





HTTP-Statuscodes können nerdy und geeky erscheinen, aber sie können erhebliche reale Auswirkungen auf Politik und Strategie haben, die WEIT über SEO hinausgehen.
Wir haben viele 404-Leitfäden gesehen, und nicht alle von ihnen sind so toll. Majestic hat jahrelange Erfahrung im Crawling und Mapping des World Wide Webs. Wir wollten etwas von dem Wissen, das wir aufgebaut haben, mit IHNEN in einem Leitfaden teilen, der erklärt:
- 404s & fehlende Seiten
- Wie Sie 404er auf Ihrer eigenen Website finden
- Warum Sie über fehlende Seiten auf Konkurrenzseiten Bescheid wissen sollten
- Wie 404-Fehler die Geschäftsstrategie beeinflussen können
Wir haben versucht, Links zu Quellen von Drittanbietern einzubauen, um Ihr Verständnis auf die nächste Stufe zu heben. Es gibt einige großartige Ressourcen da draußen. Wir haben keine Affiliate-Links eingefügt, so dass jede Einfügung auf Verdiensten und nicht als Teil eines Deals erfolgt.
Unser Leitfaden führt Sie durch die Grundlagen dessen, was eine 404-Seite ist, und zeigt Ihnen Möglichkeiten auf, wie Sie die Vorteile von 404-Seiten nutzen können. Am Ende dieses Leitfadens blicken wir in Richtung Strategie.
404-Handbuch
In diesem Abschnitt des Leitfadens befassen wir uns mit den Grundlagen von “404 Page not found”.
Lesen Sie weiter, um zu erfahren:
- Was ein 404-Statuscode bedeutet?
- Was verursacht 404er?
- Wie sehen 404-Seiten aus?
- Warum sind 404er für SEO wichtig?
Was ist ein HTTP 404-Statuscode?
Einfach ausgedrückt, zeigt ein 404 an, dass eine angeforderte Webseite nicht auf einer Website existiert.
Technisch gesehen ist 404 einer aus einer Familie von HTTP-Statuscodes (richtiger: Standard Response Code), der “Seite nicht gefunden” oder “Datei nicht gefunden” anzeigt. Sowohl HTTP- als auch HTTPS-Webserver können 404-Fehler zurückgeben.
Warum sehe ich eine 404-Meldung?
Ein 404-Fehler zeigt an, dass eine Seite auf einer Website nicht gefunden wurde. Typischerweise geschieht dies auf eine von zwei Arten:
- Der Benutzer klickt auf einen “defekten Link”, der verspricht, den Benutzer zu einer interessanten Seite auf einer anderen Website zu führen.
- Ein Benutzer tippt eine Website und eine Seite in die Adressleiste des Webbrowsers ein, die nicht existiert.
Es gibt auch eine dritte Art von “versteckten 404”. Während Sie als Webmaster oder Serveradministrator einen 404 erleben können, wenn Sie auf einen nicht funktionierenden Link klicken, können Sie 404s in Serverprotokollen finden, wenn ein Computerprogramm versucht, auf eine “fehlende Ressource” auf einer Website zuzugreifen.
Schauen wir uns beide ein wenig genauer an.
Kaputte Links
Ein defekter Link ist einfach ein Link, der auf eine Seite zeigt, die es nicht gibt. Dies kann aus einer Reihe von Gründen geschehen; einige sind:
- Der Inhalt der Seite, auf die verlinkt wurde, wurde seit der Erstellung des Links verschoben oder entfernt.
- Die Person, die den Link eingefügt hat, hat einen Fehler gemacht
- Jemand arbeitet an der Website und hat vorübergehend eine Seite entfernt
Bei der Betrachtung von defekten Links ist es wichtig, zu berücksichtigen, woher der defekte Link kommt und WO der defekte Link hinführt.
In der SEO-Sprache wird die Seite, die den verweisenden Link enthält, als Quellseite bezeichnet.
Die Seite, auf die der Link verweist, wird Zielseite genannt.
Wenn der defekte Link eine Quelle und ein Ziel auf Ihrer eigenen Website hat, dann ist das eine gute Nachricht! Solange Sie die Quell- und Zielseiten kennen, können Sie das Problem beheben. Wir werden uns später in diesem Beitrag mit einer verfeinerten Strategie befassen, aber für den Moment könnten Sie in Erwägung ziehen, den Link von der Quellseite zu entfernen, ihn auf eine andere Seite Ihrer Website zu verlinken oder zu versuchen, relevante Inhalte an die Stelle zu setzen, auf die der defekte Link verweist (oder zurück).
Wenn sich die Quellseite auf Ihrer Website befindet und das Ziel des defekten Links auf der Website eines anderen Anbieters liegt, könnte ein einfacher Ausweg darin bestehen, den Link ganz zu entfernen. Bevor Sie das tun, sollten Sie jedoch überlegen, ob der ausgehende Link von Ihrer Seite den Lesern Ihrer Website hilft. Manchmal kann es gut sein, eine alternative Autoritätsseite zu finden, auf die man verlinken kann, oder zu sehen, ob die Seite auf der Zielseite umgezogen ist.
Wenn Sie das Ziel des defekten Links auf Ihrer Seite finden, es aber auf eine andere Seite zeigt/von einer anderen Seite abgeleitet ist, dann ist das die Quelle des Links und es ist wichtig, mit Vorsicht vorzugehen.
Es kann verlockend sein, sich an den Besitzer zu wenden und ihn zu bitten, den Link zu ändern, um ihn zu “reparieren”. Seien Sie vorsichtig! Dies ist oft die falsche Vorgehensweise, da Sie jemand anderen bitten, eine Arbeit zu erledigen, die Ihnen kostenlos zugute kommt.
Anstatt jemand anderen zu bitten, einen defekten Link zu Ihnen zu reparieren, sollten Sie in Erwägung ziehen, ihn selbst zu reparieren! Sie können einen defekten Link von einer Drittseite beheben, indem Sie einen “Redirect” zu der Stelle auf Ihrer Seite hinzufügen, auf die der defekte Link zeigt. Diese Umleitung könnte Ihren Besucher nahtlos zu relevanten Inhalten auf Ihrer eigenen Website weiterleiten. Die genaue Art und Weise, eine Weiterleitung zu implementieren, variiert von Plattform zu Plattform, aber Ihr Webmaster oder Content-Management-System-Anbieter sollte in der Lage sein, Sie zu beraten, wie Sie Weiterleitungen zu Ihrer Website hinzufügen können.
Sie denken vielleicht, dass defekte Links auf einer fremden Website, die auf eine andere Website verweisen, Sie nichts angehen. Wenn Sie jedoch über ausreichend guten Content verfügen, kann diese Form des “Broken Link Building” eine wertvolle Form der digitalen PR sein. Eine Möglichkeit, die Sie nutzen können, ist es, kaputte Links, die auf eine andere Website (die nicht die Ihre ist) zeigen, auszunutzen und Links mit ihnen aufzubauen. Diese Form des “broken link building” kann eine wertvolle Form der Digitalen PR sein.
Lesen Sie weiter, um mehr zu erfahren.
Eingetippte URL
Viele Menschen verlassen sich auf Suchmaschinen wie Google, um relevante Inhalte zu finden. Warum also sollte jemand eine 404 eintippen?
Dafür gibt es ein paar Gründe.
Printmedien sind nicht verschwunden. Hashtags, Handles und URLs auf gedruckten Materialien sind alltäglich. Während Covid einen Anstieg von QR-Codes gesehen hat, da Unternehmen versuchen, berührungslos zu arbeiten, passiert das Kopieren und Einfügen einer URL aus Printmedien immer noch.
Marketer sollten sich dreier potenzieller Quellen für falsch eingegebene URLs bewusst sein:
- Tippfehler auf Werbematerial
- Menschliches Versagen bei der Erstellung von Werbematerial
- Leute, die ihr Glück versuchen oder “erforschen”
Viele Unternehmen haben mittlerweile einen gewissen Freigabeprozess für gedrucktes Material, der auch den digitalen Aspekt abdeckt, aber Fehler kommen trotzdem vor. Wenn URLs auf Drucksachen verwendet werden sollen, sollten sie kurz und einprägsam sein – idealerweise mit nicht mehr als einem Wort nach einem Schrägstrich – wie z. B. die Chrome-Werbung von Google in Großbritannien, die zum Besuch von “google.co.uk/chrome” einlädt. Es sollte sich von selbst verstehen, dass Plakatwände und Flugblätter kein Platz für Tracking-Parameter oder UTM-Codes sind.
Dies führt uns zu unserem zweiten Punkt. Menschen machen Fehler. Wenn eine URL veröffentlicht wird, ist es sinnvoll, sicherzustellen, dass sie kurz, einzigartig und einprägsam ist, selbst wenn die resultierende URL auf eine längere URL umgeleitet wird. Wenn die URL für Ihr Unternehmen von wesentlicher Bedeutung ist (z. B. ein Menü), sollten Sie einen QR-Code oder einen Link von Ihrer Homepage in Erwägung ziehen, der jede URL begleitet. Die URL “beispiel.com/menu” ist einfacher zu tippen, zu merken und problemloser als beispiel.com/get-menu oder beispiel.com/spring-menu. Interpunktion muss mit Sorgfalt behandelt werden: Bindestriche, Unterstriche und Leerzeichen können besonders problematisch sein.
Der letzte Fehler – das Erforschen durch den Menschen – ist schwer von Fehlern zu unterscheiden. Während wiederholte Versuche mit fehlgeschlagenen URLs Anlass zur Sorge sein können, handelt es sich oft nur um jemanden, der neugierig ist und das digitale Äquivalent dazu macht, durch Ihr Fenster zu starren, um Ihre Waren zu sehen. Wenn Ihr Geschäftsmodell davon abhängt, Dinge im öffentlichen Internet zu verstecken, kann es von einer sorgfältigen Überlegung profitieren.
404s als fehlende Ressourcen
Entwickler und Webmaster können Berichte über fehlende 404-Inhalte in Server-Logs finden – Aufzeichnungen, die von Webservern über Seitenaufrufe und Fehler geführt werden. Nicht alle sind das Ergebnis des Besuchs von Benutzern auf der Seite. Die meisten Website-Besitzer benötigen diese Detailtiefe wahrscheinlich nicht, aber für die Neugierigen gibt es einige etablierte URLs, die Programme als normalen Teil des Webbetriebs besuchen.
Einige häufige Ressourcen, die angefordert werden, sind:
- Robots.txt – “Gute” Web-Crawler (wie der Majestic-Crawler) sollten vor dem Crawlen prüfen, ob eine “robots.txt”-Datei auf einem Server vorhanden ist. Sie weisen den Crawler an, welche Teile der Website gecrawlt werden sollen und welche nicht und wie oft der Crawler Seiten herunterladen soll.
- Favicon – ein kleines Logo, das Ihr Webbrowser in einem Tab anzeigen kann, wenn Ihre Website besucht wird
- Sitemap – einige zusätzliche Vorschläge für Web-Crawler, wie Inhalte entdeckt und auf Änderungen überwacht werden können
Es gibt noch andere, eher esoterische Ressourcen, die 404-Fehler erzeugen können. Obwohl es wichtig ist, zu überlegen, ob Sie die drei oben genannten Dateien benötigen, sind nicht alle 404-Fehler besorgniserregend.
Es sollte hinzugefügt werden, dass es Web-Crawler gibt, die Websites auf unsichere Probleme oder Schwachstellen untersuchen. Aus diesem Grund sollten Webmaster äußerste Sorgfalt walten lassen, um einen Webserver abzusichern und sich Gedanken über Richtlinien zur Datenverwaltung zu machen. Es ist traurig zu sagen, dass der Umgang mit bösen Bots und die Absicherung Ihrer Website bis zu einem gewissen Grad zum Betrieb einer Website dazugehören. Es ist ein ziemlicher Aufwand, aber der Umgang mit bösen Bots und die Absicherung Ihrer Website ist Teil des Betriebs einer Website.
Wie sieht eine 404-Seite aus?
404-Seiten sind unterschiedlich. Der Statuscode “404” wird vom Server direkt von Ihrem Webbrowser übermittelt. Manchmal wird eine Seite mit der Meldung “Nicht gefunden”, gefolgt von der Meldung “Die angeforderte URL wurde auf diesem Server nicht gefunden” zurückgegeben, wie z. B. die unten stehende:
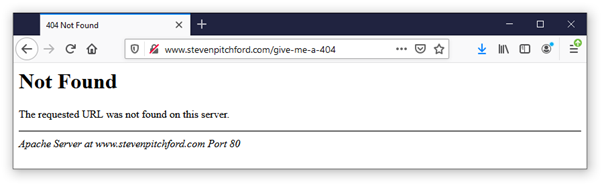
Dies ist eine Seite, die standardmäßig für 404s vom beliebten Apache-Webserver zurückgegeben wird. In diesem Beispiel muss der Site-Besitzer seinen Apache-Webserver noch so konfigurieren, dass er eine benutzerdefinierte 404-Seite liefert.
Viele Website-Besitzer entscheiden sich dafür, eine benutzerdefinierte 404-Seite einzustellen, was bedeutet, dass einige Male schönere Seiten zurückgegeben werden, wie diese von Majestic:

Wenn Sie daran interessiert sind, mehr Beispiele für gecrawlte Seiten zu sehen, hat OnCrawl eine Liste mit einigen der besten 404-Seiten zusammengestellt, die sie gefunden haben.
Wie erstelle ich eine 404-Seite?
Es gibt viele Gründe, warum Sie eine 404-Seite erstellen möchten, eine gute UX (User Experience) ist wahrscheinlich einer davon. Die genaue Art und Weise, eine 404-Seite zu konfigurieren, hängt von Ihrem Webserver und Content-Management-System ab, aber im Wesentlichen wird eine 404-Seite wie jede andere Webseite gestaltet. Im Google Advanced SEO Guide finden Sie einige Vorschläge, die Sie bei der Gestaltung Ihrer 404-Seite berücksichtigen sollten:
- Machen Sie dem Nutzer klar, dass die Seite nicht gefunden werden kann, aber seien Sie nett!
- Stellen Sie sicher, dass das Branding und die Navigation Ihrer 404-Seite mit dem Rest Ihrer Website konsistent ist.
- Denken Sie an den/die Benutzer – fügen Sie nützliche Links zu beliebten Ressourcen zu Ihrer 404-Seite hinzu.
- Denken Sie daran, eine Möglichkeit für Benutzer bereitzustellen, einen defekten Link zu melden.
- Verhindern Sie, dass 404-Seiten von Google und anderen Suchmaschinen indiziert werden, indem Sie einen tatsächlichen 404-HTTP-Statuscode zurückgeben.
Dies sind nützliche Richtlinien, die aber eine Reihe von weiteren Fragen aufwerfen können. Ein Großteil der Ratschläge konzentriert sich auf die UX, was verständlich ist, da der Besucher Ihre Website möglicherweise zum ersten Mal sieht, wenn er über einen externen defekten Link gekommen ist.
Anstatt Worte zu wiederholen, die an anderer Stelle besser ausgedrückt wurden, hat das Wire-Framing-Tool JustinMind einen UX-fokussierten Leitfaden für 404-Seiten erstellt, der wichtige Aspekte wie Markenästhetik und die Erfüllung von Nutzerbedürfnissen untersucht. Der Leitfaden ist eine wertvolle Ressource für Designer und SEOs gleichermaßen.
Sind 404-Seiten schlecht?
Nein! Wir werden später noch auf die Wissenschaft dahinter eingehen, aber 404-Seiten sind nicht schlecht – wie so viele Dinge im Leben ist eine fehlende Ressource auf einem Webserver ein fast unvermeidliches Ereignis, das von Zeit zu Zeit auftritt.
Das heißt, wenn Ihre Website 404-Seiten verursacht, dann ist das nicht gut. Ein defekter Link auf Ihrer Website oder zu Ihrer Website kann eine unangenehme Beule in der Reise Ihrer Benutzer darstellen. Eine schlecht positionierte fehlende Seite könnte die Ursache für verlorene Verkäufe sein.
Es ist wichtig, zwischen defekten Links und fehlenden Seiten zu unterscheiden. Fehlende Seiten, die 404er generieren, sind einfach ein Nebenprodukt der Art und Weise, wie das Web aufgebaut ist. Bis zu einem gewissen Grad sind sie unvermeidlich. Allerdings können fehlende Seiten sowohl neue Möglichkeiten als auch einen hohen Wartungsaufwand bedeuten.
Eine reale Parallele zu einer 404-Seite könnte sein, dass jemand in Ihrem Geschäft anruft und fragt, ob Sie ein bestimmtes Produkt oder eine bestimmte Dienstleistung anbieten, die Sie nicht vorrätig haben, oder anders gesagt, eine Anfrage nach einem nicht vorrätigen Artikel.
Manche Unternehmen werden das als lästig empfinden. Andere werden es als Chance sehen. Der Versuch, eine Einheitslösung für nicht vorrätige Artikel zu finden, würde viel Geschick und Überlegung erfordern. Das Gleiche gilt für 404-Seiten.
Geben alle Webserver 404-Fehlerseiten an, wenn eine Seite fehlt?
Wie bei so vielen Dingen in der SEO, kommt es darauf an!
Wenn Sie sich “404”- oder “Seite nicht gefunden”-Seiten ansehen, ist es wichtig zu beachten, dass das, was Sie als 404-Seite sehen, nicht unbedingt eine echte 404-Seite ist.
Wenn ein Webbrowser einen Webserver nach einer Webseite fragt, gibt der Webserver zwei Datenpakete zurück, einen HTTP-Header und einen HTTP-Body.
Der HTTP-Body ist eine eindeutige Form von HTML-Code, der steuert, was in Ihrem Browser angezeigt wird.
Der HTTP-Header enthält spezielle Steuersignale, die Ihr Browser versteht, aber nicht an Sie weitergibt.
Der 404-Statuscode befindet sich im HTTP-Header-Teil der Daten. Es gibt viele andere Statuscodes, wie z. B. “200”, was bedeutet, dass alles gut ist, und sogar “418”, was mit “Ich bin eine Teekanne” beschrieben wird (https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/418). 418 ist ein großartiges Beispiel dafür, dass sich Nerd-Humor in Webstandards eingeschlichen hat. Glücklicherweise sind die meisten Webstandards etwas robuster und praktischer.
Zurück zu 404-Codes und Kopfzeilen. Da Webserver sehr konfigurierbare Software sind, können Webmaster sie so konfigurieren, dass sie eine Reihe von verschiedenen Aktionen ausführen, wenn eine fehlende Seite erkannt wird. Erfahrene Webmaster können über die benutzerdefinierten 404-Seiten hinausgehen und Aktionen wie die Weiterleitung des Benutzers an eine andere Seite oder die Rückgabe einer 200-Meldung durchführen, um dem Webbrowser mitzuteilen, dass die Seite in Ordnung ist, während sie dem Benutzer eine Nachricht übermitteln, die darauf hinweist, dass die Seite fehlt.
Warum sollte sich jemand solche Mühe geben, um eine fehlende Seite zu verstecken?
Wie bei so vielen Dingen in der SEO gibt es auch bei den Empfehlungen Trends und Moden, vielleicht ausgelöst durch Anregungen aus der digitalen Marketing-Community, manchmal auch durch Gerüchte.
Vor ein paar Jahren gab es eine große Debatte darüber, ob 404er gut oder schlecht sind, mit dem Ergebnis, dass einige Websites beschlossen haben, zu versuchen, überhaupt keine 404er zurückzugeben. Dieser Ansatz wird heute allgemein als etwas extrem angesehen, da 404s ein natürlich vorkommendes Phänomen sind und wohl nichts, wofür man sich schämen müsste.
Ein weiterer Aspekt ist das Crawl-Budget. Der Crawler einer Suchmaschine hat nur so viele Ressourcen, wie er auf Ihre Website werfen kann. Soft 404s können eine Menge Crawler-Ressourcen in Anspruch nehmen, da sie eine Website nahezu unendlich groß machen.
Was haben 404-Seiten mit SEO zu tun?
Inhalte können nur indiziert werden, wenn sie vorhanden sind, und Inhalte helfen den Suchmaschinen, neue Links zu entdecken. Wenn Sie eine Menge kaputter Links und 404-Seiten ansammeln, kann dies zu:
- einem Verlust der Sichtbarkeit Ihrer Website
- einer schlechten Benutzererfahrung für Ihre Kunden
- potenziell geringeren Einnahmen für Ihr Unternehmen
Es gibt eine Debatte darüber, wie sehr sich Google um 404-Seiten und defekte Links kümmert und inwieweit diese Faktoren das Ranking beeinflussen können. Es wird jedoch davon ausgegangen, dass interne und externe Links eine wichtige Rolle bei der Priorisierung von Inhalten spielen. Eine Mischung aus der Sorge um das Ranking und den kommerziellen Auswirkungen sorgt dafür, dass das Verständnis von 404-Seiten und Strategien zu ihrer Entschärfung Teil des SEO-Skillsets bleiben.
Ein SEO kann helfen, defekte Links und fehlende Seiten auf Ihrer Website zu entdecken, diese Probleme mit relevanten Inhalten zu beheben und fehlende Inhalte auf Websites Dritter in Outreach-Kampagnen zu nutzen, die die Sichtbarkeit Ihrer Website unterstützen.
404-Fehler auf Ihrer eigenen Website finden
Sie sollten nun ein Verständnis dafür haben, was ein 404-Fehler ist und warum es notwendig sein kann, diesen zu beheben. Wir werden uns nun eine Reihe von Tools und Techniken ansehen, die Ihnen helfen, 404-Fehler auf Ihrer Website und auf Websites von Mitbewerbern zu finden, bevor wir uns einige Möglichkeiten ansehen, wie Sie 404-Fehler beheben und die Erstellung von 404-Fehlern in Zukunft vermeiden können.
Klicken Sie auf Ihrer Website herum
Während das Betrachten Ihrer Website als Benutzer für UX-Einblicke großartig sein kann, ist es ein schlechter Weg, um 404-Fehler zu finden, es sei denn, Ihre Website ist winzig.
Jede Seite Ihrer Website manuell zu besuchen, ist zeitaufwändig, fehleranfällig und eine wirklich fragwürdige Nutzung Ihrer Zeit! Tools wie Screaming Frog, Site Bulb und Majestic können Listen von defekten Links und den 404-Seiten, auf die sie verweisen, einfacher, schneller und fast immer kostengünstiger liefern als ein Mensch.
Ein Problem bei der manuellen Überprüfung, das mit der Art des “automatisierten Link-Klickens”, das einige Crawling-Dienste anbieten, geteilt wird, ist, dass nicht alle Ihre 404-Seiten verlinkt werden!
Ein benutzerdefinierter Crawl Ihrer eigenen Website wird oft kaputte Links in Ihrem Content finden, aber möglicherweise wertvolle Inhalte übersehen, auf die andere Leute verlinken und die nun auf Ihrer Website fehlen.
Da qualifizierter, fremder Traffic eine wertvolle Ressource ist, können diese externen Links eine Untersuchung wert sein, unabhängig von dem Wert, den Suchmaschinen ihnen beimessen.
Log-Datei-Analyse
Google Search Advocate John Mueller hat zu Protokoll gegeben: “Logdateien werden so unterschätzt, es stecken so viele gute Informationen darin.” (https://www.seroundtable.com/google-log-file-analysis-21919.html).
Was sind also Log-Dateien, und was haben sie mit SEO zu tun?
Wenn Ihr Webbrowser eine Webseite anzeigt, muss er die Webseite zunächst von einem Webserver herunterladen. Der Webserver ist ein Computerprogramm, das irgendwo läuft und Webseiten “serviert”.
Diese Webseiten sind entweder als HTML-Dateien gespeichert oder sie sind das Ergebnis eines Computerprogramms. Der Webserver ruft ein Computerprogramm auf, wenn komplexere Aktionen auf einer Website erforderlich sind, wie z. B. das Ausführen von Suchvorgängen, das Anzeigen eines Produktkatalogs oder das Hinzufügen von Dingen zu Warenkörben.
Webserver sind nicht nur für die Auslieferung von Websites verantwortlich, sondern führen auch Aufzeichnungen über Aktivitäten, die als “Logdateien” bezeichnet werden. Diese Logfiles enthalten oft die IP-Adresse des Besuchers und den von ihm verwendeten Webbrowser, zusammen mit der angeforderten Seite und dem vom Webserver zurückgegebenen Statuscode.
Die Analyse der Logfiles kann Ihnen Aufschluss geben:
- Welche Seiten am meisten heruntergeladen werden
- Wann der Googlebot Ihre Seite besucht hat
- Wenn Seiten angefordert werden, die es auf Ihrer Website nicht gibt (was zu einem 404-Statuscode führt)
- Und mehr…
Die Analyse von Logdateien ist jedoch kein Allheilmittel. Die Daten sind unbearbeitet, können eine Menge Rauschen von automatisierter Software enthalten und die Analyse kann Geschicklichkeit erfordern – es ist vielleicht nicht der beste Ansatz für Anfänger!
Majestic verwenden
Für viele Websites macht der Majestic Site Explorer das Auffinden von 404-Fehlern zu einem Kinderspiel. Geben Sie einfach den Namen Ihrer Website ein, wählen Sie den Reiter “Seiten” und klicken Sie auf “Crawl-Ergebnis”. Wenn Sie “HTTP 404 Not Found” auswählen, werden die zurückgegebenen Daten so reduziert, dass sie nur Seiten enthalten, die bei der letzten Untersuchung durch Majestic 404-Seiten zurückgegeben haben.
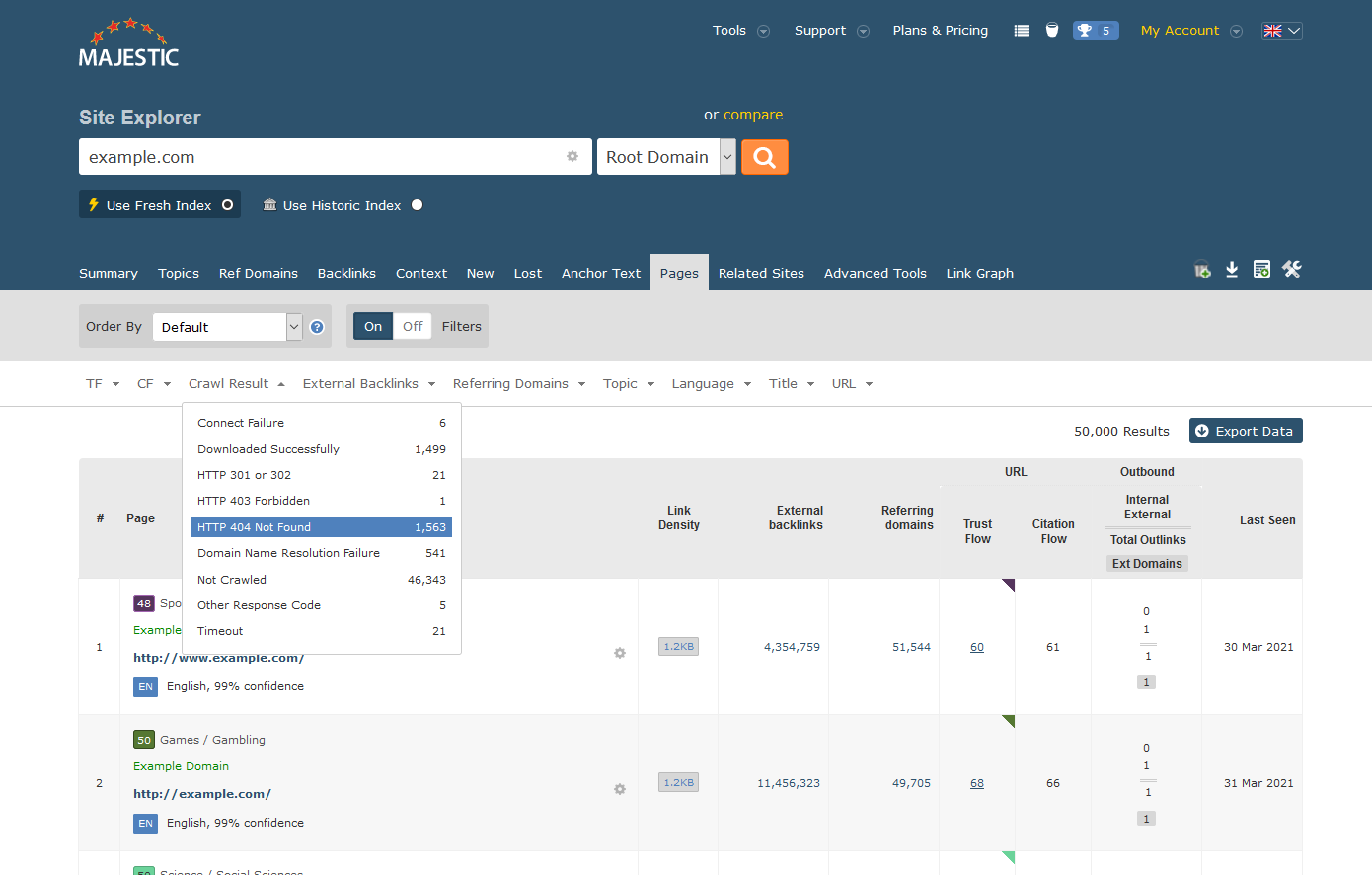
Sie können dies ganz einfach für Websites tun, die Sie kontrollieren, und wie wir später sehen werden, funktioniert die gleiche Technik auch bei Websites von Wettbewerbern, bei denen eine Outreach-Strategie helfen kann, die Sichtbarkeit Ihrer Marke zu erhöhen.
Wenn Sie 404er auf Ihrer Website finden, ist es am einfachsten, Ihre Liste direkt in Excel herunterzuladen und Metriken wie Trust Flow oder die Anzahl der verweisenden Domains zu verwenden, um die manuelle Behebung von defekten Links zu priorisieren. In unserem Leitfaden “Wie Sie defekte Links auf Ihrer Website beheben” finden Sie weitere Details.
Andere Tools
Es gibt eine Reihe von Plattformen, die Ihnen helfen können, 404er auf Ihrer eigenen Website zu finden. Zwei beliebte sind Google Search Console und Screaming Frog – ein vielseitiger Custom Crawler.
Wie können mir defekte Links zu Konkurrenzseiten helfen?
Organische Verweise von Autoritätsseiten können eine Quelle für qualifizierte Besucher sein, die sich wahrscheinlich engagieren werden. Unabhängig davon, wie hoch die Algorithmen des Suchmaschinen-Rankings relevante, organische Links bewerten, könnte Ihre Website von linkbasierten Besucherempfehlungen profitieren.
Eine potenzielle Quelle für Links ist es, Inhalte von Mitbewerbern zu finden, die entfernt wurden, aber immer noch Links haben, die auf sie verweisen. Sie können dann möglicherweise die Personen ansprechen, die auf den fehlenden Inhalt verlinken.
Broken Links können eine Goldgrube sein. Alles, was Sie wissen müssen, um 404-Seiten auf den Sites anderer Leute auszunutzen, sind:
- WER hat auf den fehlenden Inhalt verlinkt?
- WELCHER Inhalt fehlt jetzt?
- WENN Sie relevante Inhalte haben, die für die Besucher der Seite hilfreich sein könnten?
Sie benötigen ein paar Tools, die Ihnen bei der Identifizierung von Links helfen:
- Majestic – hilft Ihnen herauszufinden, wer auf was verlinkt
- Web Archive – hilft Ihnen, den fehlenden Inhalt herauszufinden
- Google – hilft Ihnen, relevante Inhalte auf Ihrer Site zu finden
- Eine Möglichkeit, Menschen zu erreichen, denen Sie helfen wollen
Es gibt eine Reihe von Möglichkeiten, Menschen zu erreichen, mit unterschiedlichen Meinungen über die Vorzüge von individueller und automatisierter Kontaktaufnahme. Anstatt zu versuchen, eine “Einheitsstrategie” vorzuschlagen, schlagen wir vor, dass Sie recherchieren und herausfinden, was für Sie und Ihr Unternehmen funktioniert!
Verwenden Sie Majestic, um defekte Links auf Websites von Drittanbietern zu finden
Wenn Sie Ihre Branche und die entsprechenden Websites kennen, ist die Verwendung von Majestic ganz einfach. Wiederholen Sie einfach den Prozess, den Sie für die Fehlersuche auf Ihrer eigenen Website mit Majestic verwenden. Verwenden Sie den Site Explorer, klicken Sie auf den Reiter Seiten und wählen Sie in den Filtern “HTTP 404 Not Found”-Fehler. Dadurch werden die Seiten aufgelistet, die unsere Crawler als fehlend erkannt haben.
Majestic kann auch Links zu den oben gefundenen defekten Seiten finden, was wir in unserer Anleitung zum Auffinden von 404ern mit Majestic behandeln.
In der Annahme, dass Sie kaputte Links zu gelöschten Seiten finden können, schlagen einige SEOs vor, dass es sich lohnt, die Leute, die auf die gelöschten Seiten verlinken, anzusprechen und, vorausgesetzt, Sie haben Inhalte, die dem gleichen Zweck dienen, sie zu bitten, stattdessen auf Sie zu verlinken.
Der nächste Schritt besteht darin, herauszufinden, was auf der Seite war. Dazu benutzen wir eine Zeitmaschine, um in der Zeit zurückzureisen und zu sehen, wie die Seite früher aussah! Oder, um es anders auszudrücken, an diesem Punkt kann die WayBack Machine des Internet-Archivs unter https://archive.org/web/ von unschätzbarem Wert sein!
Verwenden Sie die WayBack Machine im Internet Archive, um zu entdecken, was gelöscht wurde
Die WayBack Machine ist ein riesiges Depot von Inhalten, die über mehrere Jahre hinweg aus dem Web gecrawlt wurden. Sie bietet Ihnen die Möglichkeit, Online-Inhalte von vor Monaten oder sogar Jahren anzusehen.
Die WayBack Machine verfügt über ein Archiv von über 545 Milliarden Webseiten und ist einfach zu erkunden. Kopieren Sie einfach jede URL aus Ihrer Tabelle mit den fehlenden Seiten und fügen Sie sie in das Suchfeld der WayBack Machine ein, und klicken Sie zum Erkunden auf “Browse History”.
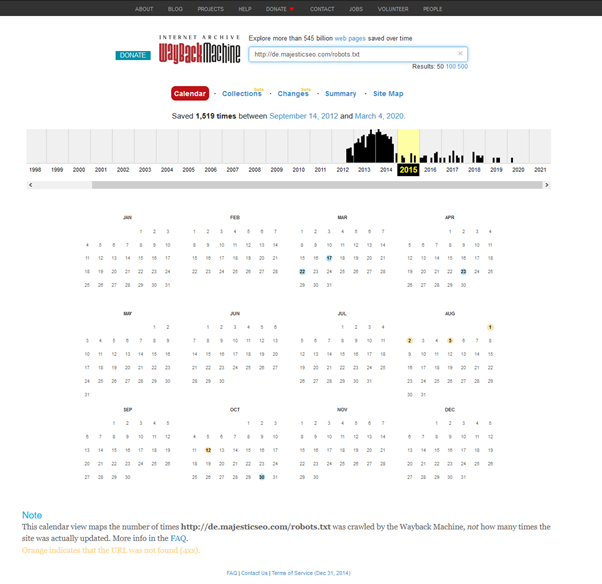
Die WayBack-Maschine präsentiert sich als Kalender. Typischerweise lassen die blauen Kreise den Zugriff auf Inhalte zu, grün zeigt eine Weiterleitung und orange einen 404 an.
Damit können Sie feststellen, wie der Inhalt früher aussah, um festzustellen, ob jemand, der auf diesen Inhalt verlinkt, an einem Ersatz interessiert sein könnte, und um zu beurteilen, ob es auf Ihrer Website etwas gibt, das es wert sein könnte, an seiner Stelle verlinkt zu werden.
Verwenden Sie Google, um relevanten Content auf Ihrer eigenen Website zu finden
Nachdem Sie die Möglichkeiten untersucht haben, Leuten mit kaputten ausgehenden Links Ihren alternativen Content anzupreisen”, lohnt es sich zu sehen, ob Sie Content haben, den eine vernünftige Person als gültige Alternative betrachten könnte.
Der “site:”-Operator in google kann bei diesem Prozess helfen, da er die Google-Suche auf eine Website Ihrer Wahl beschränkt. Möglicherweise möchten Sie einige verschiedene potenzielle Seiten untersuchen, indem Sie diese Schritte wiederholen, bis Sie fehlende Inhalte auf einer Drittanbieter-Website gefunden haben, für die Sie einen bestehenden Ersatz haben. Indem Sie sich Notizen machen und fehlende Seiten aufzeichnen, können Sie eine Wissensdatenbank aufbauen, die zu Ihrer zukünftigen Content-Strategie beitragen kann.
Strategien, um die Anzahl der auftretenden 404-Fehler in Zukunft zu reduzieren
Es gibt kein Patentrezept für die Reduzierung von 404-Fehlern. Es spricht viel dafür, regelmäßig Majestic SEO-Extraktionen von Kunden- und Wettbewerberdaten durchzuführen, um sicherzustellen, dass die oben genannten Möglichkeiten kontinuierlich genutzt werden.
Inhouse-SEOs stehen möglicherweise vor anderen Herausforderungen als Agenturen und Berater, wenn es um die Rolle geht, die sie spielen, und um die Ohren, die sie beugen können, um die notwendige Hebelwirkung in einer Organisation zu erreichen, um SEO-bewusste Richtlinien einzuführen.
Lassen Sie uns in einige der Bereiche eintauchen.
E-Commerce – 404-Fehler und Produktstrategie
Produktlebenszyklus-Management ist ein Bereich, in dem sich Geschäftsstrategie, Geschäftsbetrieb, SEO und CRO erheblich überschneiden. Obwohl es schwierig sein kann, Veränderungen zu erreichen, wenn so viele Beteiligte involviert sind, gibt es potenziell umsatzsteigernde Gewinne, wenn eine Anpassung erreicht werden kann.
E-Commerce-Seiten werden oft von Daten in Form von Produktkatalogen gesteuert. Es ist verständlich, dass bei vielen Unternehmen der Fokus des Produktkatalogs auf den Produkten liegt, die heute zum Verkauf stehen, und nicht auf denen, die morgen oder gestern zum Verkauf stehen.
Wenn Sie die Verbindung zwischen Ihrem Produktkatalog und Ihrer Website verstehen und wissen, wie sich der natürliche Lebenszyklus auf die Online-Sichtbarkeit Ihrer Website auswirkt, können Sie Ihren Gewinn steigern.
Einer der Grundgedanken der SEO für auslaufende Produkte ist, dass Menschen weiterhin nach einem Produkt suchen können, nachdem es nicht mehr zum Verkauf steht, und Einzelhändler können den Verbrauchern einen Vorteil bieten, indem sie Produktlisten beibehalten und alternative Produkte auf den entsprechenden Seiten anbieten. Dieser Ansatz wird im Allgemeinen eher als investigativ denn als präskriptiv betrachtet, da es oft eine Reihe von potenziell geschäftsspezifischen Angelegenheiten gibt, die sich auf die Beibehaltung der Produktpalette auswirken.
Ein weiterer Aspekt von datengesteuerten Produktkatalogen ist, dass die Produkthierarchie aus einem Backend-System generiert und möglicherweise von jemandem ohne SEO-Erfahrung gepflegt wird. Was wie eine einfache Änderung aussieht, nämlich das Verschieben von “Bohrern” aus der Kategorie “Hardware” in eine neue Kategorie “Elektrowerkzeuge”, kann enorme Auswirkungen haben – im Guten wie im Schlechten – auf die Produktkategoriestruktur einer Website, was möglicherweise zu einer 404’ing einer früheren URL-Struktur führt und viele defekte Links auf verweisenden Websites erzeugt.
Der eCommerce Growth Consultant Luke Carthy hat ausführlich über Themen rund um SEO von Auslaufprodukten geschrieben und gesprochen, und seine Leitfäden sind es wert, gelesen zu werden, wenn Sie im eCommerce tätig sind.
Die Bedeutung des Verständnisses von externen Links bei der Site-Migration.
Es gibt viele Gründe, warum eine Website zwischen Hosts migrieren oder die URL-Struktur ändern möchte, die ihre Inhalte bereitstellt. Im Jahr 2014 unterzog sich Majestic einer Markenänderung und zog dabei von majesticseo.com zu majestic.com um. Ein weiterer Grund für die Migration einer Website ist der Wunsch, die Technologie zu wechseln, vielleicht von einem CMS zu einem anderen.
Bei diesen bewussten, geplanten Migrationen machen die meisten Leute nur einmal den Fehler, einen SEO nicht einzubeziehen. Wenn diejenigen, die eine Site-Migration durchführen, den Wert der bestehenden URLs auf der bestehenden Site nicht verstehen, ist es wahrscheinlich, dass eine große Anzahl von 404s generiert wird. Stellen Sie sich vor, Sie spülen Ihren gesamten externen Referral-Traffic in die Tonne, weil Ihr Content von “/blog” nach “/news” wandert und niemand eine Weiterleitung einrichtet.
Doch auch wenn Fehler passieren, wird bei vielen Site-Migrationen ein Tool wie Majestic eingesetzt, um externe Links vor, während und nach der Migration zu verstehen:
- Vor einer Migration erstellt ein Site-Audit eine Liste von Schlüsselseiten mit einflussreichen externen Links, die erhalten werden können
- Eine Migration kann mehrere Monate dauern. Wenn eine neue Website oder Technologie implementiert wird, kann es einige Zeit dauern, bis eine bestehende Site, die sich ihrerseits verändert, aufgeholt hat. Regelmäßige Überprüfungen der Links zur bestehenden Site können dazu beitragen, dass es während der Migration nicht zu Störungen kommt.
- Nach einer Migration lohnt es sich, ein erneutes Audit durchzuführen, um sicherzustellen, dass nichts übersehen wurde, und sicherzustellen, dass alle 404er, die durch einen Fehler eingeführt wurden, behoben werden, bevor ein Konkurrent versucht, seine Links aufzubauen, indem er die Verweise anderer Leute auf Ihren fehlerhaften Inhalt übernimmt.
Die technische SEO-Spezialistin Faye Watt hat einen SEO-Leitfaden für Website-Migrationen zusammengestellt, der auf der BrightonSEO vorgestellt wurde. Einige Assets werden auf der Website der Seeker Digital Agency hier präsentiert: https://seeker.digital/seo-guide-website-migrations
Zusammenfassung
Defekte Links sind ein wesentlicher Bestandteil der Funktionsweise des Webs. Die offene Natur des Webs lädt Menschen dazu ein, auf Inhalte und Produkte zu verlinken, die sie interessant oder bemerkenswert finden.
Zu verstehen und zu würdigen, wie geschäftliche Entscheidungen wertvolle organische Verweise beeinflussen können, ist wichtig für SEO und effektives Content- und Produktmanagement. Überlegen Sie, ob es sich lohnt, einen SEO-Plan zu erstellen, der regelmäßige Audits beinhaltet für:
- Defekte Links auf Ihrer Website
- Traffic auf Seiten, auf denen möglicherweise eingestellte Produkte angeboten werden
- Sicherstellen, dass 404-Seiten als Ausweichmöglichkeit hilfreich bleiben
Es kann eine Chance sein, über die Strategie hinauszugehen, 404-Seiten zu reparieren, wenn sie auftauchen. Wenn Sie in der Lage sind, mit den relevanten Teams in einem Unternehmen in Kontakt zu treten, kann es sein, dass Traffic generiert werden kann, indem ähnliche URLs verwendet werden, um Ersatzprodukte für eingestellte Produktlinien zu verkaufen oder um kreative Verwendungsmöglichkeiten für Inhalte über eingestellte Produkte zu finden. Dies ist ein Bereich, in dem Sie kreativ werden können! Es gibt eine Reihe von Möglichkeiten, Daten zu bewahren oder darzustellen – ein leuchtendes Beispiel ist das “Canon Camera Museum”, das Informationen über Kameras von vor kurzem bis vor vielen Jahren enthält.
Wenn Sie Hinweise oder Tipps haben, von denen Sie denken, dass sie diesem Leitfaden helfen könnten, lassen Sie es uns bitte in den Kommentaren unten oder über unser Support-System wissen.
- Wie SEO und SEA effektiver zusammenwirken können - May 6, 2026
- Wie man für den Google AI-Modus optimiert - March 4, 2026
- Erweiterte Filter im gesamten Site Explorer verfügbar - January 29, 2026