





Przedstawiam dziś bardzo przyzwoitą metodę, dostosowaną dla dużych stron internetowych, polegającą na odkrywaniu linków prowadzących do strony, a które obecnie zwracają kod odpowiedzi 404. Wykorzystując kilka narzędzi, można pozyskać setki a nawet tysiące linków, które wystarczy tylko odzyskać.

Jak zaznaczyłem na wstępie, metoda jest dostosowana do dużych projektów/dużych stron internetowych. Kiedy strona jest duża? O dużej stronie myślę wtedy, gdy posiada:
- kilkaset tysięcy lub więcej adresów URL indeksowanych w wyszukiwarce,
- kilkaset tysięcy lub więcej linków kierujących do strony,
- kilkadziesiąt tysięcy linkowanych adresów URL w obrębie całej strony.
Do przeprowadzenie całego procesu potrzebne są narzędzia jak:
- Majestic Site Explorer
- Arkusz kalkulacyjny, np. Excel
- Notepad++ z dodatkiem TextFX
- Screaming Frog
Pierwszym krokiem jest utworzenie raportu zawierającego wszystkie linki prowadzące do strony. Dlaczego nie mógłbym skorzystać z Konsoli Wyszukiwania, która powinna zawierać najdokładniejsze informacje o przychodzących linkach? Z powodu ograniczeń dostępności danych.
Konsola Wyszukiwania pozwala pobrać tylko listę 1000 adresów, do których prowadzą linki. 1000 adresów w dużym projekcie to często mniej niż 1% całej zawartości strony internetowej, zatem te dane nie będą przydatne. Ponadto, nawet gdyby spróbować wykorzystać tę listę adresów, może się okazać i zazwyczaj tak jest, że wszystkie z nich zwracają kod odpowiedzi 200. Google akurat tak układa tą listę, by wszystkie adresy na niej działały. Mówimy także o sytuacji, w której mamy dostęp do Konsoli Wyszukiwania, a powiedzmy sobie szczerze, że przy dużych projektach to bardzo czasochłonne a czasami nawet niemożliwe aby otrzymać dostęp do tak wrażliwego zasobu danych.
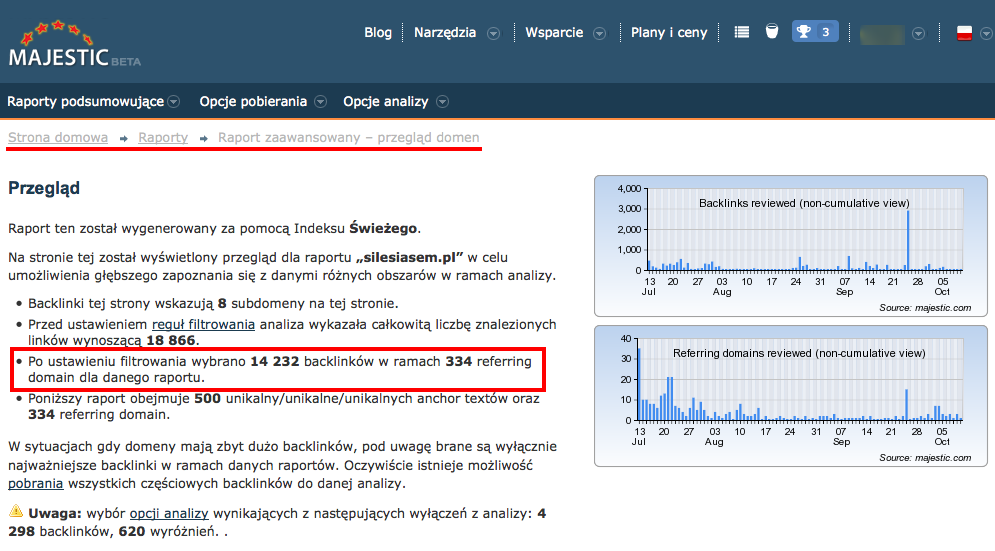
Raport przygotowuje z wykorzystaniem Majestic Site Explorer, pobieram spakowany plik CSV z informacją o wszystkich linkach. W moim przypadku zawiera listę ok 270 tysięcy linków i po rozpakowaniu waży 70MB.
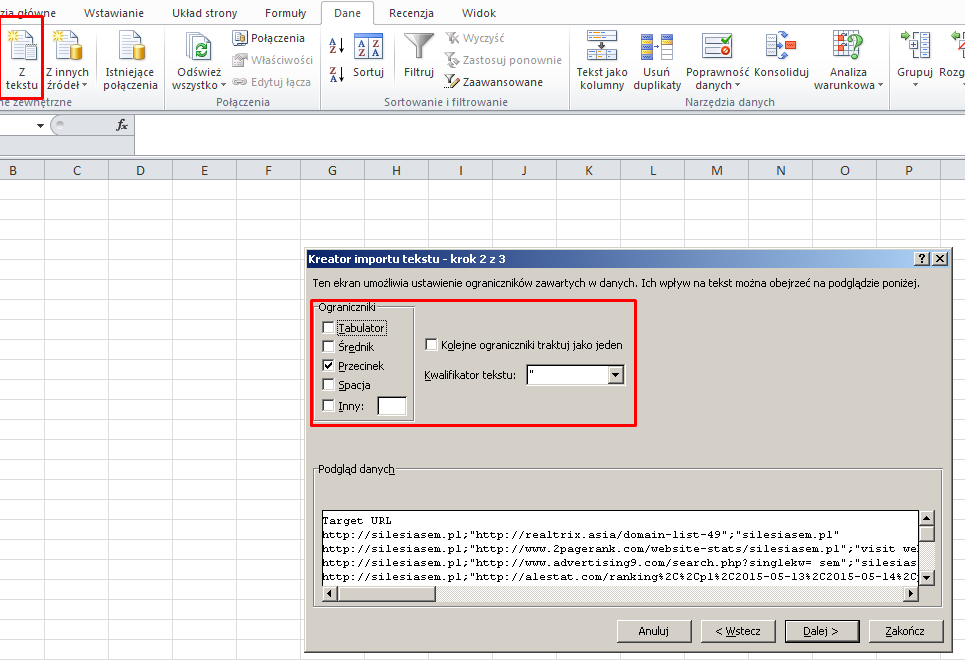
W drugim kroku otwieram plik CSV tak, aby dane rozdzielane przecinkami trafiły do osobnych komórek i całość zapisuje w formacie XLSX. Poprawne otwarcie można wykonać poprzez następujące czynności w programie Excel:
- Utwórz nowy pusty arkusz.
- Wybierz z menu Dane polecenie “Z tekstu”.
- Wskaż jako źródło rozpakowany plik eksportu z Majestic Site Explorer
- W kreatorze importu tekstu wybierz typ Rozdzielany
- Jako ogranicznik wybierz znak przecinka (,)
- Jako kwantyfikator tekstu wybierz znak cudzysłów (“)
Dzięki temu łatwiej jest potem pracować z tą listą danych i szybko wyszukiwać właściwe ciągi znaków.
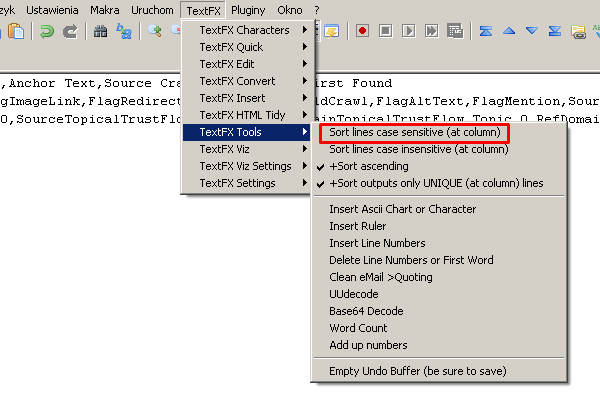
W trzecim kroku za pomocą Notepad++ i dodatku TextFX oraz metody Kopiuj/Wklej przerzucam całą kolumnę A, w której znajdują się linkowane podstrony i wybieram polecenie posortowania wszystkich podstron z zachowaniem tylko unikalnych adresów. Na liście zostaje ok 32 tysięcy adresów. Listę zapisuje do osobnego pliku tekstowego, np. z rozszerzeniem .txt.
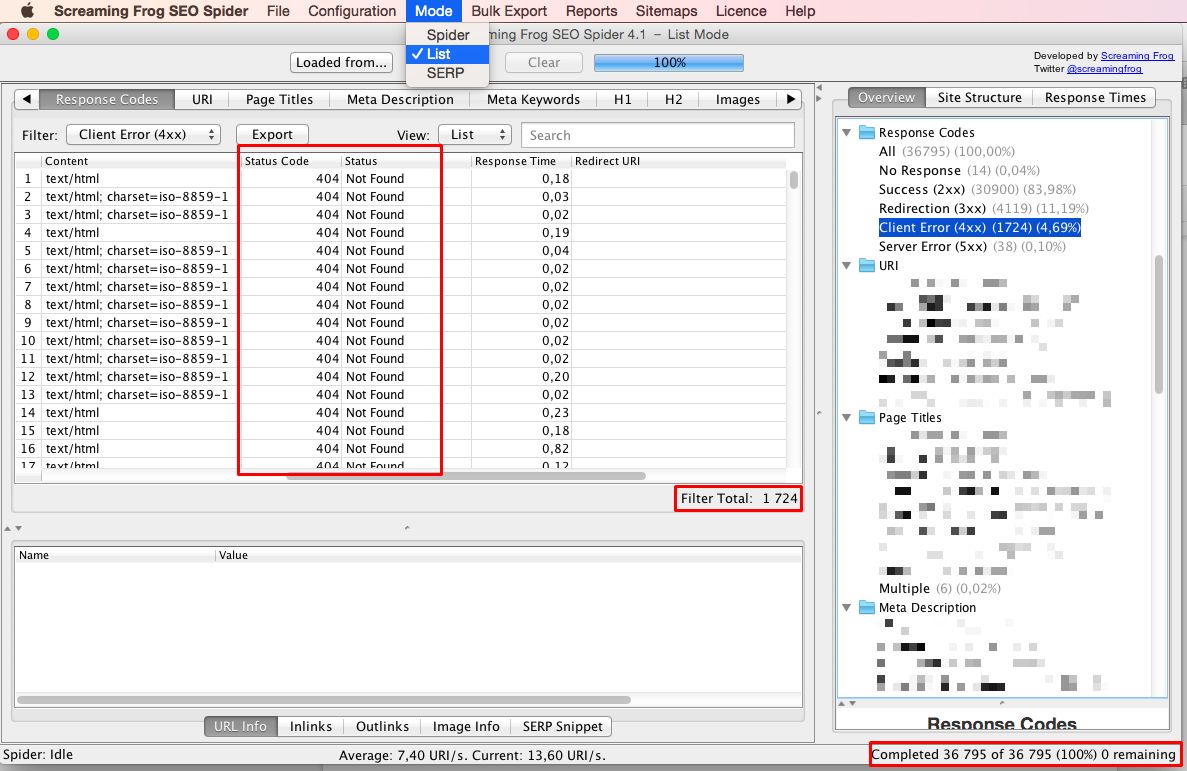
W czwartym kroku wykorzystuję Screaming Frog do którego jako wejściową listę adresów do przeskanowania wstawiam utworzony plik w kroku trzecim. Screaming Frog ma za zadanie odwiedzić wszystkie 32 tysiące adresów i zwrócić mi kody odpowiedzi serwera. Naturalnie zakres pobranych danych jest o wiele większy, ale na potrzeby tej metody wystarczą tylko dane z części Response Codes. Jeśli pojawią się strony, które zwracają kod 404, oznacza to, że linki prowadzą donikąd i bot wyszukiwarki Google nie bierze ich pod uwagę przy tworzeniu rankingu.
Przed uruchomieniem skanowania programem Screaming Frog ustawiam jeszcze w opcjach aby program podążał za przekierowaniami. W przypadku gdy napotka np. przekierowanie 301 lub 302 ma iść za nim do końca. Pełny skan przygotowanej wcześniej listy doprowadził do odwiedzenia ponad 36 tysięcy adresów i ujawnił, że istnieją 1724 adresy zwracające kod 404.
W tym momencie zaczyna się najtrudniejsza część odzyskania linków. Przed podjęciem kroków prowadzących do ich odzyskania, należy odkryć przyczyny powstania stron zwracających błąd 404. W moim przypadku akurat nie usuwano celowo żadnych stron z obrębu całej domeny a jedynie nieaktualnych było tylko kilka landingów. Nie tłumaczy to jednak tak wielkiej liczby błędów 404 do których prowadzą linki.
Rozpoczynam od analizy wzrokowej adresów, które ten błąd zwracają. Następnie wyszukuję te adresy we wcześniej zapisanym pliku XLSX i odwiedzam miejsce położenia takiego linku. Wykonuję to adres po adresie i za każdym razem opisuję powód powstania błędnego linku. Do najczęstszych powodów powstawania błędnych linków zaliczają się:
- przypadkowe usunięcie ostatniego, bądź kilku ostatnich znaków z adresu URL,
- przypadkowe dopisanie jednego znaku do adresu URL, np. jednego ze znaków znajdujących się w okolicy klawisza Enter,
- wielokrotne cytowania i kopiowania postów na forum internetowym, po takim cytowaniu oraz ponownym kopiowaniu adres URL zawiera w środku ciąg “[…]”,
- błędne rozpoznawanie znaków przecinek (,), myślnik (-) oraz apostrof (‘) w adresach URL przez silniki for internetowych.
Zebrane informację pozwalają odkryć nie tylko wyżej przytoczone powody powstania błędnych adresów w wyniku działania osób trzecich ale także szereg innych, które powstały w wyniku działania zespołu inhouse.
Karkołomnym zadaniem byłoby przygotowanie 1724 reguł i wstawienie ich do pliku .htaccess aby przekierować te strony w miejsca, na których mi zależy. Nie wspominam już o braku dostępu do tego pliku bądź serwera jeśli chciałbym to zrobić sam.
Dlatego najlepszym rozwiązaniem jest opracowanie zbiorczych reguł przekierowujących, z których każda będzie pokrywała jeden zidentyfikowany problem. Na przykład:
- wszystkie przypadki zawierające “[…]” w ciągu adresu URL należy przekierować tu,
- wszystkie przypadki zawierające znak “]” na końcu adresu URL należy przekierować tam,
- itd.
W czasie analizy wzrokowej zaczynam już dostrzegać powtarzające się reguły, toteż z czasem nie muszę sprawdzać każdego przypadku tylko od razu go przyporządkowuje do danej reguły i sprawdzam dalej.
Dzięki tej metodzie do tego projektu opracowałem kilkanaście reguł, które można zapisać w backendzie silnika strony i będą pilnowały aby przekierować linki ze stron 404 tam gdzie będę chciał.
Metoda działa tak samo dla średnich projektów, jednak nie zwróci już tylu możliwości odzyskania linków, przeważnie będzie to kilkanaście lub kilkadziesiąt linków.
Dla małych stron i małych projektów można skorzystać z informacji znajdujących się w raporcie Błędy indeksowania w Konsoli Wyszukiwania. Pojawi się tam lista maksymalnie 1000 adresów, które zwracają kod odpowiedzi 404 oraz przy każdym z nich będzie informacja, z jakich innych stron prowadziły linki do tego adresu. Niestety w przeważającej liczbie przypadków będą to zawsze linki wewnętrzne, prowadzące z innych miejsc w obrębie tej samej strony. Poprawienie tych błędów z pewnością wpłynie pozytywnie na postrzeganie całej strony przez wyszukiwarkę, jednak nie sprawi, że zacznie płynąć moc z odzyskanych linków.
Jeśli interesujesz się tematem odzyskiwania linków, to sprawdź szkolenie online, które prowadzę z zakresu odzyskiwania linków z wygasłych domen. Zobaczysz wykorzystanie tych samych narzędzi co wyżej ale w całkiem innym kontekście i zastosowaniu.
- Schyl się i podnieś linki, które leżą na ziemi - October 19, 2015
Ja mogę dodać, że prezentowana metoda jest omawiana na szkoleniach przez Artura – zawsze na szkoleniu z audytów SEO Artur "grzebie" w robotach 🙂 Fajna robota 😉
October 19, 2015 at 9:43 amA nie próbowałeś kontaktować się z właścicielami stron z prośbą o aktualizację linków? W przypadku pojedynczych linków do błędnych adresów, może się udać je zaktualizować bez potrzeby 301, a dopiero jeśli jakieś linki pojawiły się na większą skalę, wtedy można byłoby ustawić przekierowania. Nawet takie działania można zautomatyzować (freshmail czy fump), jeśli ktoś się na to mocno uprze.
Wiem, że to bardzo czasochłonne, a efekty są różne, ale sama staram się zaczynać właśnie od tego. Podobnie w przypadku niepodlinkowanych adresów (w Majesticu powinna być jedna flaga informująca o niepodlinkowanej wzmiance), ale tam dużo trudniej jest namówić do ich podlinkowania – a bo polityka firmy tego zabrania, a bo aktywne linki są płatne itd. 😉
October 19, 2015 at 10:01 amW opisanym wyżej przykładzie, lepsze efekty można osiągnąć, gdy zastosuje się rozwiązania po własnej stronie – ponieważ są one w stanie ogarnąć więcej występujących błędów. Kontakt w sprawie pojedynczych linków zostawiłbym na później, gdy już grubsze błędy, niemożliwe do poprawienia przez osobę (np, błędne linki na forach) są rozwiązane.
October 19, 2015 at 12:34 pmDobrze czytam? Rozchodzi sie o 404 w obrębie własnej domeny?
October 23, 2015 at 2:26 pmTak. A dokładniej o znalezienie backlinków prowadzących do podstron z błędami i próbę ich odzyskania.
October 24, 2015 at 6:43 amRok temu napisałem sobie skrypt który wszelkie wywołania nieistniejących adresów w obrębie strony przechwytywał i dawał mi cynk na e-mail o takowych. Właściwie jego zastosowanie miało inne założenie a to było efektem bardziej ubocznym ale gdyby przechwytywać info skąd użyszkodnik/bot przychodzi to wszelkie wywołania nieistniejących adresów można "łapać" i tworzyć w locie jakieś stronki lub robić 301… Z tym, że wtedy przestaje istnieć 404 – jak to odbiorą boty? To raczej nienaturalne 😉
November 25, 2015 at 4:38 pm