






Una encuesta reciente realizada por Incapsula sobre la actividad de los bots me ayudó a reunir una serie de ideas acerca de por qué crawlear inteligentemente es mucho más importante que crawlear rápido.
Incapsula ha estado realizando este informe durante varios años. Tanto los novatos como algunos expertos pueden alarmarse al notar que solo la mitad del tráfico de sus webs pertenece a gente real.
Este post muestra algunas de las consecuencias de la carrera por el Crawl, su impacto en la calidad de lo indexado y algunos intentos de spammers para frustrar a los bots. Y sí, voy a mostrar una técnica de red de enlaces. Una manera realmente estúpida de lanzar una alerta.
Buenos bots y Malos bots

Incapsula ha identificado que la mayor parte del tráfico bot viene de 35 crawlers “buenos” (incluyendo Majestic) y unos cuantos bots malos, los cuales no vamos a reparar mucho en ellos hoy.
Aunque, es relevante que algunos sistemas de firewall poco sofisticados bloquean ciertos bots a través de User Agents sin dar alternativas a sus clientes, esto es desaconsejable. He aquí el impacto relativo de cada bot en el ancho de banda global de internet.
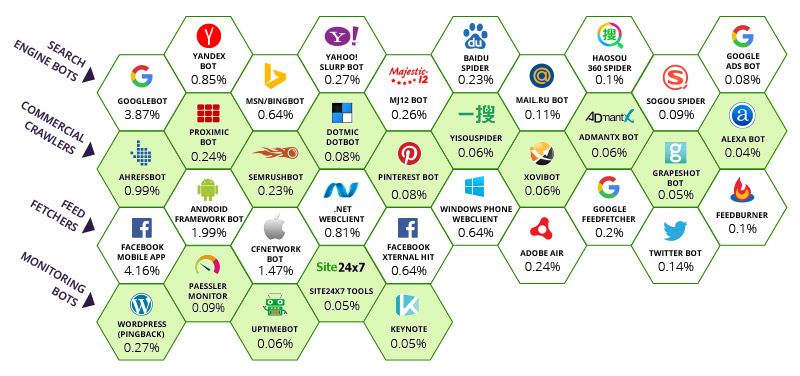
El número debajo de cada bot representa el porcentaje de visitas a las páginas supervisadas que fueron atribuidas a cada bot. En lo alto, la aplicación móvil de Facebook captura un enorme 4,16% del ancho de banda. Google tiene un 3,87% de la totalidad mundial de ancho de banda. Actualmente, incluso más, cuando miras el resto de bots que también son de Google. Esto es, diría yo, más que suficiente. Google y Facebook han sido fundamentales en ayudar a conservar ordenado, conectado y navegable, un sistema que de otro modo sería caótico.
Claramente la primera fila de motores de búsqueda tiene eso en común, aunque Majestic está agradecido a Incapsula por categorizar Majestic como un motor de búsqueda de primer nivel. Vemos que tenemos numerosos “colegas” en segunda fila donde Majestic no hubiera desentonado.
Como crawler en el top ten, basándonos en la tabla de arriba, Majestic tiene la responsabilidad tanto de crawlear como de saber cuándo PARAR de hacerlo. Hay un gran interés en las comunidades SEO por conseguir “todos” los enlaces o al menos, tantos como sea posible. Esto crea una paradoja. ¿Cuándo parar de crawlear internet?
La web infinita
Las últimas travesuras que involucraban a Majestic y a la estación espacial internacional no eran un truco publicitario. Eran parte de resaltar la naturaleza infinita de Internet. Este infinito, tiene profundas repercusiones para las herramientas de enlaces. Hace unos cuantos meses, Majestic eliminó billones de webs de su crawl. Estas eran páginas subdominio que habían sido generadas automáticamente. Esto causó un buen revuelo para unos cuantos domainers que estaban usando el trust flow de las versiones “www” del dominio (lo que técnicamente es una variante del subdominio) para evaluar webs y vender el dominio en mercados especulativos. Esta pirámide de Lego ayuda a entender y visualizar el dilema:

Imagina que esta pirámide representa todos los subdominios de internet. Los que se encuentran arriba del todo tienen un Trust Flow de 90-100 y los que se encuentran abajo del todo un TF de cero. De hecho…Majestic fue descubriendo que los subdominios en la base eran algo inferior a cero en sus valores de TF. No tenían enlaces entrantes de ningún lado más que del mismo dominio raíz y empezaban a ser tan numerosos que no contaban… El algoritmo de TF de Majestic mantenía algo parecido al patrón de la pirámide, por tanto, cuanta más basura en la parte de abajo, mayor el Trust Flow de algo incluso remotamente mejor que el spam.
Pero esto es un problema inabarcable, un crawler no puede solucionarlo simplemente crawleando más. Todo lo que conseguía es hacer que el siguiente peldaño de la pirámide se viese mejor de lo que debería y aun no podríamos tener nada parecido a contar con “todos” los enlaces, porque nada dividido entre infinito todavía no es un gran porcentaje. Majestic podría tener instalaciones de servidores del tamaño de campos de futbol, que aun así no sería capaz de resolver el problema. De hecho, Majestic decidió eliminar los dos escalones de abajo. En la imagen de arriba de la pirámide de Lego, estos dos escalones representan más de la mitad de los datos! (36 de los 70 ladrillos = 55%). Cada uno de ellos equivale a una página que nadie vio y ningún buscador que se precie debiera crawlear.
El efecto fue redimensionar la pirámide. De repente, los sitios que estaban en el tercer peldaño de una escala 1-100 estaban en el peldaño inferior. Te puedes imaginar el pánico que hubo en la comunidad de dominios y que puedes leer en los comentarios de este post.
Esta no es la única manera en la cual una internet infinita se ha ido creando. Majestic.com en si misma (y cualquier motor de búsqueda) crea potenciales loops infinitos simplemente a siguiendo su forma de trabajo principal. Pueden introducir cualquier puñado de caracteres aleatorios en Majestic.com y el sistema se las ideará para interpretar los resultados. Esto, a su vez, crea páginas de resultados (SERPs, Search Engine Results Pages) lo que a su vez, crea enlaces. Estos enlaces deberían enlazar a páginas que ya existen, por lo que es un círculo cerrado, pero la url de búsqueda en si misma puede ser infinita en su naturaleza. Majestic (y Google) ayuda a otros motores de búsqueda a mostrar esto y ambos hacen uso de sus archivos robots.txt para decir unos a otros que no deberían perder sus valiosos recursos crawleando estas URLs infinitas.
Los Spammers duplican el problema
El comienzo de este post indicaba que iría sobre una “técnica de red de enlaces”. No es algo que normalmente haga, pero esta red era particularmente estúpida y particularmente dañina hacia MJ12Bot. Empecé este post indicando también que los User Agents eran opcionales. Majestic elige identificarse por sí mismo, sin ocultar su identidad. Si quieres que Majestic NO crawlee tu web, usa entonces Robots.txt para esas instrucciones. No hagas como esta red de enlaces, realizando un 301 (redirect) al bot de Majestic a su propia página de inicio. El efecto es una alerta interesante en mi bandeja de correo, mostrándome una brutal inyección de enlaces a Majestic.com:
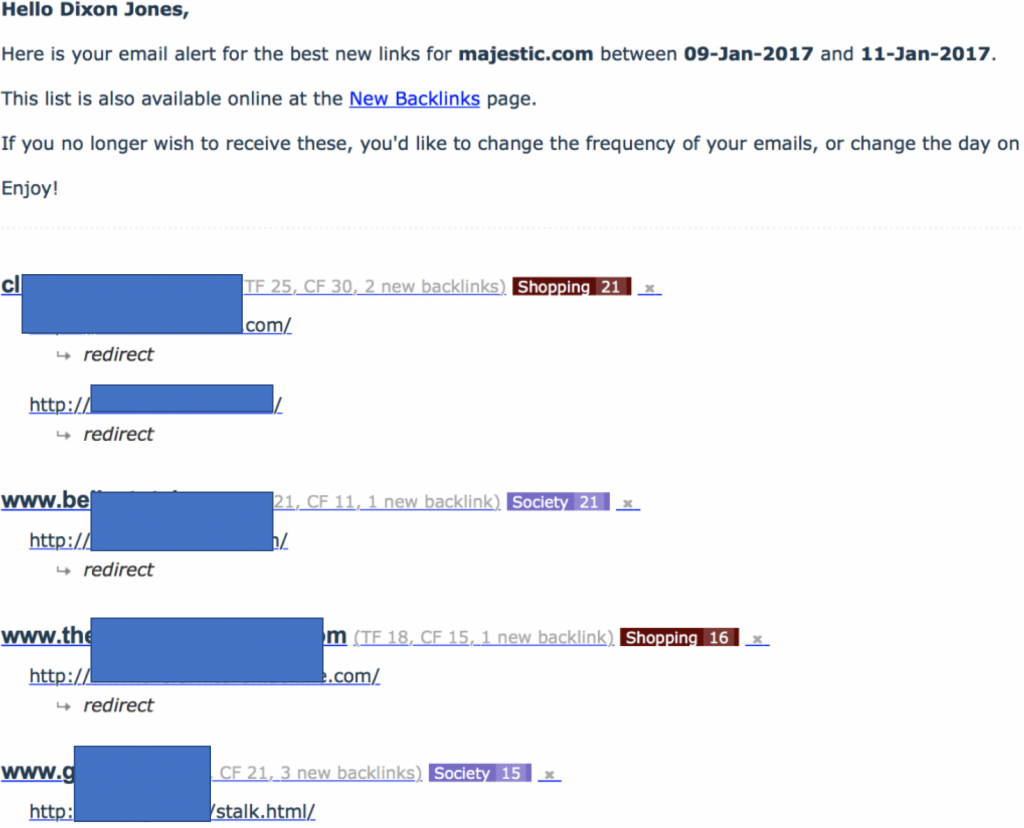
Date cuenta que todos los enlaces nuevos encontrados a Majestic.com fueron aparentemente redirecciones desde esas webs. Esto fue la alerta, porque cuando miré las webs, eran claramente granjas de enlaces pero no estaban enlazando a Majestic. Esto significa que tenían que estar ocultando contenido a nuestro bot, haciendo cloaking a nuestro MJ12Bot. Me divertí particularmente cuando la red empezó a usar nombre de archivo como “stalk.html” Cuando miré esas páginas en un navegador normal todas parecían algo así:
Los User Agents son opcionales
El último paso en este trabajo era saber qué estaba pasando al usar un tercer elemento como herramienta para verificar que la red estaba haciendo una redirección 301 basándose en el user agent. Si echas un vistazo a “Http Header Checker” puedes hacerlo por ti mismo, pero es especialmente útil usar SEOBook’s Header Checker o puedes usar Screaming Frog ya que ambos te dejan cambiar el user agent en un desplegable. Es muy simple, esas webs estaban haciendo cloacking por User Agent. Si Googlebot o una persona llega, verán la página que ves más arriba. Si llega el MJ12bot, verá la propia web de Majestic a través de redirecciones 301.
Volver a que los Crawlers sean responsables
La propia red nos pone un desafío. Esto hace que un crawler mire dos IP, no una. Esto puede no ser significativo, dado que en este caso una web es spammer y la otra es Majestic, pero es destacable que las redirecciones 301 no son perfectas. Están teniendo cada vez una mayor carga en internet. Una manera más eficiente de redirigir este tráfico podría ser usar un Alias de dominio, pero esto causa otros problemas para los motores de búsqueda, como que el dominio canonical (preferido) no puede ser identificado desde las tablas DNS por sí solas.
Por lo tanto, con la infinidad de webs con la cantidad de re-direccionamientos y todo tipo de maneras de sostener la eficiencia de un rastreador, se convierte en ilógico el seguir intentando crawlear spam…incluso aunque solo sea para eliminar enlaces de spam. Un enfoque mucho más práctico es conseguir suficientes datos sobre la web para ver algunos enlaces de cada dominio y entonces mover ficha. El truco está en NO volver a remover la basura…si la basura está a nivel de página con infinitas páginas o a nivel subdominio con infinitos subdominios o está a nivel página con infinitas duplicidades, resultados de búsqueda o redirecciones.
Para hacer esto, los crawlers que pueden crawlear de manera más inteligente son capaces de consumir menos recursos en la web que otros que crawlean más rápidamente. Crawlear de manera más inteligente funciona si el crawler es capaz de entender cualquiera de estos elementos:
- ¿Es una página importante?
- ¿Se actualiza o es estática?
- ¿Es autogenerada?
- ¿Es Spam?
En particular, Majestic es bueno en las observaciones superiores e inferiores. Las métricas de Flow dan a Majestic una ventaja sobre otros bots y en este caso hablo sobre Bingbot. Tengo claro que Bingbot es más agresivo que Majestic, pero no tengo tan claro que haga falta serlo. Tal vez Bing no tenga un métrica como Trust Flow o PageRank (si todavía se usa) para ayudar al proceso de crawleado, pero no creo que ellos descubran significativamente más páginas como resultado de crawlear un 250% más rápido que MJ12Bot. Lo mismo pasa con nuestros colegas en la segunda línea del gráfico de Incapsula.
La mejor aproximación, al menos para Majestic, es crawlear lo suficiente para ser capaces de encontrar todos los dominios raíz de referencia que enlazan a una web y entonces demostrar y enseñar los suficientes enlaces desde esa web para nuestros usuarios, de esta manera identificar la naturaleza del patrón del enlace. Una manera muy sencilla para nuestros usuarios de ver esto es en la pestaña de Referring Domains. Pon tu dominio y ordénalo por número de enlaces, de más a menos, y podrás ver el número de enlaces por dominio, aquí puedes bajar hasta debajo de la pantalla y obtener información instantánea. Aquí está el sitio de Majestic.com:
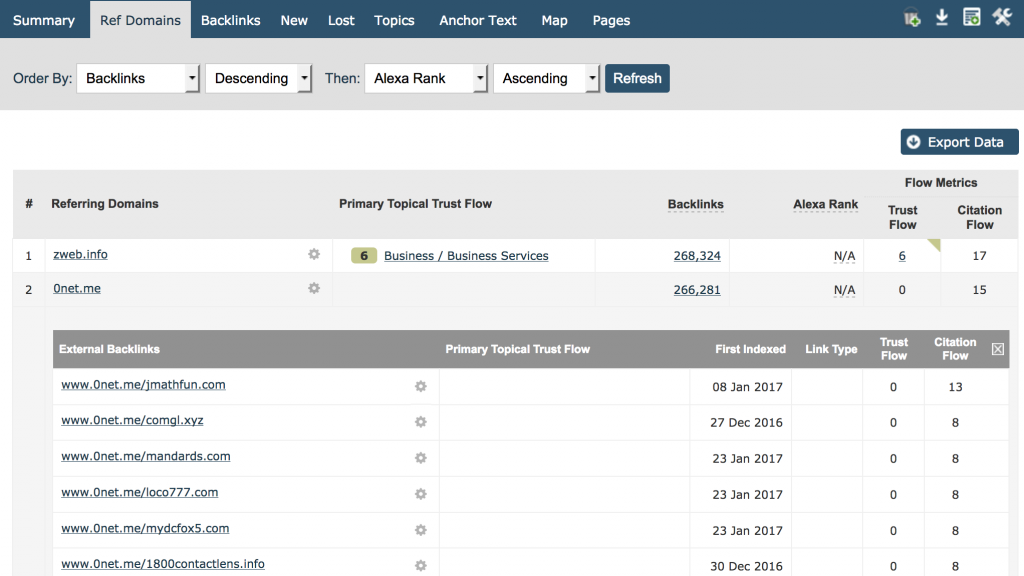
Creo que estaremos todos de acuerdo en que 266.281 enlaces desde www.0net.me no nos cuenta demasiado más que si dijéramos que tienes 100.000 enlaces desde www.0net.me!
La pestaña de Ref. Domain es perfecta para identificar rápidamente algunos de los peores links de spam en tu web. Es también muy útil en este post para identificar zonas donde el bot podría llegar a ser más inteligente y por tanto más eficiente en su crawleo.
Los hosting baratos matan

Nota: la frase “El trabajo bueno no es barato y el trabajo barato no es bueno” es de Norman ‘Marinero Jerry’, un famoso tatuador que acuño esta frase y que aparece en posters y camisetas y puedes buscar su historia en internet.
Otro problema que los bots agresivos pueden causar es cuando hay demasiadas webs en el mismo servidor. Desafortunadamente los hosting baratos ven más a los bots como un problema que los hostings más robustos. Esto es porque los hosting baratos tienden a poner cientos, sino miles, de pequeñas webs en el mismo servidor físico (máquina). Puedes utilizar Majestic’s Neighbourhood Checker para ver cuantas webs están en tu mismo servidor. Majestic obedece al Crawl Delay que dicta robots.txt, pero esto también se está convirtiendo en una medida inteligente que diferencia más los diferentes tipos de webs que hay en estos servidores. Es algo que también te afecta, sobre todo, si te preocupa Google. Por que Googlebot no obedece al crawl delay! A pesar de que usan un límite por servidor para determinar el ratio máximo de crawleo por cada máquina para no causar stress en ese servidor. Si tu servidor tiene otras 1.000 webs, seguro que alguno tendrá miles de páginas más que tú, en la misma máquina y deberías preguntarte, a ti mismo ¿qué parte del crawleo de Googlebot en tu servidor va a mirar tu web?
El arbol de decisiones para tener un Crawleo inteligente
Ahora ya tenemos un número de elementos que puede ayudar al crawler a gestionar mejor sus propios recursos y por tanto reducir el impacto en internet. Es un reto que ha creado una situación Win-Win. Mejor información. Internet más rápido.
Decisión 1: Descubrimiento vs Integridad
Con el fin de mantener un índice web del tamaño que tiene Majestic, el tiempo es un destructor natural de la integridad de los datos. Cada segundo que pasa, nuevo contenido es creado, pero también contenido ya creado es eliminado o modificado. Imagina que en medio segundo…Majestic tiene que elegir qué crawlear después… ¿una URL que nunca ha crawleado, o una que crawleo ayer?. ¿Qué elegiría? ¿La nueva? ¡Genial! Pero, ¿qué pasa con la siguiente elección? ¿y con la siguiente?
Nosotros hemos identificado ya el concepto de la web infinita, por tanto esta lógica es defectuosa si nunca se revisa de nuevo un enlace para ver si la web ha cambiado o se ha caído. Majestic se cargó esto en 2010 y lo ha resuelto de más de una manera. Si los bots de Majestic se entusiasman por descubrir siempre nuevos sites, frente a mantener la integridad de los que ya tenemos, entonces tendríamos un Fresh Index a prueba de fallos, porque tras 90 días, una página que no ha sido recrawleada podría caerse del índice por completo. Esto significa que el Fresh index nunca tendrá información que sea de más de tres meses de antigüedad. Afortunadamente, como siempre, raramente pasa…al menos no con páginas que la gente le importe…porque nuestra métrica de Flow nos ayuda a priorizar en una manera más compensada, por tanto esas páginas importantes pueden ser revisitadas con mayor frecuencia que las menos influyentes. Si Majestic solo tuviese en cuenta el número de enlaces para tomar estas decisiones, entonces el ancho de banda necesario debería incrementarse significativamente.
Decision 2: Crawlear profundamente
¿Cuantas páginas son suficientes? ¡Un directorio de spam tiene más páginas que la BBC! Pero seguramente la BBC necesita que TODAS sus páginas sean crawleadas ¿verdad? Bueno, no necesariamente. La BBC produce noticias las cuales, por su naturaleza, se convierten en noticias viejas con el paso del tiempo. Finalmente el hecho deja de ser noticia y … llega un punto en que hasta la BBC eliminaría esa página. Antes que eliminarla, la BBC trata de dejar huérfanas estas páginas, de esta manera aún puedes encontrarlas con un buscador o a través de un tercer enlace. El problema se hace aún más complicado en webs como eBay o Mashable donde el contenido es generado por los usuarios y hay una línea gris entre calidad y cantidad. Aquí las Métricas Flow metrics ayudan muchísimo.
Otras herramientas en la industria del SEO son capaces de emplear otras técnicas para tomar esta decisión. En concreto pueden coger un proxy para “calidad” scrapeando las SERPs de Google a escala y entonces usar la puntación de visibilidad para ayudar a tomar la decisión. No tengo conocimiento de cuando lo hacen, pero dado que ellos ojean la información de las SERPs a escala, tendría sentido si tomasen esto como una señal.
Pero últimamente, hemos necesitado de nuevo proteger nuestros crawlers del problema del internet infinito. Necesitamos evitar crawlear el mismo sitio (o servidor) tanto que afecte a la latencia para los usuarios reales.
Decisión 3: Qué descartar
Iba a poner esta sección con el titular “¿Cuántos discos duros comprar?”, pero definitivamente esto no es una decisión teórica que deba tenerse en consideración. Habiendo entendido que el problema de crawleo es infinito, la pregunta ha de ser “qué descartar”. Qué información en el crawl no tiene sentido y por tanto simplemente no debe ser crawleada en primer lugar – excepto tal vez en un intento de sacar otro mal contenido – con la intención de remover el cáncer de la información. Esto es lo que Majestic ha estado consiguiendo durante los últimos meses y los efectos han sido impresionantes todo sea dicho de paso. Tan pronto como esto se convierta en un factor, entonces el desafío para crawlear más rápido se convertirá en irracional.
- Nuevas funciones: enlaces salientes y actualización para los idiomas - October 26, 2017
- New: Métricas de enlaces Outbound con títulos y más cosas - October 16, 2017
- Majestic y SEMrush unen sus fuerzas - October 11, 2017