






Come installare python e scaricare un sito web
Eccoci alla terza parte di imparare Python per il SEO. In questo articolo ti facciamo vedere come installare e operare con Python con il tuo computer. Questa parte del corso utilizza i concetti illustrati nelle lezioni precedenti su Python e la programmazione in cloud. Anche se hai già letto le prime due parti di questa serie sul Python per il SEO, è bene tenere a portata di mano quei due articoli che ti potrebbero essere utili nell’affrontare questa terza parte. Ecco i link alle due lezioni precedenti:
In questa lezione su Python per il SEO imparerai come installare Python sul tuo computer e scaricare il tuo prmo sito web. Utilizziamo un IDE locale per scaricare dal web pagine web e siti interi (IDE è acronimo di Integrated Development Environment – Ambiente di Sviluppo Integrato).
Perché Python per il desktop?
Possiamo utilizzare Python da diversi device e piattaforme. La scelta caratterizza e condiziona le funzionalità. Se sviluppi programmi in locale (sul tuo computer) questi possono essere eseguiti anche altrove. Puoi scrivere programmi in locale per poi essere eseguiti in cloud sui tuoi server o VPS (Virtual Private Server). Il tuo computer è solo il punto di partenza per creare una “cassetta degli attrezzi” per automatizzare le tue attività di SEO.
Nell’ultima lezione (Python per il SEO -2) abbiamo esaminato interpreti online di Python come repl.it e onlinegdb.com. Abbiamo visto come si costruiscono funzioni e loop con Python e come utilizzare moduli di terze parti.
In questa lezione, sfruttiamo le nozioni acquisite per scrivere programmi in Python sul tuo computer utilizzando un IDE. Gli IDE sono strumenti che aiutano i programmatori a scrivere programmi e spesso ne permette anche l’esecuzione. Esistono molti ambienti di sviluppo per Python. Quello che abbiamo deciso di presentarti si chiama PyCharm, creato da JetBrains – azienda famosa tra gli sviluppatori, nota per la qualità dei suoi prodotti per sviluppare software.
La buona notizia è che JetBrains mette a disposizione della comunitàdi sviluppatori una versione gratuita di PyCharm.
Sempre in questa lezione, impostiamo il tuo primo progetto, ripetendo gli esercizi sviluppati nella lezione precedente, utilizzando PyCharm. L’uso di un IDE come PyCharm aiuta a programmare con maggiore efficienza, offrendo informazioni utili e suggerimenti.
L’Intallazione di python
Se non lo conosci già, Python è un linguaggio di programmazione con un numero enorme di utilizzatori nel mondo. L’installazione di Python richiede una certa attenzione e, come minimo, esperienza nella installazione e configurazione di software e del sistema operativo su operi regolarmente (che potrebbe essere Windows, OSX, Linux). Se operi in azienda e l’hardware è aziendale, è bene fare riferimento al personale tecnico e richiederne l’installazione. Se vuoi procedere con l’installazione sul tuo computer è buona prassi fare un backup completo del tuo sistema prima di procedere con l’installazione.
La nostra guida spiega come procedere con l’installazione di python su computer con sistema operativo Windows, sulla base della nostra esperienza in azienda. La procedura può essere adottata anche per gli altri sistemi operativi, con piccoli aggiustamenti.
La prima cosa da fare è verificare se python è già installato sul tuo computer. Per eseguire la verifica devi aprire una finestra di terminale ed eseguire il comando
python --version
Se python è installato, il comando restituisce a video la versione di python installata sul computer


Se Python è già installato puoi proseguire per l’installazione di PyCharm.
Se Python non è installato non ti devi preoccupare, il download è gratuito ed è disponibile sul sito python.org.
Per installare Python basta visitare la pagina la stessa pagina del paragrafo precedente. Trovi informazioni sulle versioni e link a tutorial. Scegliendo una piattaforma e versione del linguaggio di programmazione
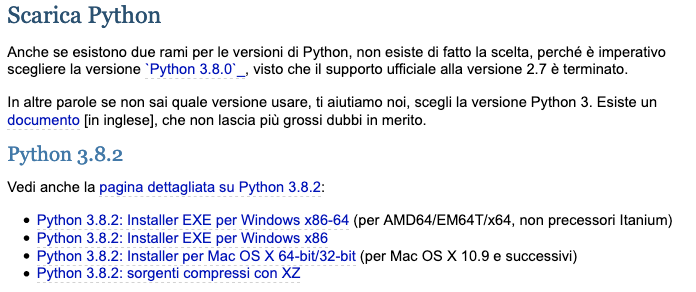
Come per moltissimi altri applicativi software, devi scaricare un installer – nel nostro caso il link punta al file per installare la versione più recente di Python per Windows, Mac OS, e Linux. Scaricato il pacchetto, si procede con l’installazione con il solito doppio-click. Le versioni disponibili sono sia a 32 bit che a 64 bit. Per il resto il processo di installazione è piuttosto semplice ed è quello a cui siamo già abituati. Tutt’al più si può chiedere di aggiungere Python 3.8 al path di sistema – dopodiché si clicca su “Installa ora” per avviare l’installazione.
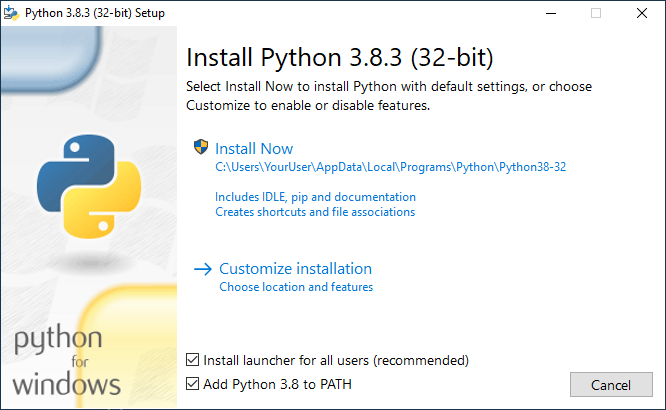
Per controllare che Python è stato installato correttamente puoi ripetere la verifica python --version da terminale di Windows e verificare che la risposta sia la versione di python appena installata.
Scarica e Installa PyCharm
Fin qui abbiamo parlato di PyCharm prodotto da JetBrains come l’IDE di nostra scelta.
PyCharm è disponibile per il download dal sito di JetBrains all’indirizzo https://www.jetbrains.com/pycharm/. Il link porta alla pagina di download.

All’utente viene presentata l’opzione di scegliere tra la versione professionale (a pagamento) oppure quella community (che è gratuita) – vedi screenshot che segue.
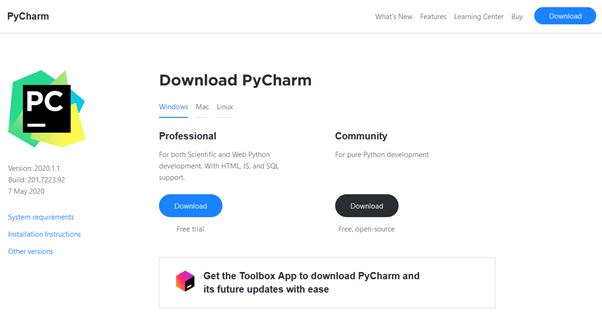
La versione professionale di PyCharm è un prodotto di qualità. La versione Professional è indicata per se si fa molto sviluppo di codice Python. Per muovere i primi passi ed imparare ad utilizzare Python l’edizione community è sufficiente ed è questa che prendiamo in esame nel proseguio della lezione.
Scaricato il file, PyCharm va poi installato.
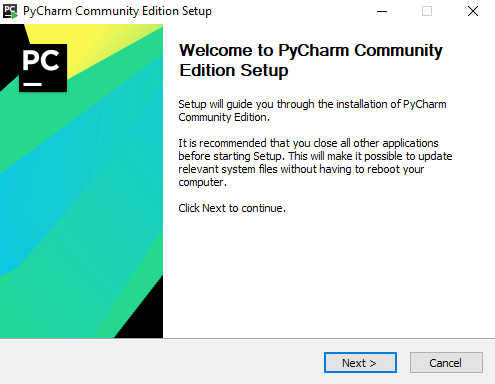
Anche per PyCharm puoi decidere dove l’installazione deve avvenire. Puoi cambiare la directory predefinita oppure cliccare su next per proseguire.
Per le opzioni di installazione più tecniche ti consigliamo di creare le associazioni suggerite dal setup. Questo significa ad esempio che aprendo un file di Python, che ha estensione .py, questo verrà aperto con PyCharm.
La schermata finale permette anche di modificare la posizione nel menu di avvio di Windows.
Una volta conclusa la procedura, l’installazione si conclude con una finestra di dialogo ed alcune opzioni. Puoi attivare l’applicativo immediatamente selezionando l’opzione “Run PyCharm Community Edition”, quindi “Finish”. Si attiva il software e l’utente deve confrontarsi con una nuova procedura di setup e configurazione di PyCharm, questa volta per adattare l’interfaccia del software alle tue esigenze.
Devi accettare la privacy policy ed altre condizioni d’uso che potranno essere indicate
C’è poi la richiesta di condividere dati statistici anonimi sull’uso del prodotto e bisogna indicare se si ha l’intenzione di condividere oppure no questi dati.
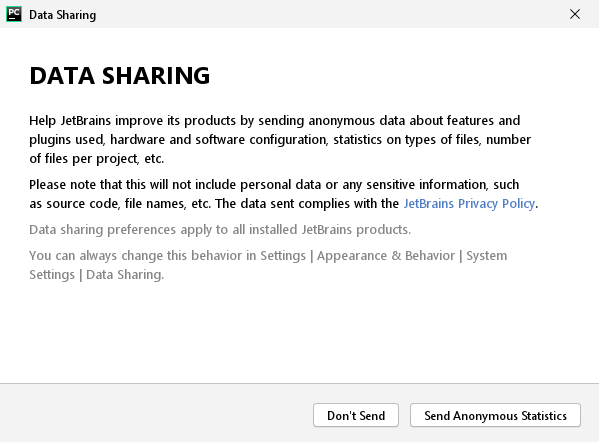
A questo punto PyCharm potrebbe chiederti se hai una configurazione che vuoi importare. Se è la prima volta che usi PyCharm questo passaggio va saltato scegliendo “Do not import settings”
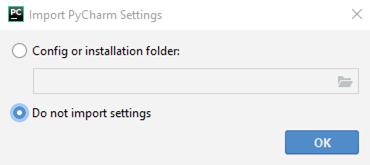
Adesso devi scegliere l’aspetto di PyCharm. Sono disponibili alcuni temi grafici tra cui scegliere – scegli e procedi nell’installazione cliccando su “Next: Featured Plugins”
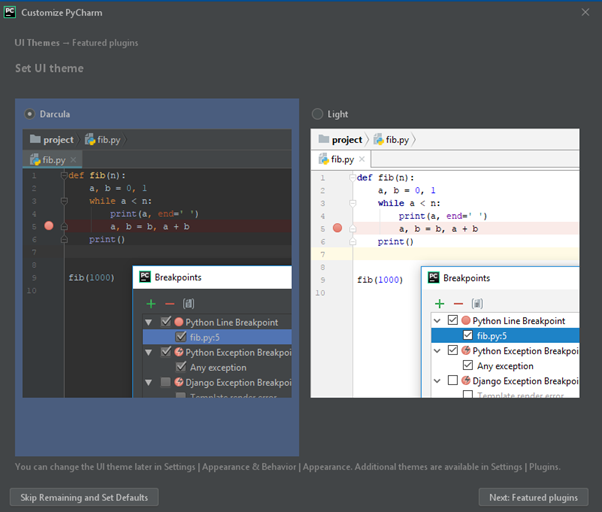
Una volta scelto il tema, PyCharm suggerisce alcune funzionalità aggiuntive sotto forma di plugin (simili a quelli di WordPress). Puoi cliccare su “Start using PyCharm” per saltare questa ultima fase di configurazione.
La fase di pre-lancio di PyCharm è terminata! Una volta partito il programma, siamo pronti per creare un nuovo progetto e cominciare a programmare.

Hello World con PyCharm
Adesso hai capito il motivo per cui abbiamo deciso di utilizzare un interprete online per le prime due lezioni. C’è parecchio lavoro da fare per installare e configurare Python e PyCharm su un computer rispetto alla soluzione cloud.
Il lavoro investito nel setup fin qui è ben speso. Dobbiamo fare ancora un piccolo sforzo perché rimangono alcune cose da fare. I dati in PyCharm sono organizzati in “progetti”. Quindi, per creare il nostro primo programma “Hello World” dobbiamo creare un progetto che lo contenga.
Crea il tuo primo progetto con PyCharm
Adesso abbiamo installato PyCharm – dobbiamo creare un progetto per il nostro programma “Hello World”. Per creare un progetto clicca su “Create New Project”.

La prossima schermata può rivelarsi più o meno complessa. Dipende dalla tua esperienza di programmatore. Se sei completamente nuovo alla programmazione è un momento difficile e ce ne rendiamo conto. Tutto questo potrebbe sembrarti troppo complicato per te che non ne capisci niente di queste cose. Ma non ti devi preoccupare, vedrai che diventa più facile con l’andare del tempo.
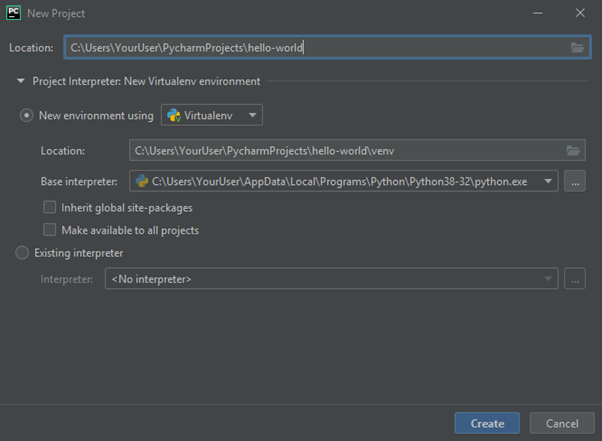
Questa schermata di PyCharm chiede di indicare la directory del tuo progetto. Viene proposta una cartella standard “PyCharmProjects” nell’albero delle cartelle dell’utente del computer. È una collocazione intuitiva e ragionevole che può essere personalizzata in funzione delle tue necessità e abitudini. Scegliamo il nome “hello-world” per il nostro primo progetto.
Adesso bisogna decidere sull’ambiente. Lo standard di PyCharm è la scelta di “New environment using” con l’opzione “Virtualenv”. Location e base interpreter si basano sull’installazione di Python.
Per quelli di voi a cui interessano i dettagli tecnici, il virtualenv è uno strumento che si utilizza per mimimizzare interferenze tra i vari progetti che si sviluppano con PyCharm. Abbiamo parlato di moduli nella lezione precedente. Quando s’installano dei moduli sul proprio computer, questi vengono installati globalmente. Con la presenza di progetti multipli, diverse versioni dello stesso modulo potrebbero creare dei conflitti. Ad esempio si potrebbe disinstallare un modulo che è utilizzato per errore. Per ulteriori informazioni su ambienti virtuali puoi consultare la documentazione disponibile a questo link.
Una volta scelto il nome del progetto e l’ambiente clicca su “Create”.
PyCharm cambia finestra di dialogo e mostra l’ambiente di programmazione. Ma prima, c’è una ulteriore finestra (vedi screenshot che segue). Molti software JetBrains mostrano il suggerimento del giorno. Come anticipa il nome offre un suggerimento diverso ad ogni avvio dell’applicativo. I suggerimenti sono spesso utili per chi utilizza il tool per la prima volta. Noi ti suggeriamo di non disattivare – almeno per il momento. Se li trivi fastidiosi, i suggerimenti si eliminano attivando l’opzione “Don’t show tips”.
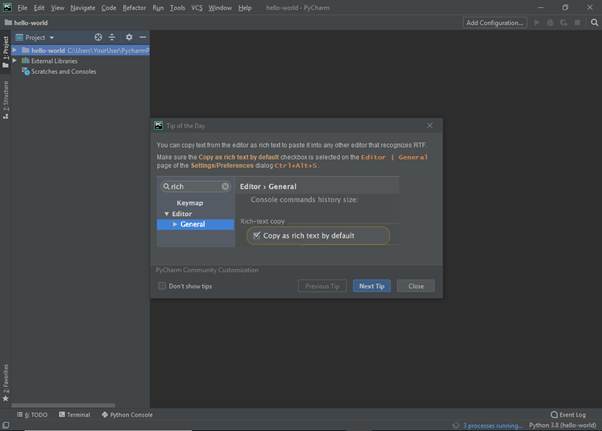
Una volta che hai letto il suggerimento, chiudi la finestra di dialogo. A questo punto puoi partire con il tuo primo progetto.
Con il tasto destro del mouse, clicca per aprire il menu contestuale e poi scegli New >> Python File.
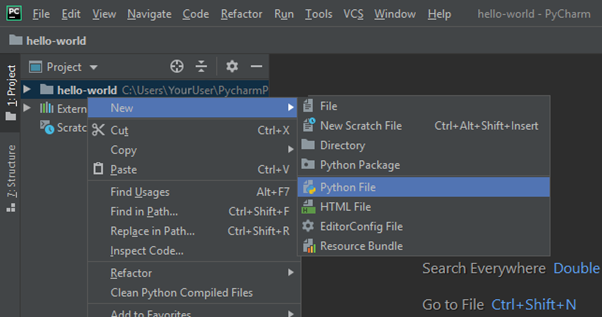
Diamo il nome “hello-world” al file. Queste opzioni, come suggerito dal nome, crea un nuovo file che si chiama , appunto “hello-world” nel tuo progetto.
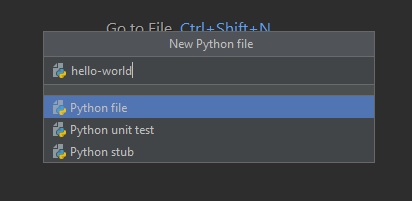
Il file Python appena creato si apre come si può vedere dalla screenshot qui sotto. Il file è la finestra colorata di verde – si vede anche il nome del file (hello-world.py). Nota come PyCharm ha aggiunto il suffisso .py in automatico. Questo perché al momento della sua definizione abbiamo indicato che il file da creare è di Python.
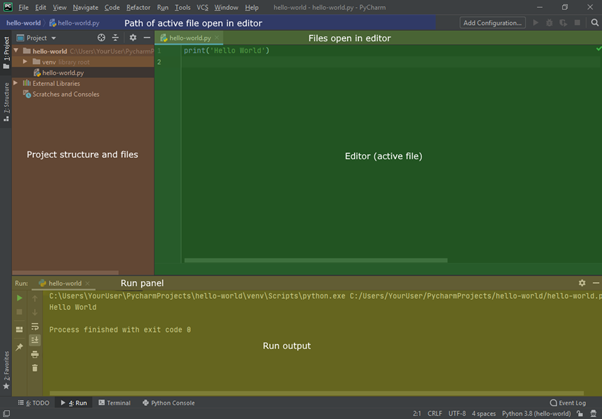
Poiché non abbiamo eseguito un programma finora, la finestra di dialogo degli output non è ancora visibile. Questi ci serviranno a breve. Sulla sinistra l’area colorata in marrone è riservata alla struttura del progetto, le cartelle ed i files. È qui che abbiamo creato il nostro primo file “hello-world” nello step precedente.
Sulla sinistra c’è l’area riservata ai file e all’editing. Qui sono disponibili i files cliccando sul tab in alto. La finestra attiva è quella che può essere modificata. Per cambiare file basta cliccare su un altro tab. In questa screenshot è già presente il codice che stiamo per vedere al prossimo step.
Da notare l’area in blu in alto sulla screenshot che identifica il percorso assoluto del file attivo nella finestra verde.
Nel file Python appena creato inserisci l’istruzione di stampa “Hello World”
print('Hello World')
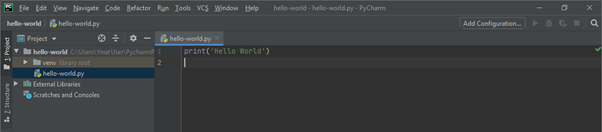
Per poter eseguire il programma bisogna indicare il file. PyCharm non sa quale file va eseguito. Nei programmi più complessi ci sono molti file in un progetto. Se non si offrono istruzioni precise il programma non verrà eseguito.
Per eseguire un programma in PyCharm puoi cliccare su “Run” nel menu principale (Alt+Shift+F10)
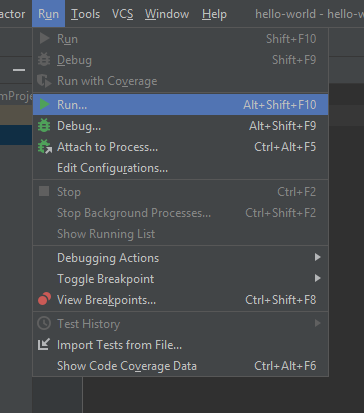
Alla nostra richiesta di eseguire un programma, PyCharm ci chiede quale file deve essere eseguito come si può vedere nella prossima screenshot. La prima opzione, “Edit Configurations”, si utilizzata per configurare diversi profili per eseguire files modificando le variabili di ambiente, interprete e altro ma, al momento questa opzione non ci occorre . Invece, scegliamo il nostro file “hello-world” e PyCharm effettua la configurazione per eseguire il file immediatamente.
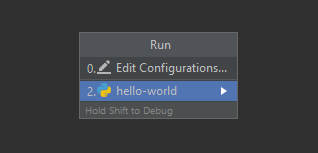
In modo del tutto analogo a quello che è successo quando abbiamo eseguito lo stesso file nel cloud, l’esito della procedura viene mostrato nella finestra inferiore dello schermo.
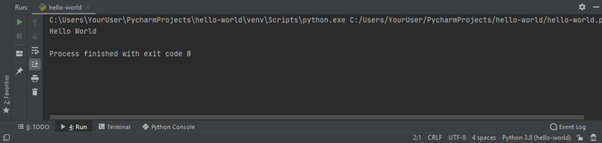
Se il file è eseguito correttamente, a video viene stampato “Hello World”. Abbiamo così scritto il nostro primo programma con PyCharm.
Così facendo, hai aggiunto una configurazione per eseguire il programma con queste istruzioni. La configurazione rende l’esecuzione del file più facile in futuro. PyCharm mostra un triangolo verde in alto a destra simile agli interpreti utilizzati in precedenza. Cliccando il tasto (oppure da tastiera shift + F10) eseguirà il programma senza dover navigare i menu per individuare il file.
Apposto! Adesso se vuoi fare esercizio, riprendi quanto abbiamo fatto nelle due lezioni precedenti. Quando hai fatto gli esercizi e ti senti pronto, puoi passare alla prossima fase – il download di una pagina web.
Scaricare una pagina web
In questa sezione utilizziamo Python e PyCharm per effettuare il download di una pagina web – una procedura tutto sommato abbastanza semplice e allo stesso tempo molto utile. Qualsiasi attività SEO prevede l’analisi dei contenuti di una pagina web.
Premettiamo che nel codice esemplificativo utilizzato non prevede la verifica e implementazione delle direttive del file robots.txt. Un programma che viene messo in produzione dovrebbe obbedire alle istruzioni ivi contenute.
Nella seconda parte di questo tutorial abbiamo fatto il parsing di una pagina di esempio con il modulo BeautifulSoup4. Oggi utilizziamo un modulo chiamato “Requests” per scaricare pagine web. Requests è una libreria per la formulazione di richieste HTTP (per scaricare le pagine di un sito) per gestire tutti gli aspetti tecnici che normalmente vengono gestiti da un browser.
Se ti ricordi, nella seconda parte di questo tutorial abbiamo avuto qualche difficoltà nell’installazione di moduli esterni in repl.it. Con PyCharm, l’uso di modulo di terze parti è molto più semplice,
Anziché cominciare dall’installazione del modulo così come abbiamo dovuto fare in repl.it, possiamo optare per un approccio diretto con la scrittura del codice, lasciano all’IDE (PyCharm) tutto il resto – vediamo come.
import requests
response = requests.get('https://example.com')
print(response.text)Analizziamo la procedure che viene eseguita dal questo codice. Prima di tutto facciamo l’importazione del modulo “requests” per poi invocare il metodo get, che effettua il download dei contenuti della URL designata. La linea print(response.text) stampa la stringa a video così come abbiamo fatto per l’esempio assai più semplice “Hello World”.
Dal momento che non abbiamo ancora scaricato e configurato la libreria Requests, PyCharm segnala un problema nel codice – la parola requests è sottolineata in rosso e sulla destra della schermata è posizionato un marcatore rosso come si vede in questa screenshot:

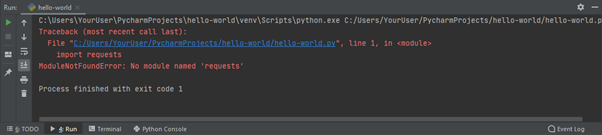
PyCharm non solo segnala il problema nel codice, ma fornisce anche un errore se il codice viene eseguito:
ModuleNotFoundError: No module named 'requests'
PyCharm tenta di aiutarci a risolvere il problema senza intromettersi. Se ci si posiziona con il cursore del mouse su requests, si apre un menu contestuale con il messaggio “No module named requests”. PyCharm segnala l’errore e suggerisce anche come risolverlo proponendo l’installazione del modulo che può essere eseguita cliccando sul link, oppure con la sequenza dei tasti Alt+Shift+Enter

Sovente, si verifica il caso che PyCharm non offre la soluzione mostrata nell’esempio precedente. A volte è necessario ravviare PyCharm oppure salvare di nuovo il file (dal momento che è una installazione nuova).
Accettando la soluzione proposta da PyCharm “install package requests” l’IDE procede con il tentativo di installazione del modulo. Si avvia la procedura automatizzata visibile con diversi messaggi di aggiornamento nella parte inferiore della finestra di dialogo dell’applicativo. Nel giro di pochi secondi dovrebbe apparire un messaggio di conferma dell’installazione.

Avendo installato il modulo, la sottolineatura in rosso scompare ed è possibile eseguire lo script cliccando sul tasto Play in alto a destra oppure da tastiera con la sequenza Shift+F10.
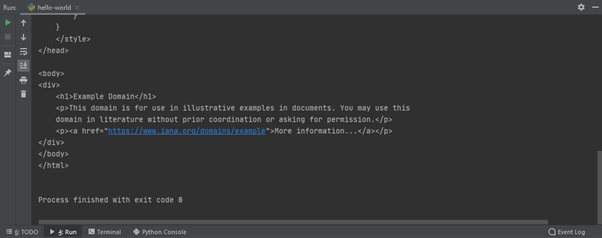
Se tutto procede per il verso giusto, ovvero se il codice è stato eseguito senza errori da PyCharm e la sequenza di download è riuscita, dovresti vedere nella finestra di dialogo di output il contenuto HTML della pagina esemplificativa che abbiamo creata per questo esercizio (example.com).
BeautifulSoup4 per fare ilparsing di una pagina web
C’è una differenza sostanziale tra fare il download di una pagina e farci qualcosa di utile. Il modulo BeautifulSoup4 serve proprio a questo: individuare ed estrarre dati che interessano da una pagina web.
Ma prima di iniziare, val la pena di ricordare che grande potere implica grande responsabilità. Noi ci occuperemo di accedere a siti web per scaricarne le pagine ed analizzare i dati per migliorare le nostre attività SEO. Tuttavia va ricordato che gli esempi che faremo sono tutt’altro che pronti all’uso e da mettere in produzione. Strumenti SEO come DeepCrawl e ScreamingFrog sono il risultato di anni di ricerca, sviluppo e comprensione del web. Ed è altamente improbabile che un entusiasta del web alle prime armi con il Python possa avvicinarsi in alcun modo a questi applicativi software per la SEO.
Possiamo avventurarci in questa esplorazione delle funzionalità di Python utilizzando il codice che abbiamo scritto poco fa. Per analizzare con maggior dettaglio il contenuto occorre utilizzare BeautifulSoup4 di cui abbiamo appena parlato.
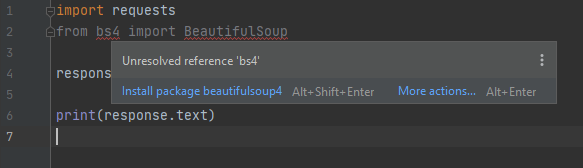
Per utilizzare questo modulo è necessario aggiungerlo con la riga di comando from bs4 import BeautifulSoup da includere sotto la richiesta di importazione di requests. Ancora una volta PyCharm sottolineerà in rosso la nuova richiesta di importazione del modulo. E noi possiamo risolvere il problema, eliminando l’errore seguendo la stessa procedura già illustrata – soffermarsi sulla sottolineatura in rosso e facendo aprire la finestra di dialogo, quindi cliccando sul link oppure eseguendo il comando con la sequenza di tasti Alt + Enter, quindi optando per l’installazione – “Install package BeautifulSoup4”.
A differenza dell’esempio precedente, questa volta abbiamo sottolineato in rosso sia bs4 che BeautifulSoup. Tentando di installare il modulo da BeautifulSoup il sistema si blocca perché va in errore. Questo perché tenta di installare una versione non aggiornata del pacchetto non supportata da Python 3. Devi installare BeautifulSoup4 per mezzo del prompt bs4 come puoi vedere nella prossima screenshot.
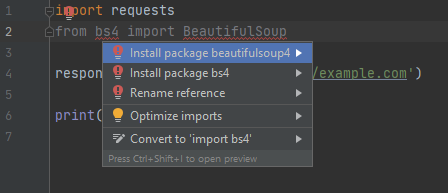
Anche in questo caso PyCharm farà installazione automatica del modulo che, una volta terminata, sarà pronto per l’uso.
Il codice che segue è molto simile a quello che abbiamo visto nella seconda parte di questo tutorial sul Python per il SEO. Come in quell’esempio, procediamo con l’estrazione del titolo, dei link e delle intestazioni di paragrafo dalla pagina.
import requests
from bs4 import BeautifulSoup
response = requests.get('https://example.com')
soup = BeautifulSoup(response.text, 'html.parser')
print('title: {}'.format(soup.title.string))
print('links:')
for link in soup.find_all('a'):
print(' - target: {}'.format(link.get('href')))
print(' anchor: {}'.format(link.string))
print('headings:')
for heading in soup.find_all('h1'):
print(' - {}'.format(heading.string))Il cui output è:
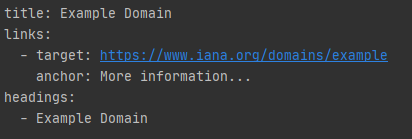
Complimenti! Non solo abbiamo scaricato i contenuti di una pagina, ma abbiamo estratto alcuni elementi molto importanti della pagina!
Potremmo fare dei test SEO utilizando i conenuti della pagina. Tuttavia abbiamo fatto ancora poco. I computer possono sviluppare molti task semplici come questo. Allora vediamo qualcos’altro che si può fare – qualcosa di più ambizioso come ad esempio scaricare parte di un intero sito!
Leggere un file CSV
Se vogliamo scaricare un sito web abbiamo a disposizione diverse opzioni.
Una possibilità è iniziare dalla home page e scrivere un nostro crawler per indicizzare tutte le pagine. Questo implica seguire i link, stabilire la profondità del crawling, l’estrazione di ancora altri link dalle pagine scaricate, verificare se i link incontrati sono interni oppure esterni, ed infine una verifica di procedura per evitare di rimanere intrappolati in loop infiniti.
Una seconda alternativa che può farci risparmiare molto tempo è ad esempio utilizzare i dati di indicizzazione di terze parti – ad esempio un CSV esportato da majestic.com. Per questo esempio abbiamo utilizzato dieci pagine prese da un report di questo blog (blog.majestic.com).
Puoi scaricare questo estratto di URL contenente 49 URL diverse con diverse tipologie di contenuti e codici di risposta del server. Il file CSV è disponibilie cliccando qui.
Python, per fortuna, ha la capacità di leggere i file CSV. Dobbiamo attivare questa funzionalità ma non per questo importare un modulo esterno così come abbiamo fatto per requests e BeautifulSoup4. Per il prossimo esempio puoi eliminare le righe utilizzate per l’esempio di BeautifulSoup e sostituire con il seguente codice:
import csv
file_location = 'W:/path/to/input-pages-blog-majestic-com.csv'
with open(file_location, mode='r', encoding='utf-8-sig') as csv_file:
csv_reader = csv.DictReader(csv_file)
for row in csv_reader:
print(row['URL'])È necessario lavorarci un po per essere utilizzabile. Cominciamo con una spiegazione del codice appena introdotto.
Questo codice ci mostra gli elementi essenziali di gestione di un file CSV. Il file deve essere aperto per poter leggere i dati. Quindi si crea un lettore per gestire i contenuti. Il lettore è richiamato in maniera ricorsiva per leggere ogni riga e quindi ciascuna URL.
la variabile file_location deve essere modificata per riflettere il percorso che hai sul tuo computer. Un modo per estrarre questo dato dal tuo computer è attraverso Windows Explorer – naviga fino alla cartella dove hai salvato il file. Premi SHIFT e poi tasto destro del mouse. Dal menu contestuale scegli (copia percorso – “copy as path”).
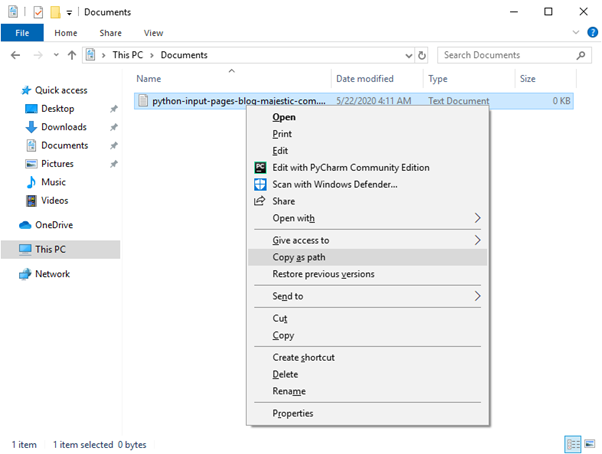
Sostituisci la tua path con quella dell’esempio precedente. Se l’output del programma python somiglia a quello che trovi nell’immagine che segue lo script è stato eseguito correttamente – complimenti!
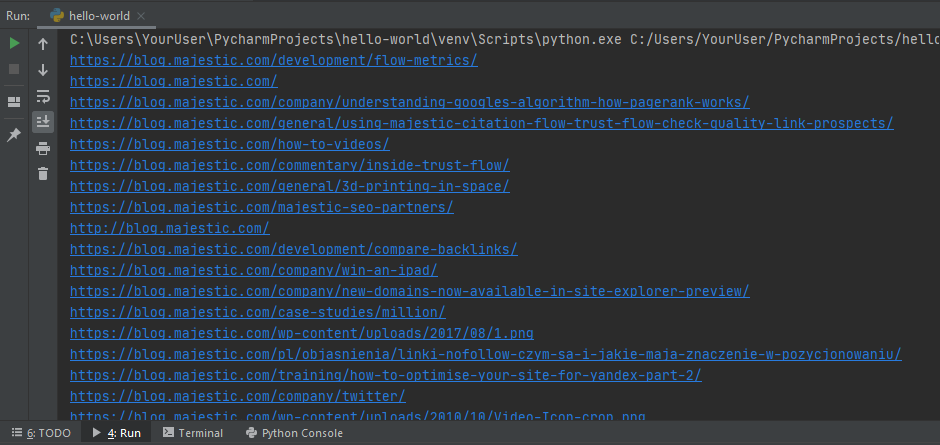
Adesso dobbiamo prepararci per scaricare le pagine , analizzarle, salvarle e creare il nostro piccolo indice.
Filtri per individuare i contenuti
Un problema comune nei programmi come questo è che estraggono dati che non sempre sono utili per le finalità prefissate. In questo caso il file CSV contiene le prime pagine riportate dal Site Explorer di Majestic e alcune righe non identificano pagine HTML.
Un approccio semplicistico per filtrare gli indirizzi è ad esempio eliminare quelle URL che hanno un suffisso come “png” oppure “jpeg”. Da un punto di vista pratico è buona norma precedere con la creazione di un nuovo file contenente il risultato finale.
A quel punto diventa piuttosto facile capire come organizzarci. Possiamo fare un controllo sulle URL esistenti utilizzando il metodo string method endswith per decidere se una data URL deve essere scritta in un nuovo file di output.
import csv
from urllib.parse import urlparse, urljoin
file_location = 'W:/path/to/input-pages-blog-majestic-com.csv'
# Open the CSV file in read mode
with open(file_location, mode='r', encoding='utf-8-sig') as csv_file:
csv_reader = csv.DictReader(csv_file)
# A set of resources to fetch later
prospects = set()
for row in csv_reader:
url = urlparse(row['URL'])
if not url.path.endswith(('/feed/', '.png', '.jpg', '.gif')):
prospects.add(urljoin(row["URL"], url.path))
print('There are {} prospective pages'.format(len(prospects)))Questo codice si avvale di quello che è stato scritto prima, effettuando un’azione di filtraggio per eliminare tutte le URL che non ci interessano per creare il nuovo set di URL.
La variabile prospects è un set utilizzato per memorizzare tutte le URL di cui abbiamo bisogno. Un set è un insieme non ordinato di elementi unici (quindi senza duplicati). Lo utilizziamo qui perché l’ordinamento degli elementi non è importante. Facendo la pulizia, ad esempio togliendo parametri o hash alcune URL potrebbero risultare duplicate, richiedendo quindi di essere scaricate una sola volta.
Per identificare gli indirizzi che a noi non servono, dobbiamo effettuare un controllo sulla parte terminale della URL. Con una URL come questa:
https://example.com/path/page.html?param=inconvenient#part-of-pageAbbiamo un parametro e un frammento (la presenza dell’hash “#”). Mettersi a fare la segmentazione della URL è complicato ed è meglio affidarsi a delle procedure consolidate e frutto di uno sviluppo e verifica che noi non possiamo fare. Lo stesso discorso vale per i moduli Requests e BeautifulSoup. Qui possiamo utilizzare la libreria integrata di Pythonurllib per analizzare le URL con
url = urlparse(row['URL'])Adesso, quando facciamo riferimento a url, s’intende una coppia di valori che in Python si chiama Tuple. Il tuple è costituito dalle varie componenti che caratterizzano la URL: Il protocollo, la localizzazione (dominio/sottodominio) parametri di percorso, parametri di URL, e frammenti – urlparse è ben documentato.
Adesso la nostra URL è ben definita e possiamo determinare se il percorso termina con uno qualsiasi dei filtri che abbiamo identificato. Se questo non succede, allora la URL viene aggiunta al set.
if not url.path.endswith(('/feed/', '.png', '.jpg', '.gif')):
prospects.add(urljoin(row["URL"], url.path))Per evitare di memorizzare anche elementi inutili, possiamo utilizzare (urljoin(row[“URL”], url.path). Questo prende il percorso della URL e la combina con la URL originale dando origine all’indirizzo completo senza parametri o frammenti.
Alla fine del processo dovremmo avere qualcosa del genere:
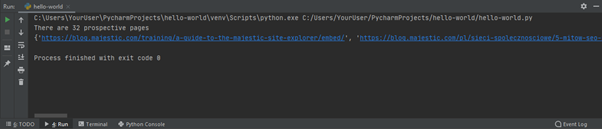
La prima riga mostra quante URL uniche sono state processate dal filtro. La seconda riga le riporta tutte (nota lo scroll orizzontale di pagina nella screenshot).
Ulteriori verifiche sulle URL
Fin qui abbiamo escluso quelle URL che sicuramente non sono pagine HTML. Ma siamo sicuri che tutte le altre rispondono alla nostra esigenza? Siamo sicuri che tutte le URL che Majestic ha individuato e che sono state riportate nel report che abbiamo utilizzato siano “vive” ovvero che rispondono? Ad esempio, ci potrebbero essere degli errori 404 di pagina non trovata. Un modo per fare questa verifica è suddividere la richiesta di download per la pagina in due momenti: una prima richiesta HEAD che evita il download di contenuti, seguita da una seconda richiesta di GET per scaricare i contenuti ove applicabile. HEAD restituisce un insieme di HTTP headers che contengono informazioni sulla risorsa interrogata come ad esempio il tipo di contenuto – per l’HTML è “text/html” e se siamo in presenza di un redirect. Il codice così concepito memorizza queste informazioni insieme ai contenuti e potranno essere utilizzate in un secondo momento.
A questo punto il codice da scrivere comincia ad essere parecchio. Abbi pazienza che adesso spieghiamo cosa fa questo codice.
import csv
import time
from urllib.parse import urlparse, urljoin
import requests
file_location = ' W:/path/to/input-pages-blog-majestic-com.csv'
output_dir = 'W:/code/python-tutorial-blog'
index_csv_location = '{}/index-file.csv'.format(output_dir)
# Open the CSV file in read mode
with open(file_location, mode='r', encoding='utf-8-sig') as csv_file:
csv_reader = csv.DictReader(csv_file)
# A set of resources to fetch later
prospects = set()
for row in csv_reader:
url = urlparse(row['URL'])
if not url.path.endswith(('/feed/', '.png', '.jpg', '.gif')):
prospects.add(urljoin(row["URL"], url.path))
print('There are {} prospective pages'.format(len(prospects)))
# Open index file to write output
with open(index_csv_location, mode='w', newline='', encoding='utf-8-sig') as index_csv:
fieldnames = ['id', 'url', 'filename', 'status', 'location']
writer = csv.DictWriter(index_csv, fieldnames=fieldnames)
writer.writeheader()
page_id = 0
for url in prospects:
print('Processing {}'.format(url))
# Fetch header first to get check content type
response = requests.head(url)
# Content type can contain encoding information after a semi-colon (`;`), which we're not interested in
content_type = response.headers.get('Content-Type').split(';')[0]
if content_type == 'text/html':
page_id += 1
cache_filename = ''
location = ''
if response.is_redirect:
location = response.headers.get('Location')
elif response.status_code == 200:
response = requests.get(url)
cache_filename = '{}/page-{}.html'.format(output_dir, page_id)
with open(cache_filename, mode='w', encoding='utf-8') as cache:
cache.write(response.text)
writer.writerow({
'id': page_id,
'url': url,
'filename': cache_filename,
'status': response.status_code,
'location': location
})
else:
print('Ignoring non-HTML content type "{}"'.format(content_type))
# Pause the execution of the script to prevent an aggressive spam of requests
time.sleep(1)La maggior parte del codice scritto si somiglia a quello già visto fin qui con alcuni miglioramenti che adesso andiamo a spiegare.
Qui abbiamo aggiunto la presenza di “time” un nuovo modulo che abbiamo importato. Time si usa per cadenzare l’esecuzione del nostro programma, inserendo delle pause nello script per un certo numero di millisecondi. Noi lo utilizziamo per limitare la velocità di download delle pagine web.
Abbiamo introdotto anche due nuove variabili di output. La prima è output_dir che indica il percorso da seguire per scrivere il file con i dati. La seconda variabile è index_csv_location a cui si affianca l’HTML della pagina.
# Open index file to write output
with open(index_csv_location, mode='w', newline='', encoding='utf-8-sig') as index_csv:
fieldnames = ['id', 'url', 'filename', 'status', 'location']
writer = csv.DictWriter(index_csv, fieldnames=fieldnames)
writer.writeheader()Nota come questa volta apriamo un altro file (il nostro output index) in modo simile a prima, ma specifichiamo la modalità mode='w' che ci permette di scrivere nel file anziché leggere. Creiamo poi un CSV writer e scriviamo gli header all’inizio del file.
Per assicurarci che la URL è di una pagina web, facciamo una prima chiamata per acquisire gli header. Gli header memorizzano il “Content-Type”, che può contenere la tipologia dei contenuti ed il loro encoding. Ad esempio, “text/html; charset=UTF-8”. Quindi per fare una verifica abbiamo suddiviso la stringa con un punto-e-virgola response.headers.get('Content-Type').split(';')[0] e abbiamo preso la prima parte.
# Fetch header first to get check content type
response = requests.head(url)
# Content type can contain encoding information after a semi-colon (`;`), which we're not interested in
content_type = response.headers.get('Content-Type').split(';')[0]
if content_type == 'text/html':L’altra differenza significativa è il salvataggio (caching) delle pagine web scaricate. Così come abbiamo fatto per con il file index, si apre il file in modalità scrittura. Questa volta utilizziamo il page ID per formularne il nome. Si procede quindi con il salvataggio dei contenuti.
cache_filename = '{}/page-{}.html'.format(output_dir, page_id)
with open(cache_filename, mode='w', encoding='utf-8') as cache:
cache.write(response.text)Infine, il risultato è scritto nel file index. Questo è un loop in modo da elaborare tutte le URL e scaricare tutte le pagine web.
writer.writerow({
'id': page_id,
'url': url,
'filename': cache_filename,
'status': response.status_code,
'location': location
})E adesso facciamo una prova! Una volta eseguito lo script, dovresti ritrovarti un file index con le informazioni di pagina e loro contenuti.
Aprendo il file index vediamo una varietà di risultati. Ci sono pagine con status “200” che sono state indicizzate e memorizzate, ci sono dei “404” che sono state salvate ma non sono state memorizzate e poi ci sono dei reindirizzamenti – anch’essi indicizzati con l’indirizzo finale. Nel file ci sono solo 27 righe, pur avendo 32 nel file iniziale.
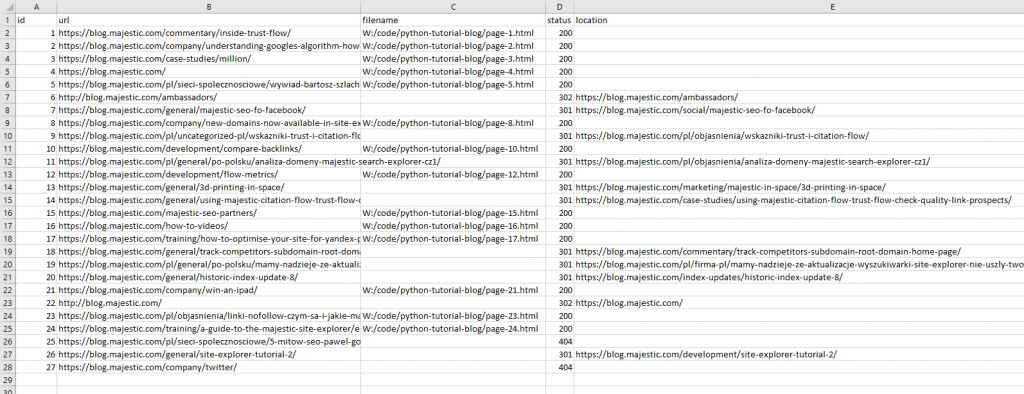
Facendo una verifica del log di processo di Python notiamo che, nonostante la nostra azione preventiva di filtraggio per eliminare URL di pagine non HTML, ci siamo dimenticati dei file PDF e Excel. Questi file sono stati intercettati e scartati grazie al controllo sul content-type. Perfetto!
Dovresti avere anche una cartella con file i HTML – un file per ogni pagina scaricata.
È molto probabile che i file generati sul tuo computer si presenteranno in un ordine diverso rispetto a quello che vedete riportato qui. Questo perché abbiamo utilizzato un set per memorizzare le URL che non memorizza l’ordine.
Concludendo (per ora)
Bene, abbiamo visto molte cose in questa lezione e quanto si può fare con un piccolo programma in Python. Complimenti per averci seguito fin qui.
In questa lezioni abbiamo visto:
- Come s’installano Python e PyCharm
- Come si crea un nuovo progetto in PyCharm
- Che cos’è la struttura di dati “Set”
- Il parsing e la gestione dei dati mediante URL
- La lettura e scrittura di file (in formato CSV e TXT)
- Come acquisire e verificare le intestazioni di pagina web (headers)
E altre cose interessanti che ti saranno sicuramente di aiuto in Python.
Adesso puoi scaricare pagine da un sito web e analizzarle. Il codice di questo programma che abbiamo visto oggi può diventare il nocciolo centrale di una strategia automatizzata di SEO tecnico.
Nella prossima lezione affronteremo altri temi per il trattamento automatico dei dati e come collaborare nello sviluppo del codice. Nel frattempo se hai dubbi o suggerimenti lascia un commento. Usa la sezione dei commenti per farci sapere cosa hai fatto con il codice di questa lezione.
Alla prossima volta.
- Report dei Backlink in PDF con Site Explorer - May 23, 2023
- Python per il SEO – 3 - July 6, 2020
- MVP and Iterative Development - April 23, 2018