





HTTP status codes can seem nerdy and geeky, but can have significant real-world effects on policy and strategy that go WAY beyond SEO.
We’ve seen a lot of 404 guides, and not all of them are that great. Majestic has years of experience in crawling and mapping the world wide web. We wanted to share some of the knowledge we’ve built up with YOU in a guide that explains:
- 404s & missing pages Explained
- How to find 404s on your own site
- Why you may want to know about broken pages on competitor pages
- How 404 errors can impact business strategy
We’ve tried to include links to third party content sources to help boost your understanding to the next level. There are some awesome resources out there. We have not included any Affiliate links, so any inclusion is on merit rather than as a part of some deal.
Our guide will take you through the basics of what a 404 is to looking at ways to take advantage of 404 pages. At the end of this guide we look towards strategy
404 Primer
In this section of the guide, we will look at “404 Page not found” basics.
Read on to discover:
- What a 404 status code means?
- What causes 404s?
- What 404 pages look like?
- Why are 404s important for SEO?
What is an HTTP 404 status code?
In simple terms, a 404 indicates that a webpage that’s been asked for doesn’t exist on a website.
More technically, 404 is one of a family of http status codes (more properly standard response code) that indicates “Page not found” or “File not found”. Both HTTP and HTTPS web servers can return 404 errors.
Why am I seeing a 404 message?
A 404 error indicates that a page is not found on a website. Typically, this happens through one of two means:
- The user clicks on a “broken link”, which promises to take the user to an interesting page on a different website.
- A user types in a website and page into a web browser address bar which doesn’t exist
There is also a third type of “hidden 404”. While you may experience a 404 by clicking on a broken link, a webmaster or server administrator, you may find 404s in server logs when a computer program tries to access a “missing resource” on a website.
Let’s look a little deeper into each.
Broken Links
A broken link is simply a link that points to a page that isn’t there. This can happen for a number of reasons; some are:
- Content has been moved or removed on the “linked to” site since the link was created
- The person who put the link in made a mistake
- Someone is working on the website and temporarily removed a page
When looking at broken links, its important to consider WHERE the broken link is from, and WHERE the broken link points to.
In SEO terms, the page that contains the referring link is called the Source page.
The page the link refers you to is called the Target.
If the broken link has a source and target on your own site, then good news! As long as you know the source and target pages, you can resolve the problem. We will look into a more refined strategy later in the post, but for now, you could consider removing the link from the source page, linking it to somewhere else on your site, or trying to put up ( or back ) relevant content where the broken link points to.
If the source page is on your site, and the broken link’s target is on someone else’s site, an easy way out might be just to remove the link totally. However, before doing that, it may be worth considering if the outbound link from your page helps people reading your site. Sometimes it can be good to find an alternative authority site to link to, or seeing if the page has moved on the target site.
If you find the broken link’s target on your site, but its pointed/derived from a different site, then that’s the Source of the link and its important to proceed with caution.
It can be tempting to reach out to the owner to ask them to change their link to “fix” it. Be careful! This is often the wrong course of action as you’re asking someone else to do work that benefits you for free.
Rather than asking someone else to fix a broken link to you, consider fixing it yourself! You may be able to fix a broken link from a third party site by adding a “redirect” to where the broken link points to on your site. This redirect could seamlessly bounce your visitor to relevant content on your own site. The exact way of implementing a redirect varies from platform to platform, but your webmaster or content management system provider should be able to advise on how to add redirects to your site.
You may think that broken links on someone else’s site that points to a site that’s not yours isn’t any of your business. However, if you have good enough content, this form of broken link building can be a valuable form of Digital PR. An opportunity you can grasp is taking advantage of broken links that point to another site (that’s not yours) and build links with them. This form of broken link building can be a valuable way to gain Digital PR.
Read on to learn more.
Typed in URL
Many people rely on search engines like Google to find relevant content, so why would anyone type in a 404?
There’s few reasons.
Print Media has not disappeared. Hashtags, handles and URL’s on printed materials are commonplace. While Covid has seen a rise of QR codes as businesses seek to go contact free, copying and pasting a URL from print still happens.
Marketers should be aware of three potential sources of mistyped URLs:
- Typos on publicity material
- Human error when producing publicity material
- People trying their luck or “exploring”
Many organisations now have some degree of signoff process around printed material covering the digital aspect, but errors do occur. If URLs are to be used on print material, they should be short and memorable – ideally with no more than one word after a slash – as exemplified by Google’s chrome adverts in the United Kingdom, inviting people to visit “google.co.uk/chrome”. It should go without saying that Billboards and leaflets are no place for tracking parameters or UTM codes.
This leads us into our second point. Human beings make mistakes. If a URL is publicised, it makes sense to ensure it is short, unique and memorable, even if the resulting URL is redirected to a longer URL. If the URL is essential to your business ( like a menu ), consider a QR code or link from your homepage to accompany any URL. The URL “example.com/menu” is easier to type, remember, and more problem free than example.com/get-menu or example.com/spring-menu. Punctuation needs treating with care: Hyphens, underscores and spaces can be especially problematic.
The final error – human beings exploring is hard to differentiate from people making mistakes. While repeated attempts at failed URLs can be cause for concern, it is often just the case of someone who is curious doing the digital equivalent of staring through your window to see your wares. If your business model depends on hiding things on the public internet, it may benefit from careful consideration.
404s as missing resources
Developers and webmasters may find reports of missing 404 content in Server logs – records kept by web servers on page views and errors. Not all are the result of users visiting the site. Most website owners probably don’t need this level of detail, but for the curious, there are some established URLs that programs visit as a normal part of web operations.
Some common resources that are requested are:
- Robots.txt – “Good” web crawlers (like the Majestic crawler) should check to see if a “robots.txt” file is present on a server before crawling. They instruct the crawler which parts of the site should and shouldn’t be crawled and how often the crawler should download pages.
- Favicon – a little logo that your web browser can display in a tab when your site is being visited
- Sitemap – some additional suggestions to web crawlers on how content can be discovered and monitored for change
There are other, more esoteric resources that may generate 404 errors. While its important to consider if you need the three files above, not all 404s are worthy of concern.
Its worth adding there are web crawlers out there that probe sites for insecure problems or vulnerabilities. For this reason, webmasters should exercise extreme care to secure a webserver and think about data management policies around it. Its sad to say that to some extent, coping with bad bots and securing your site is part and parcel of running a website. Its quite a hassle but coping with bad bots whilst securing your website is part of running a website.
What does a 404 page look like?
404 pages vary. The Status code “404” is transmitted by the server direct by your web browser. Sometimes, a page containing the message “Not Found” followed by the message “The requested URL was not found on this server” is returned, such as the one below:
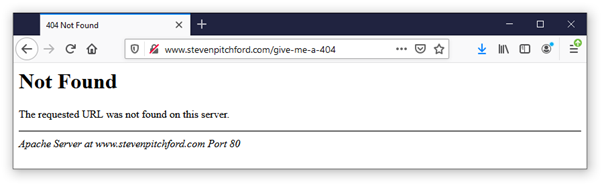
This is a page that is returned for 404s by default from the popular Apache Web server. In this example, site owner is yet to configure their Apache webserver to supply a custom 404 page.
Many site owners choose to set a custom 404 page, meaning that some times more pretty pages will be returned, such as this one from Majestic:

If you are interested in seeing more examples of crawled pages, OnCrawl have compiled a list of some of the best 404 pages they have found.
How do I make a 404 page?
There are lots of reasons why you may want to make a 404 page, good UX (User Experience) likely being one of them. The exact means of configuring a 404 page depends on your webserver and content management system, but essentially, a 404 page is designed like any other web page is. The Google Advanced SEO Guide outlines some suggestions to consider for your 404 page design:
- Make it clear to the user that the page cannot be found, but be nice!
- Ensure the branding and navigation of your 404 page is consistent with the rest of your site.
- Think about the/your user – add useful links to popular resources to your 404 page.
- Think about providing a way for users to report a broken link.
- Prevent 404 pages from being indexed by Google and other search engines by making returns an actual 404 HTTP status code.
These are useful guidelines, but may open up a range of further questions. A lot of the advice focuses around UX, which is understandable as this may be the first time the visitor has ever seen your website if they have come from an external broken link.
Rather than repeat words expressed better elsewhere, Wire-framing tool, JustinMind has produced a UX focused guide to 404 pages, examining important aspects as brand aesthetic and serving user need. The guide is a valuable resource for designers and SEO’s alike.
Are 404 pages bad?
No! We’ll go into the science behind this later, but 404 pages are not bad – like so many things in life, a missing resource on a web server is a near-inevitable event which happens from time to time.
That said, if your site is causing 404s then its not great. A broken link on your site or to your site can represent an unpleasant bump in your users journey. A badly positioned missing page could be the cause of lost sales.
It’s important to differentiate broken links and missing pages. Missing pages that generate 404s are simply a by-product of the way the web is put together. To a certain degree they are inevitable. However, missing pages can present new opportunity as well as maintenance overhead.
A real-world parallel to a 404 page could be someone phoning a business you run and asking if you do a certain product or service you don’t have available, or in other words, an enquiry for an unstocked item.
Some businesses will see that as annoying. Others will see it as an opportunity. Trying to come up with a one size fits all approach to out of stock items would take skill and thought. The same is true of 404 pages.
Do all webservers issue 404 error pages when a page is missing?
As with so many things in SEO, it depends!
When you’re looking at “404” or “Page not found” pages, its important to note that what you see as a 404 page may not be a real 404 page.
When a web browser asks a web server for a webpage, the webserver returns two chunks of data, an HTTP header and an HTTP body.
The HTTP body is a unique form of HTML code that controls what is displayed in your browser.
The HTTP header includes special control signals that your browser understands but doesn’t pass onto you.
The 404 status code is found in the HTTP header section of the data. There are lots of other status codes, such as “200”, which means all is good and even “418”, which is described as “I’m a teapot” (https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/418). 418 is a great example of nerd humour creeping into web standards. Fortunately, most web standards are a little more robust and practical.
Back to 404 codes and headers. Because web servers are very configurable pieces of software, webmasters can configure them to do a number of different actions when a missing page is detected. Skilled webmasters can go beyond Custom 404 pages and perform actions such as redirecting the user elsewhere or returning a 200 message to tell the web browser that the page is ok while delivering a message to the user suggesting the page is missing.
Why would someone go to such lengths to hide a missing page?
As with so many things in SEO, there are trends, and fashions in recommendations, perhaps triggered by suggestions from the digital marketing community, or sometimes by rumour.
A few years ago, there was a lot of debate if 404s were good or bad, with the result that some sites decided to try not to return any 404s what so ever. This approach is generally seen as a bit extreme now, as 404s are a naturally occurring phenomenon and arguably nothing to be ashamed about.
Another aspect is crawl budget. A search engine’s crawler only has so many resources to throw at your website. Soft 404s can take a lot of crawler resources up as it makes a site near infinite in size.
What do 404 pages have to do with SEO?
Content can only be indexed if it is present, and content helps search engines discover new links. If you accumulate a lot of broken links and 404 pages, this can lead to:
- a loss of visibility of your site
- a poor user experience for your customer
- potentially decreased revenue for your business
There is some debate as to how much Google cares about 404 pages and broken links and to what extent these factors may influence ranking. However, internal and external links are seen to play an important role in prioritising content. A blend of concern over ranking, and commercial impact ensure that understanding 404s and strategies to mitigate them remain part of the SEO skillset.
An SEO can help discover broken links and missing pages on your site, fix these issues with relevant content, and capitalise on missing content on third party sites in outreach campaigns that assist the visibility of your site.
Finding 404 errors on your own site
You should now have an understanding of what a 404 error is and why fixing them may be necessary. We will now look at a range of tools and techniques to help you find 404 errors on your site and competitor sites, before looking at some ways to fix 404s and avoid creating 404s in the future.
Clicking around your website
While viewing your website as a user can be great for UX insight, unless your site is tiny, its a poor way of finding 404s.
Manually visiting every page on your site is time consuming, likely to be prone to error and a really questionable use of your time! Tools like Screaming Frog, Site Bulb and Majestic can deliver lists of broken links and the 404 pages they point to easier, faster, and almost always more cost effectively than a human being.
An issue with manual checks, which is shared with the kind of “automated link clicking” that some crawling services provide, is that not all your 404 pages will be linked to!
A custom crawl of your own site will often find broken links in your content, but may miss valuable content that other people link to and is now missing on your site.
Because qualified, third party traffic is a valuable resource, these external links can be worthy of investigation, regardless of the value search engines place upon it.
Log file analysis
Google Search Advocate John Mueller has gone on record as saying “Log files are so underrated, so much good information in them.” (https://www.seroundtable.com/google-log-file-analysis-21919.html).
So what are Log files, and what do they have to do with SEO?
When your web browser displays a web page, it first needs to download the webpage from a web server. The web server is a computer program running somewhere that “serves” webpages.
These webpages are either stored as HTML files, or are the result of a computer program. The webserver calls a computer program when more complex actions are needed on a website, such as running searches, display a product catalogue or add things to baskets.
As well as being responsible for the delivery of websites, webservers keep records of activity known as “Log Files”. These log files often contain the IP address of the visitor and the web browser they are using, together with the page requested and the status code returned by the web server.
Logfiles analysis can tell you:
- Which pages are being downloaded the most
- When Googlebot has visited your site
- When pages are requested that don’t exist on your site ( which result in a 404 status code )
- And more…
However, log file analysis is not a silver bullet. The data is raw, can contain a lot of noise from automated software and can take skill to analyse – it may not be the best approach for beginners!
Using Majestic
For many sites, Majestic Site Explorer makes light work of finding 404 errors. Simply type in your site’s name, choose the “Pages” tab and click on “Crawl Result”. Selecting “HTTP 404 Not Found” will reduce the returned data to only contain pages that returned 404 pages when Majestic last examined them.
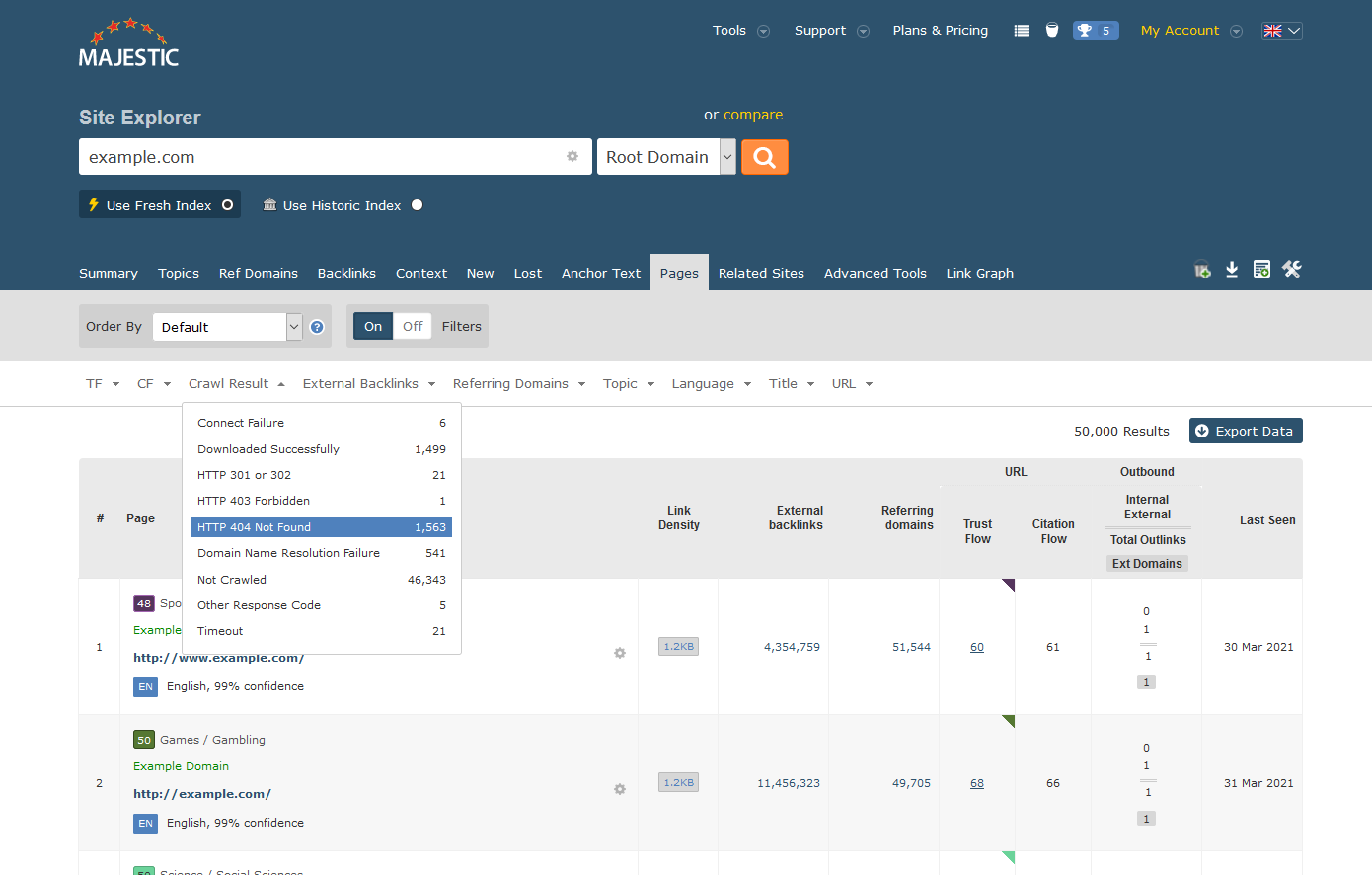
You can do this easily for sites you control, and, as we will see later, the same technique also works on competitor sites where an outreach strategy may help build your brand visibility.
If you are finding 404s on your site – the most straight forward way is to download your list straight into Excel and use metrics like Trust Flow or referring domain counts to prioritise manual resolution of broken links. See our “How to fix broken links on your site” guide below for more details.
Other tools
There are a number of platforms out there that can help you find 404s on your own site. Two popular ones are Google Search Console, and Screaming Frog – a versatile custom crawler.
How can broken links to a competitor sites help me?
Organic referrals from authority sites can be a source of qualified visitors who are likely to engage. Regardless of how highly popular Search Engine Ranking algorithms rate relevant, organic links, your site could benefit from link based visitor referrals.
One potential source of links is to find competitor content that has been removed, but still has links pointing to it. You may then be able to reach out to the people that link to the missing content.
Broken Links can be a goldmine. All you need to know to exploit 404 pages on other people’s sites are:
- WHO has linked to the missing content?
- WHAT content is now missing?
- IF you have relevant content that might be helpful to people viewing the site?
You will need a few tools to help you with identifying links:
- Majestic – helps you find who links to what
- Web Archive – helps you find out the missing content
- Google – helps you find relevant content on your site
- A means of reaching out to people you want to help
There are a range of ways of reaching out to people, with varying opinions on the merits of individual and automated outreach. rather than try to suggest a “one size fits all strategy”, we suggest you research and find out what works for you and your business!
Using Majestic to find broken links on third party sites
If you know your industry and the sites around it, using Majestic is straight forward. Just repeat the process used for finding errors on your own site with Majestic. Use Site Explorer, click on the pages tab and choose “HTTP 404 Not Found” errors in filters. This will list pages that our crawlers found were missing.
Majestic can also find links to the broken pages found above, which we cover in our guide to finding 404s using Majestic.
Assuming you can find broken links to deleted pages, some SEO’s suggest that there is merit in reaching out to people who link to the deleted pages and, assuming you have content that serves the same purpose, asking them to link to you instead.
The next stage is to find out what was on the page. To do this, we use a time machine to travel back in time to see what the page used to look like! Or, to put it another way, at this point, the Internet Archive’s WayBack Machine at https://archive.org/web/ can be invaluable!
Use WayBack Machine at the Internet Archive to Discover what’s been deleted
The WayBack Machine is a huge repository of content that has been crawled from the web over a number of years. It gives you the ability to view online content from months, even years ago.
The WayBack Machine boasts an archive of over 545 billion web pages and is easy to explore. Simply copy and paste each URL from your missing pages spreadsheet into the search box on the WayBack Machine, and click “Browse History” to Explore.
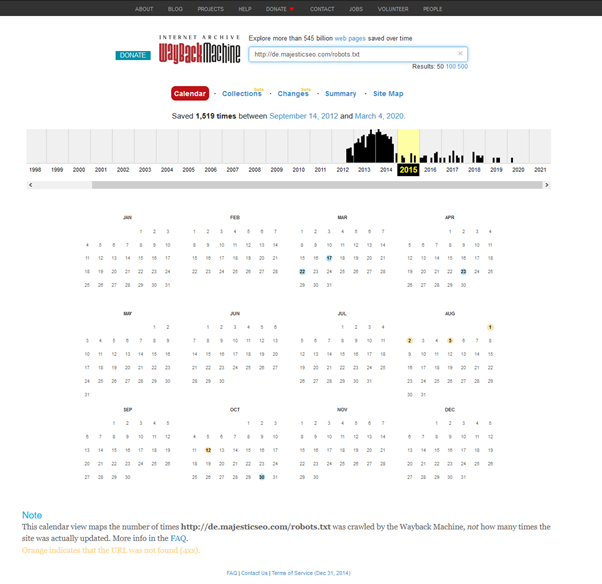
The WayBack machine presents itself as a calendar. Typically, the blue circles will let you access content, green indicates a redirect and orange a 404.
You can then use this to establish what the content used to look like, with a view to determining IF someone who would link to this content might be interested in a replacement, and to assess if there’s anything on your site that could be worth linking to in its place.
Use Google to find relevant content on your own site
Having looked into, and investigated opportunities to “pitch your alternative content” to people with broken outbound links, its well worth seeing if you have content that a reasonable person could consider a valid alternative.
The “site:” operator in google can help with this process, as it limits google searches to a website of your choice. You may wish to explore a few different potential pages by repeating these steps until you have found missing content on a third party site for which you have an existing replacement. By making notes and recording pages that are missing you can help build a knowledge bank which could contribute to your future content strategy.
Strategies to reduce the number of 404 errors occurring in the future
There is no “one size fits all” process of reducing 404 errors. There is a lot to be said for regular Majestic SEO extractions of client and competitor data to ensure the opportunities above are seized on an ongoing basis.
In-house SEOs may face different challenges to agencies and consultants in terms of the roles they play and ears they can bend in order to achieve the necessary leverage in an organisation to adopt SEO aware policies.
Let’s dive into some of the areas.
Ecommerce – 404 Errors and product strategy.
Product life-cycle management is an area where business strategy, business operations, SEO and CRO overlap substantially. While achieving change can be difficult when so many stakeholders are involved, there are potential revenue-boosting gains to be had if alignment can be achieved.
Ecommerce sites are often driven by data in the form of product catalogues. It’s understandable that for many businesses, the product catalogue’s focus is on the products for sale today, rather than the ones on sale tomorrow or yesterday.
Understanding the link between your product catalogue and your website and how the natural life-cycle can impact your website visibility online can boost your bottom line.
One of the basic tenants of discontinued product SEO is that people can continue to search for a product after it is no longer for sale, and retailers may benefit consumers by retaining product listings and offering alternative products on the respective pages. This approach is generally considered to be investigative rather than prescriptive, as there will often be a number of potentially business-specific matters impacting product range retention.
Another aspect of data-driven product catalogues is where the product hierarchy is generated from a backend system and possibly maintained by someone without SEO experience. What seems like a simple change of moving “drills” from “hardware” to a new “powertools” category can have a huge impact – for better or for worse on the product category structure of a website, potentially 404’ing a previous URL structure and creating many broken links on referring websites.
eCommerce Growth Consultant Luke Carthy has written and spoken extensively on matters around SEO of discontinued products, and his guides are well worth a read if you are in e-commerce.
The importance of understanding External Links in Site Migration.
There are many reasons why a site may wish to migrate between hosts or change the URL structure that serves its content. In 2014, Majestic underwent a brand change, and in the process moved from majesticseo.com to majestic.com. Another reason a site may undergo migration is a wish to change technology, perhaps moving from one CMS to another.
In the case of these deliberate, planned migrations, most people will only make the mistake of not involving an SEO once. Unless those undertaking a site migration understand the value of the existing URLs on the existing site, it is likely that a large number of 404s will be generated. Imagine flushing all of your external referral traffic down the pan because your content moves from “/blog” to “/news” and no-one sets up redirects.
However, while mistakes happen, many Site Migrations will use a tool like Majestic to understand external links before, during and after a migration:
- Before a Migration, a site audit creates a list of key pages with influential external links that can be preserved
- A Migration may last several months. If a new website or technology is being implemented, it may take some time to catch up an existing site which in turn may be changing. Regular reviews of links to the existing Site can help ensure a lack of disruption during migration.
- After a Migration it’s worth running a fresh audit to ensure nothing has been missed, and ensure any 404s that have been introduced by error are resolved before a competitor attempts building their links by taking other people’s referrals to your broken content.
Technical SEO specialist Faye Watt put together an SEO’s guide to website migrations which was presented at BrightonSEO, with some assets presented on the Seeker Digital Agency site here: https://seeker.digital/seo-guide-website-migrations
In conclusion
Broken links are a fundamental part of the way the web works. The open nature of the web invites people to link to content and products they find interesting or noteworthy.
Understanding and appreciating how business decisions can impact valuable organic referrals is important for SEO and effective content and product management. Consider if its worth creating an SEO plan that includes regular audits for:
- Broken links on your site
- Traffic to pages that may have discontinued products on
- Ensuring 404 pages remain helpful as a fall-back
There can be opportunity in going beyond a strategy of fixing 404s as they emerge. If you are able to engage with the relevant teams in a business, it may be that traffic can be generated by using similar URLs to sell substitute products for discontinued lines, or to find creative uses for content about discontinued products. This is an area you can get creative in! There are a number of ways of preserving or representing data – a shining example being the “Canon Camera Museum” which has information on cameras from recent to many years ago.
If you have hints or tips you think could help this guide, please let us know in the comments below, or via our support system.
- How To Deal With Fake DMCAs - July 29, 2026
- What Makes A Successful SEO Podcast? - June 24, 2026
- What Can SEOs Learn From Brand Strategy Experts? - May 26, 2026