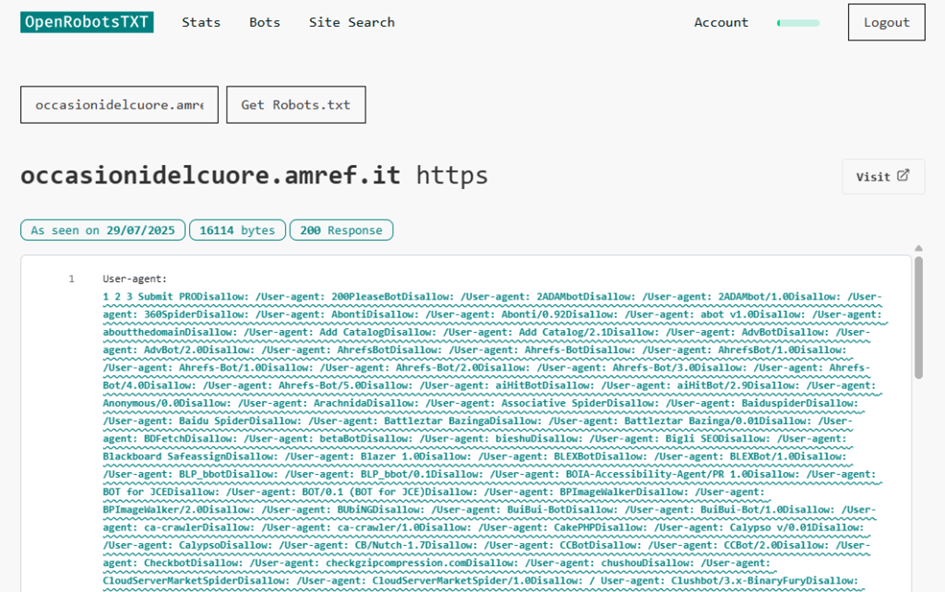
Es sind so viele Crawler aufgeführt, dass man wohl davon ausgehen kann, dass diese robots.txt programmatisch kompiliert und nicht von Hand erstellt wurde. Die Ausgabe enthält jedoch keine Zeilenumbruchzeichen.
Das hat zur Folge, dass die User-Agent-Deklarationen ineinander übergehen. Während ein menschlicher Leser erkennen kann, was der Autor der Website damit bezwecken wollte, könnte ein Crawler dies als einen einzigen großen Bot-Namen interpretieren und nicht erkennen, dass ein kleiner Teil dieser riesigen Zeichenkette auf ihn zutrifft.
Wir haben festgestellt, dass einige Site-Suchen unglaublich interessant sind. Lassen Sie es uns wissen, wenn Sie etwas Ungewöhnliches oder Spannendes finden!
Suche nach einzelnen Bots
Es gibt zwei Möglichkeiten, nach einem Bot zu suchen.
- Sie können auf einen beliebigen User-Agent-Namen in einer robots.txt-Datei klicken, um eine Suche nach diesem individuellen Bot durchzuführen.
- So können Sie direkt zu einem Bot springen, ohne erst eine Site-Suche durchführen zu müssen.
Wenn Sie #2 bevorzugen, haben Sie Glück. Wir haben nicht nur die Site-Suche hinzugefügt, sondern auch die Bot-Suche geöffnet. Sie können jetzt den Link “Bots” oben auf der Seite verwenden, um die wichtigsten Statistiken für interessante Bots abzurufen.
Hier ist ein Beispiel, bei dem wir nach AdsBot-Google gesucht haben.
Dies sind die Statistiken für diesen speziellen Bot.
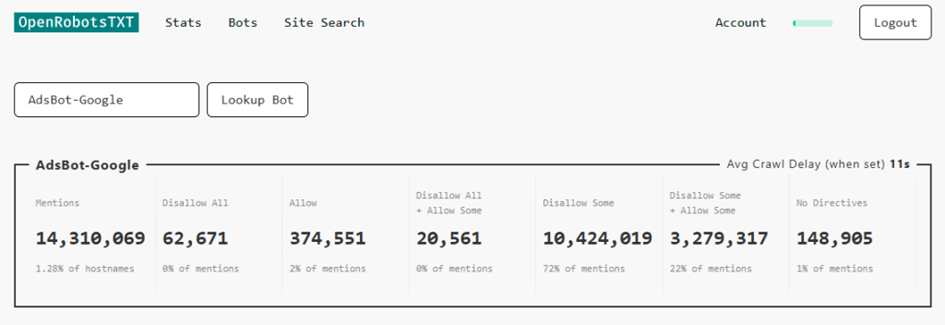
Beachten Sie, dass einige Bot-Namen eine konsolidierte Summe vieler User-Agent-Einträge sind, die fast identische, ähnliche Namen haben.
Hier ist ein Beispiel, bei dem eine Versionsnummer zum Namen des Benutzeragenten hinzugefügt wurde.
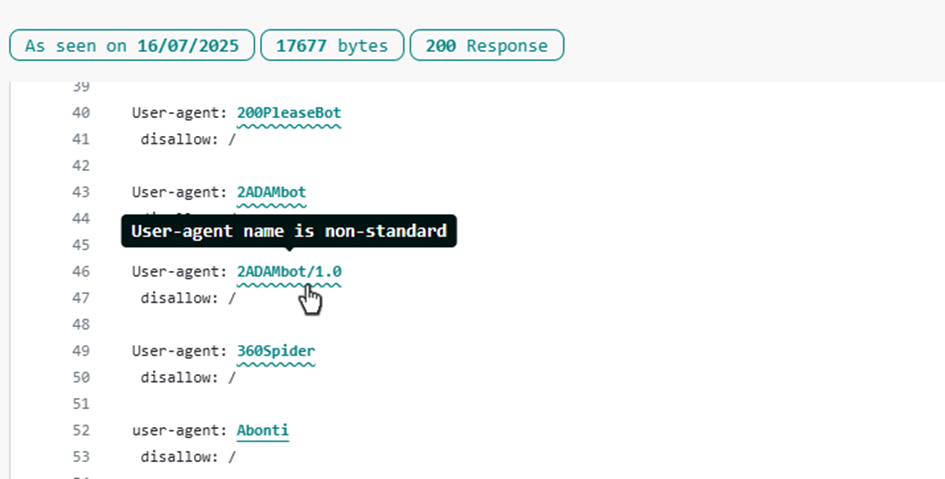
Wenn Sie auf diesen Bot klicken, sehen Sie diesen Bildschirm, der einen Hinweis darauf enthält, dass diese Bot-Zeichenkette in einen übergeordneten Bot-Namen integriert wurde, der keine Versionsnummern enthält.
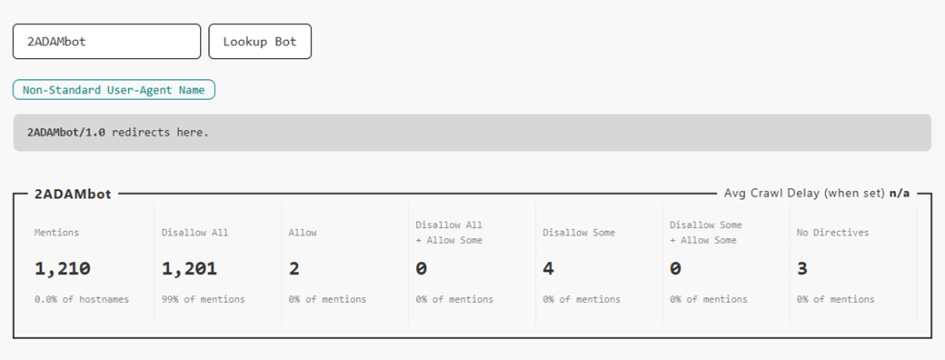
Es sei darauf hingewiesen, dass OpenRobotsTXT zwar erkennt, dass es sich um denselben Bot handelt, dass aber ein einzelner Crawler Richtlinien ignorieren kann, wenn er nicht weiß, dass diese Art von Namensvariante für ihn gilt.
Nachdem Sie nun gesehen haben, wie Sie nach Crawler-Namen suchen können, können Sie hier mit der Suche nach Bots beginnen. Jeder kann nach Bots suchen, es ist kein Konto erforderlich.
Hinweis: Wenn Sie nach vielen Bot-Daten suchen, müssen Sie kein Skript schreiben, um jede Seite zu crawlen. Die Seite “Statistiken” enthält eine CSV-Datei mit allen wichtigen Statistiken für jeden Bot.
Probieren Sie es aus
Wenn Sie bis zum Ende dieses Beitrags gekommen sind, haben Sie hoffentlich Lust, die neue OpenRobotsTXT-Suche auszuprobieren.
Wir haben allerdings eine Bitte. Wenn Sie die robots.txt-Dateien von Websites durchsuchen möchten, bitten wir Sie, sich für ein kostenloses Konto zu registrieren. Dies hilft uns wirklich, übermäßige oder automatisierte Anfragen zu verhindern und einen zuverlässigen Service für alle zu gewährleisten.
Vielen Dank für Ihr Interesse an OpenRobotsTXT. Wir arbeiten noch an Ideen zur Verbesserung des Dienstes und hoffen, dass er auch weiterhin einen guten Einblick in die Welt von robots.txt bietet. Bitte lassen Sie uns wissen, wenn Sie tolle Ideen haben oder sich beteiligen möchten.
- N-Gramme in der Nähe von Links: Identifizieren Sie wiederkehrende Phrasen im Kontext Ihrer Backlinks - May 5, 2026
- TLD Checker – Neu für 2026 - March 3, 2026
- Welcome Hub – Verbesserung des letzten Schrittes Ihres Login-Prozesses - September 18, 2025