






Lo scorso maggio, abbiamo lanciato OpenRobotsTXT, un progetto per archiviare e analizzare i file robots.txt del web. Siamo lieti di annunciare un nuovo aggiornamento. Ora è possibile fare ricerche nell’archivio per i file robots.txt di singoli siti web e cercare nomi di bot specifici.
Per chi fosse interessato al background del progetto OpenRobotsTXT, ci sono molti dettagli nella pagina About OpenRobotsTXT (disponibili anche in italiano qui).
La Ricerca per il file robots.txt di un sito
Con Site Search, ora è possibile cercare i file robots.txt di singoli siti web. La ricerca offre la possibilità di assicurarsi che la configurazione del server fornisca il file robots.txt come previsto.
La ricerca è semplice da effettuare. Basta cliccare sul link Site Search nella parte superiore della pagina e inserire il dominio da controllare.
Se non si è sicuri di dove iniziare, abbiamo aggiunto, durante la costruzione di queste nuove funzioni, un elenco di siti che abbiamo individuato e che pensiamo possano essere utili.
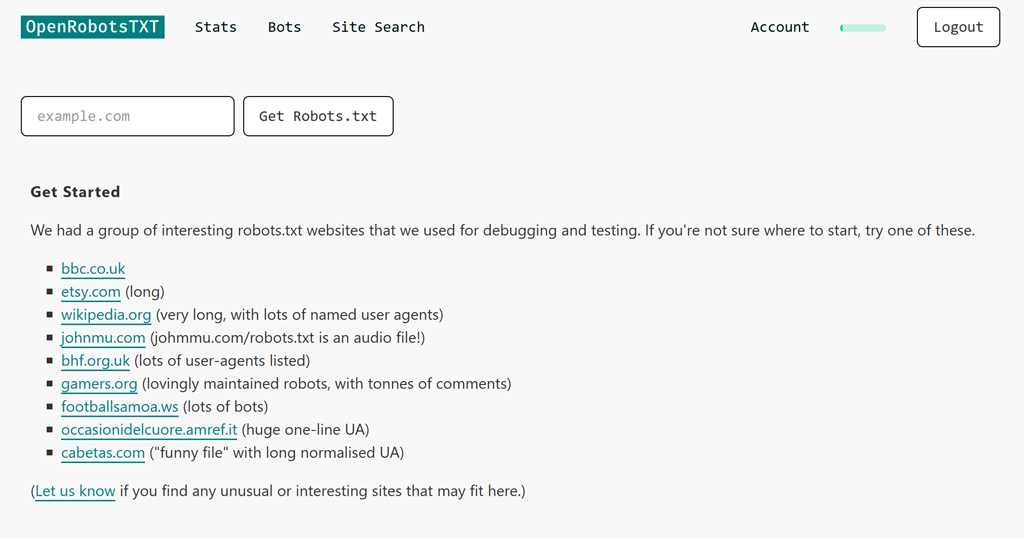
A titolo esemplificativo abbiamo analizzato il risultato di una ricerca per Flickr. Quando troviamo un file robots.txt, mostriamo quello più recente, caricato e analizzato, con ogni bot convertito in un link cliccabile.
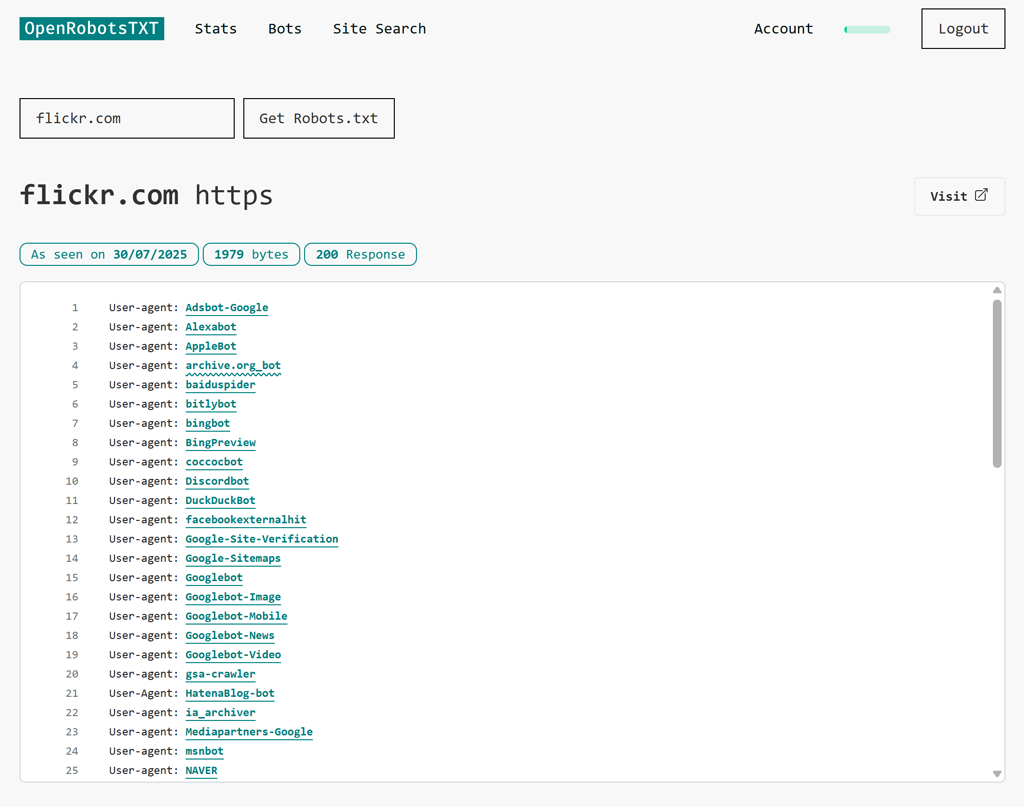
Oltre al file robots.txt interpretato, si vedrà la data in cui il file è stato scaricato l’ultima volta, la dimensione del file robots.txt e la risposta di crawl più recente.
Verifica se non siamo riusciti a recuperare un file robots.txt
Se non siamo riusciti a recuperare un file robots.txt, si vedrà tipicamente una “Risposta 404”.
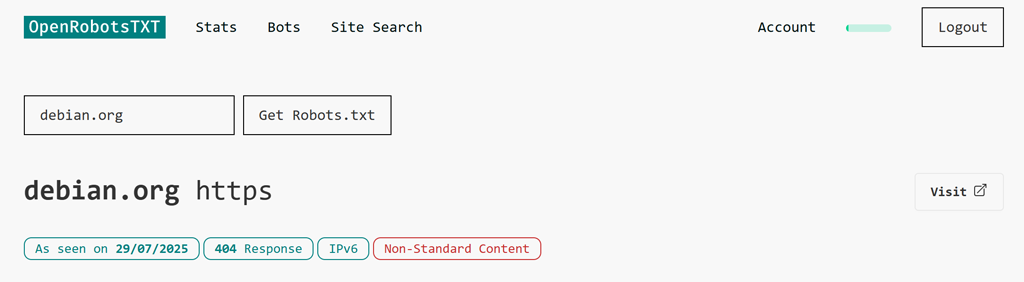
Per questa ricerca di debian.org, c’è una nota aggiuntiva che il file aveva “Contenuto Non Standard”. Questo flag è tipico quando la richiesta robots.txt riceve un errore 404, poiché i siti tendono a inoltrare tutti i 404 a una pagina HTML standard.
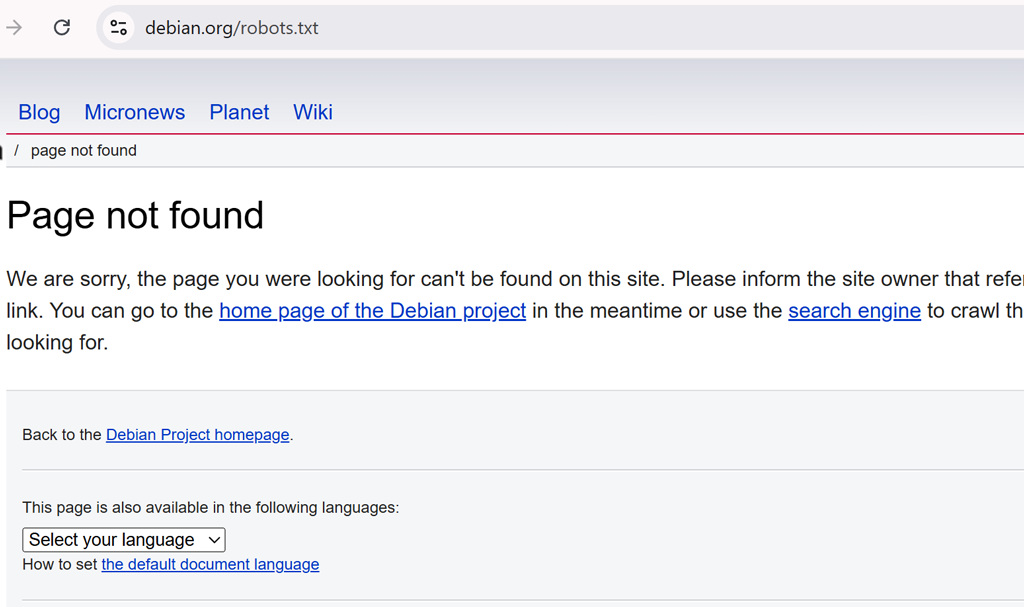
Alcuni siti web presentano dati diversi ai crawler rispetto ai visitatori normali, quindi se si riceve una risposta inaspettata, è possibile premere il pulsante “Visita” sul lato destro per controllare manualmente il robots.txt. Nel caso di Debian, cliccando si conferma che non c’è alcun file robots.txt disponibile all’URL abituale.
Nomi bot nei file Robots.txt
Naturalmente, il motivo principale per cui la maggior parte delle persone effettuano ricerche per i file robots.txt è per vedere quali bot specifici sono inclusi. Ed è qui che le cose si fanno più interessanti.
I file robots.txt sono molto, molto raramente validati. Quindi molti file hanno direttive malformate, nomi user-agent incorretti o regole obsolete.
Ad esempio, non tutti sanno che l’RFC 9309: Robots Exclusion Protocol specifica che i nomi dei crawler DEVONO AVERE SOLO lettere maiuscole e minuscole (“a-z” e “A-Z”), underscore (“_”) e trattini (“-“).
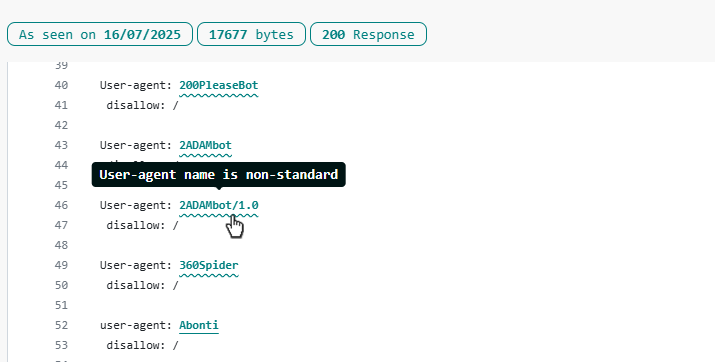
Per aiutare a identificare i nomi dei crawler che non sono conformi a questo standard, abbiamo aggiunto una sottolineatura ondulata alla riga user-agent.
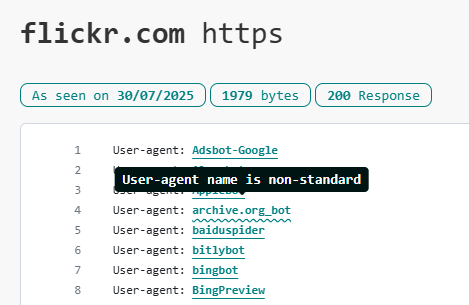
Si deve considerare che questo tipo di linea ondulata da sola non significa che il file robots.txt sia errato.
Ad esempio, se il nome di un bot ha un numero, si dovrebbe continuare a usare il nome dato, anche se il nome che è stato scelto non corrisponde allo standard RFC 93009. Ci sono molti crawler il cui nome precede lo standard (ad esempio MJ12Bot!), e casi in cui i webmaster non erano a conoscenza dello standard. Mentre la linea ondulata è un’indicazione utile, se non si usa il nome esatto che il bot si aspetta di vedere, il bot non troverà le sue istruzioni.
Dove la linea ondulata DIVENTA utile è nell’individuare voci malformate nel file robots.txt. Prendiamo questo prossimo sito, ad esempio.
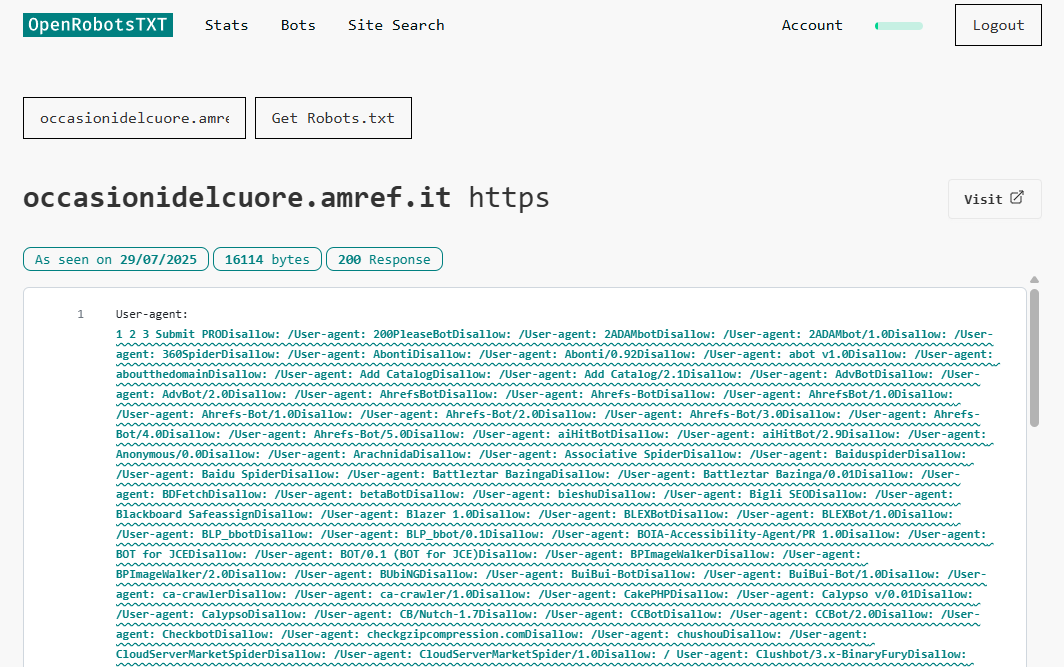
Ci sono così tanti crawler elencati che è probabilmente sicuro presumere che questo robots.txt sia compilato programmaticamente, piuttosto che fatto a mano. Tuttavia, l’output non include caratteri di interruzione di riga.
Di conseguenza, le dichiarazioni user-agent si fondono tutte insieme. Mentre una persona può vedere cosa stava cercando di fare l’autore del sito, un crawler potrebbe decidere di interpretarlo come un enorme nome bot e potrebbe non rendersi conto che una piccola parte di questa enorme stringa si applica a loro.
Abbiamo trovato alcune ricerche di siti incredibilmente interessanti. Fateci sapere se trovate qualcosa di insolitamente interessante!
Cerca bot individuali
Ci sono due modi per cercare un bot.
- Si può cliccare su qualsiasi user-agent in un file robots.txt per eseguire una ricerca per quel bot specifico.
- Andare direttamente a un bot senza dover prima fare una ricerca del sito.
Quelli che preferiscono l’opzione #2 sono fortunati. Oltre ad aver aggiunto la ricerca per siti, abbiamo anche aperto alla ricerca per bot. Ora è possibile utilizzare il link “Bots” nella parte superiore della pagina per cercare statistiche di alto livello per bot interessanti.
Ecco un esempio dove abbiamo cercato AdsBot-Google.
Queste sono le statistiche per quel particolare bot.
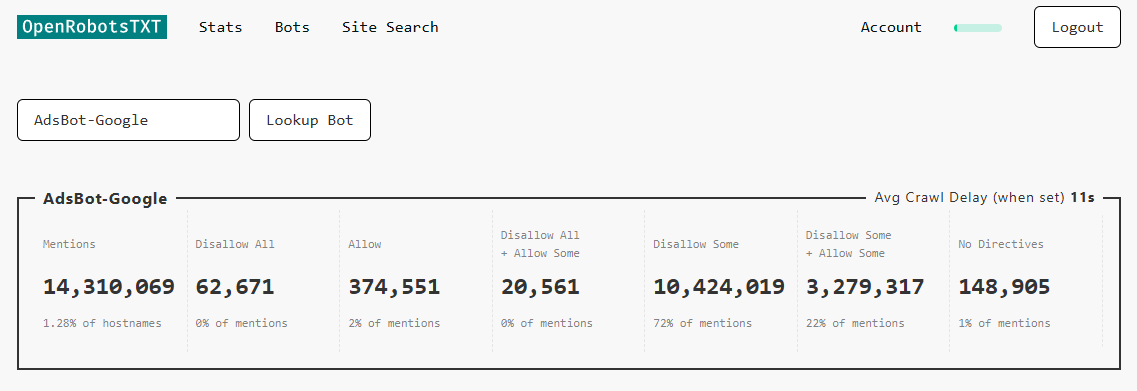
È importante tenere presente che alcuni nomi di bot sono un totale consolidato di molte voci user-agent che hanno nomi quasi identici.
Ecco un esempio, dove è stato aggiunto un numero di versione al nome user-agent.
Cliccando per vedere quel bot, si vedrà questa schermata, contenente un’indicazione che questa stringa di bot è stata raggruppata sotto un nome di bot principale che non include numeri di versione.
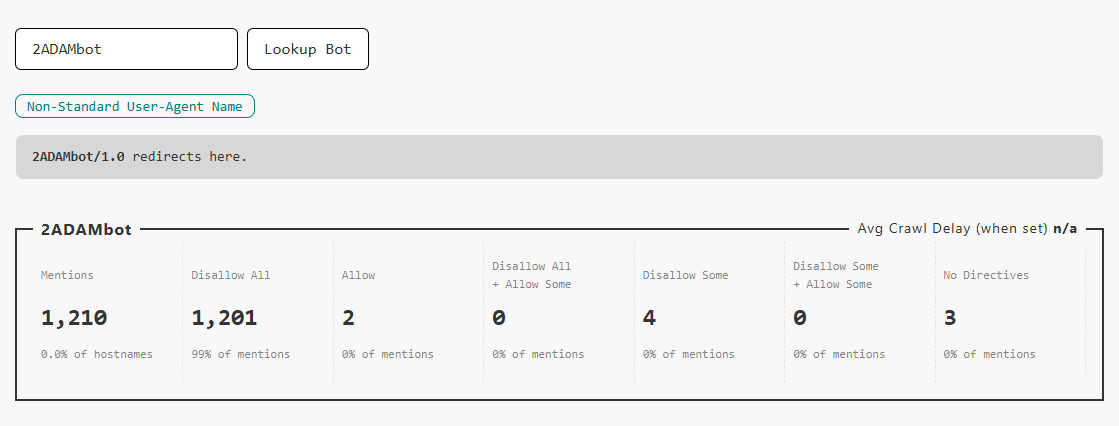
Vale la pena notare che mentre OpenRobotsTXT riconosce questi come lo stesso bot, un singolo crawler potrebbe ignorare le direttive dove non si rende conto che questo tipo di variante del nome si applica a se stesso.
Ora che si è visto come cercare nomi di crawler, è possibile cercare bot qui. Chiunque può cercare bot, non è necessario accedere con un account.
Nota: Se si cercano molti dati sui bot, non è necessario scrivere uno script per fare crawling di ogni pagina. La pagina Statistiche contiene un CSV con tutte le statistiche di alto livello per ogni bot.
Fai una Prova
Siamo fiduciosi che i lettori che sono arrivati fin qui siano interessati a provare la nuova ricerca di OpenRobotsTXT.
Per voi, abbiamo una richiesta. Se l’esigenza è effettuare delle ricerche per i file robots.txt dei siti, chiediamo gentilmente di effettuare la registrazione per un account gratuito. Questo ci aiuta davvero a prevenire richieste eccessive o automatizzate, garantendo un servizio affidabile per tutti.
Grazie per l’interesse in OpenRobotsTXT. Stiamo ancora lavorando su idee per migliorare il servizio, e speriamo che continui a fornire ottimi insight nel mondo dei robots.txt. Fateci sapere se avete idee innovative o vorreste essere coinvolti.
- N-grams Near Links: Un’analisi delle frasi ricorrenti nel contesto dei backlink - May 8, 2026
- Novità 2026 – Il TLD Checker - March 9, 2026
- Novità: Site Search e Bot Lookup per OpenRobotsTXT - August 29, 2025