






Jednym z ważnych aspektów technicznego SEO, który nadal jest wykorzystywany i rozwijany przez Google, są dane strukturalne. Ich podstawowym zadaniem jest ułatwienie wyszukiwarce zrozumienia treści i kontekstu strony internetowej. W swoim artykule przedstawiam najważniejsze zagadnienia związane z danymi strukturalnymi, a także skupiam się na najczęściej popełnianych błędach przy ich wdrażaniu.
Czym są dane strukturalne?
Dane strukturalne to model, za pomocą którego możemy dodatkowo opisać i zorganizować informacje na stronach internetowych. Sposobów na rozszerzenie kontekstu i poprawienie dostępności stron internetowych może być kilka (np. ARIA, HTML5, Open Graph), jednak w SEO przyjęło się stosowanie głównie schema.org.
W przypadku SEO najchętniej wykorzystywanymi elementami są te oznaczenia schema.org, które honoruje Google. Zgodnie z dokumentacją wyszukiwarka rozpoznaje około 30 typów danych strukturalnych. Liczba własności rozpoznawanych dla każdego z nich jest wskazana na podstronach dokumentacji, chociaż w wielu wypadkach nie wyczerpuje i nie opisuje wszystkich elementów dostępnych na podstronach schema.org.
Skąd pomysł na schema.org?
Pomysł na stworzenie schema.org powstał w 2011 roku. To wtedy, dzięki współpracy największych wyszukiwarek (Google, Yahoo!, Microsoft i Yandex), powstały podwaliny tego projektu.
W tamtym czasie sam kod HTML nie przekazywał żadnych dodatkowych informacji poza nadaniem struktury elementom przedstawionym na stronie internetowej. W związku z tym naturalne wydawało się stworzenie standardu, który rozszerzałby możliwości interpretacji zawartości stron internetowych. Poza inicjatywą schema.org dostępne były takie rozwiązania jak Microformats (dalej działające) czy Data Vocabulary (informacje, że znaczniki przestały być wspierane przez Google dostępne tutaj i tutaj).
Dlaczego warto korzystać z danych strukturalnych – schema.org?
W większości przypadków korzystanie z danych strukturalnych jest powiązane z wyszukiwarką Google. Podstawowy cel to wyświetlanie elementów rozszerzonych na podstronach SERP-ów lub zwiększenie prawdopodobieństwa ich wyświetlania w wynikach rozszerzonych.
Innym ważnym elementem dodawania i poprawiania danych strukturalnych na stronach i podstronach internetowych jest chęć wyeliminowania błędów i ostrzeżeń, które systematycznie pojawiają się w Google Search Console. Kolejnym celem jest poprawienie stopnia rozumienia strony przez roboty wyszukiwarki.
Wykorzystując dane strukturalne schema.org, chcemy:
- przedstawić zależności pomiędzy elementami na stronie internetowej i poza nią,
- poprawić możliwość interpretacji zawartości strony internetowej,
- zwiększyć czytelność strony internetowej,
- podać definicje elementów ze strony internetowej.
W ostatnim czasie dodatkowym powodem, dla którego wielu webmasterów oraz specjalistów SEO angażuje swój czas i zasoby w poprawianie i rozwijanie danych strukturalnych, jest chęć poprawienia E-A-T (E-E-A-T) strony internetowej, podstrony, konkretnego wpisu lub autora. Za pomocą wielu typów i właściwości danych strukturalnych można przedstawić robotom Google wiele danych i powiązań danych, do których być może sama wyszukiwarka nie dotarłaby.
Podsumowując, korzystanie z danych strukturalnych pozwala na:
- wykorzystanie potencjału rozszerzonych wyników Google,
- naprawienie błędów, które zostały zwrócone w narzędziu Search Console,
- poprawienie poziomu rozumienia witryny przez roboty wyszukiwarek internetowych.
Jakie dane strukturalne honorowane są przez Google?
Google systematycznie zwiększa liczbę danych strukturalnych, które aktywnie wykorzystuje w swoich wynikach wyszukiwania do prezentacji wyników rozszerzonych. Pełna lista typów danych strukturalnych schema.org dostępna jest na końcu artykułu, natomiast wśród najczęściej wykorzystywanych przez Google można wymienić:
- Article (Article),
- Menu nawigacyjne (BreadcrumbList),
- Firma lokalna (LocalBusiness),
- Logo (Organization),
- Product (Product),
- Fragment opinii (Review, AggregateRating),
- Pole wyszukiwania z linkami do podstron (WebSite).
Jakie mamy formaty danych strukturalnych?
Istnieją trzy sposoby na wdrożenie danych strukturalnych:
- JSON-LD (JavaScript Object Notation for Linked Data) – zalecany sposób wdrożenia schema.org,
- Mikrodane,
- RDF.
Praktyka wskazuje, że najczęściej wykorzystywane są Mikrodane oraz JSON-LD. Nie zaleca się stosowania jednocześnie kilku sposobów wdrożenia, jednak wyszukiwarka jest w stanie poprawnie odczytać dane strukturalne, gdy zostały one dodane jednocześnie jako JSON-LD oraz Mikrodane.
Mikrodane to kod, który jest dodawany na poziomie konkretnego elementu HTML. Wdrożenie polega na dodaniu znaczników do kodu HTML. W uproszczeniu wygląda następująco:
<div itemscope itemtype=”https://schema.org/Article“>
Z uwagi na pojawiającą się czasami trudność w rozbudowaniu kodu HTML konkretnego elementu (ewentualnie z powodu braku danych lub niechęci do pokazania pewnych informacji), spotykanym rozwiązaniem jest stosowanie tagu <meta>, w którym podaje się znaczniki schema.org, a sam tag nie znajduje się w sekcji <head> strony internetowej.
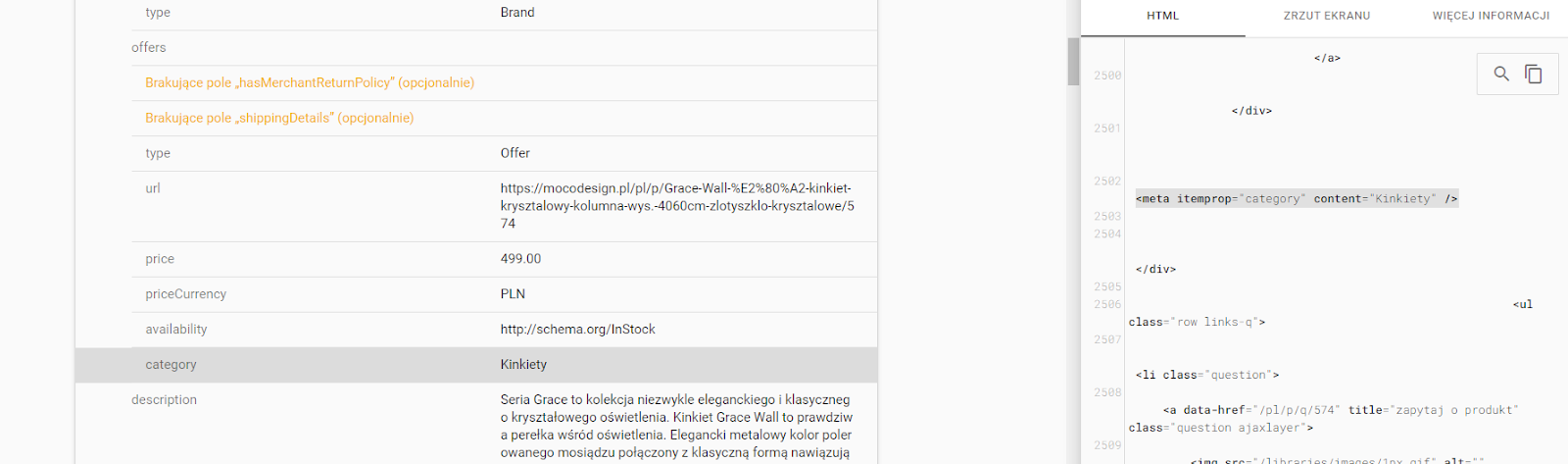
Przykładowe wykorzystanie tagu <meta> (tutaj) w powyższym celu:
<meta itemprop=”category” content=”Kinkiety” />
JSON-LD jest metodą wdrożenia schema.org, która daje ogromne możliwości i ma wiele zalet. Najważniejsze z nich to różne możliwości wdrożenia kodu, wdrożenie w dowolnym miejscu strony internetowej oraz to, że kod JSON-LD jest znacznie czytelniejszy.
Dane strukturalne – je jak wdrożyć?
Obecnie dostępnych jest wiele metod, które pozwalają na wdrożenie danych strukturalnych schema.org na stronie internetowej. Najpopularniejsze możliwości wdrożenia to:
- skorzystanie z pluginów do systemów CMS, które automatycznie wzbogacą stronę internetową o dane strukturalne,
- dodawanie danych strukturalnych z poziomu edytora tekstowego i bloków HTML – można tak zrobić w systemie WordPress,
- dodawanie elementów bezpośrednio w kodzie strony lub szablonie serwisu,
- skorzystanie z Google Tag Managera.
Dobór metody wdrożenia danych strukturalnych powinien być uzależniony od celu oraz możliwości technicznych.
Sprawdzenie poprawności danych strukturalnych
Poprawność wdrożenia danych strukturalnych można na bieżąco monitorować za pomocą dwóch narzędzi online. Pierwsze z nich to test wyników z elementami rozszerzonymi od Google, drugie narzędzie to Walidator Schema.org.
W przypadku testowania danych trzeba pamiętać o tym, że test Google weryfikuje tylko dane strukturalne, które są wykorzystywane przez Google, natomiast Walidartor Schema.org sprawdza poprawność wszystkich wdrożonych typów.
Wyraźnie to widać w przypadku niektórych wdrożeń. Dla przykładowego adresu URL: https://kia.eurokas.pl/samochod/automat-od-reki/ test walidatora schema.org wykrył następujące typy:
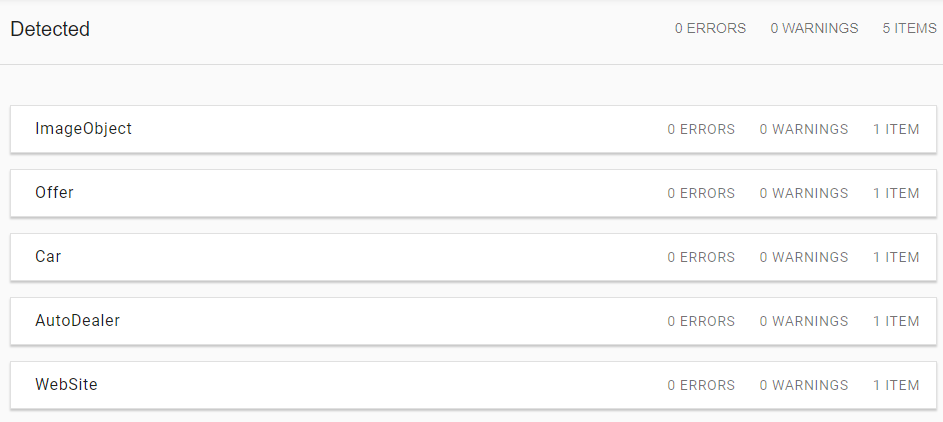
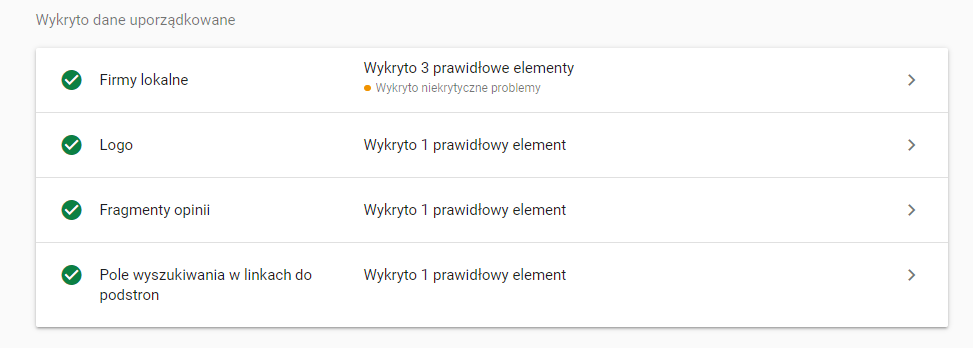
Test Google nie wykrył w ogóle typu Car, zamiast typu AutoDealer podaje, że AutoDealer to „Firma Lokalna”. Nie widzi też ceny auta w typie Offer.
Jak szybko dane strukturalne są wykrywane przez Google?
Dane strukturalne są często sprawdzane przez Google, a po ich wdrożeniu stosunkowo szybko pojawia się informacja o nich w Search Console. W serwisie HelpHero.pl już następnego dnia po wdrożeniu danych strukturalnych pojawiły się dodatkowe ulepszenia w Search Console. Na wykresie wyraźnie widać systematyczne odkrywanie kolejnych elementów oznaczenia w podstronach serwisu.

Gdzie szukać inspiracji dla schema.org?
W planowaniu rozbudowania danych strukturalnych schema.org można korzystać z dokumentacji Google, dokumentacji schema.org oraz z działań konkurencji. Aby zidentyfikować najważniejszą konkurencję w wynikach wyszukiwania, warto skorzystać z danych przygotowanych przez Senuto. Dla każdej sprawdzanej domeny narzędzie w prosty i czytelny sposób pokazuje inne domeny o zbliżonym profilu słów kluczowych, z którymi rywalizuje serwis.
Wygląda to następująco:
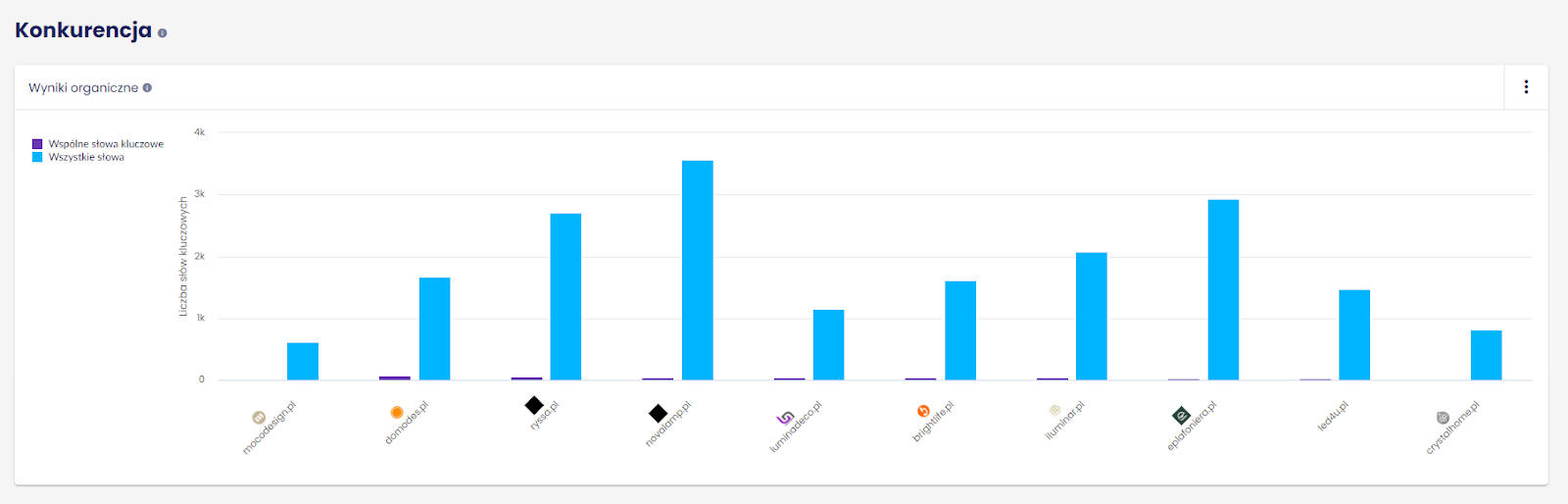
Podczas analizy widoczności nieocenionym wsparciem w kontekście rozszerzonych wyników Google będzie zakładka „Cechy fraz”, w której zebrane są informacje o trudności słów kluczowych, liczbie wyszukiwań, trendach oraz o wynikach rozszerzonych.
Najczęstsze błędy spotykane we wdrożeniach schema.org
Podczas wdrażania danych strukturalnych łatwo popełnić błąd. Najczęściej występują błędy krytyczne, błędy niekrytyczne, niezgodność z dokumentacją Google lub schema.org. Poniżej zaprezentowane są typy schema.org, w których najczęściej pojawiają się te nieprawidłowości.
SearchAction
Zgodnie z informacjami w dokumentacji Google typ SearchAction (Pole wyszukiwania w linkach do podstron) powinien zostać wdrożony wyłącznie na stronie głównej, jednak powszechnie spotyka się strony, które ten typ mają wdrożony w całej witrynie.

LocalBusiness
Zgodnie z dokumentacją Google oraz informacjami ze strony schema.org typ LocalBusiness powinien być wykorzystywany tylko do konkretnych oddziałów lub dla lokalnych firm. Często zdarza się, że przedsiębiorstwa działające na większym obszarze korzystają z typu LocalBusiness zamiast z typu Organization. Trzeba tutaj jednak wskazać, że w samej dokumentacji nie zostało sprecyzowane, kiedy dany typ powinien zostać wykorzystany.
W przypadku LocalBusiness warto poszukać podtypu, który najlepiej odpowiada działalności biznesowej, np. Restaurant zamiast LocalBusiness.
BreadcrumbList
W większości przypadków na stronach internetowych stosuje się tylko jedno menu okruszkowe. Zgodnie z dokumentacją Google nic nie stoi na przeszkodzie, aby na podstronach wykorzystywać więcej menu okruszkowych.
W przypadku zastosowania więcej niż jednego menu okruszkowego pojawiają się one w Search Console w sekcji Menu nawigacyjne → Prawidłowe elementy jako dwa prawidłowe elementy, czyli w liście przykładów pojawią się dwa identyczne adresy URL.
Product
Decydując się na wdrożenie danych strukturalnych schema.org, trzeba dodać wszystkie wymagane elementy. Google dzieli je na:
- krytyczne, które są konieczne do wyświetlania wyników rozszerzonych w Google,
- niekrytyczne (opcjonalne), które warto dodać do danych strukturalnych.
W przypadku produktów krytycznymi elementami są właściwości:
- offers,
- review,
- aggregateRating.
Największe trudności sprawia aggregateRating, w szczególności dla nowo powstających sklepów lub niszowych, specjalistycznych produktów. Aby wyeliminować ten błąd, często wykorzystywaną taktyką jest podanie zbiorczej oceny firmy. Google jednak rozpoznaje podanie zbiorczych ocen, które pojawiają się w miejscu indywidualnych dla produktów i usług, a w efekcie przestaje je wyświetlać.
Elementy, które często pojawiają się jako problemy niekrytyczne, to także:
- priceValidUntil – czyli informacja, do kiedy cena jest aktualna. W tej właściwości trzeba podać poprawną datę, do której cena będzie obowiązywała. Często spotykane rozwiązanie to podanie mniej lub bardziej losowej daty z przyszłości, np. 31 grudnia,
- hasMerchantReturnPolicy – właściwość dodana w 2020 roku zgodnie z propozycją Google, a w Search Console widoczna od niedawna,
- shippingDetails – własność, która widoczna jest w typie https://schema.org/Offer, a brakuje jej w typie https://schema.org/Product.
Rzadziej pojawiające się błędy to brak „priceCurrency” lub „priceSpecification.priceCurrency”, nieuzupełnione pole „review” lub brak identyfikatora globalnego (takiego jak GTIN czy marka).
Review, AggregateRating
W przypadku bardziej skomplikowanych i zagnieżdżonych struktur, w szczególności we wdrożeniu jako mikrodane, pojawiają się błędy w definiowaniu typów danych (w opiniach pojawia się np. niewłaściwy typ obiektu w polu Autor). Błąd ten powtarza się też na niektórych stronach. Jest to najprawdopodobniej spowodowane tym, że co najmniej jeden przykład wdrożenia ze strony schema.org zawiera ten błąd. Dotyczy to przykładu: https://schema.org/ratingValue#eg-0010
Test Google tego kodu wskazuje, że typ obiektu jest nieprawidłowy.
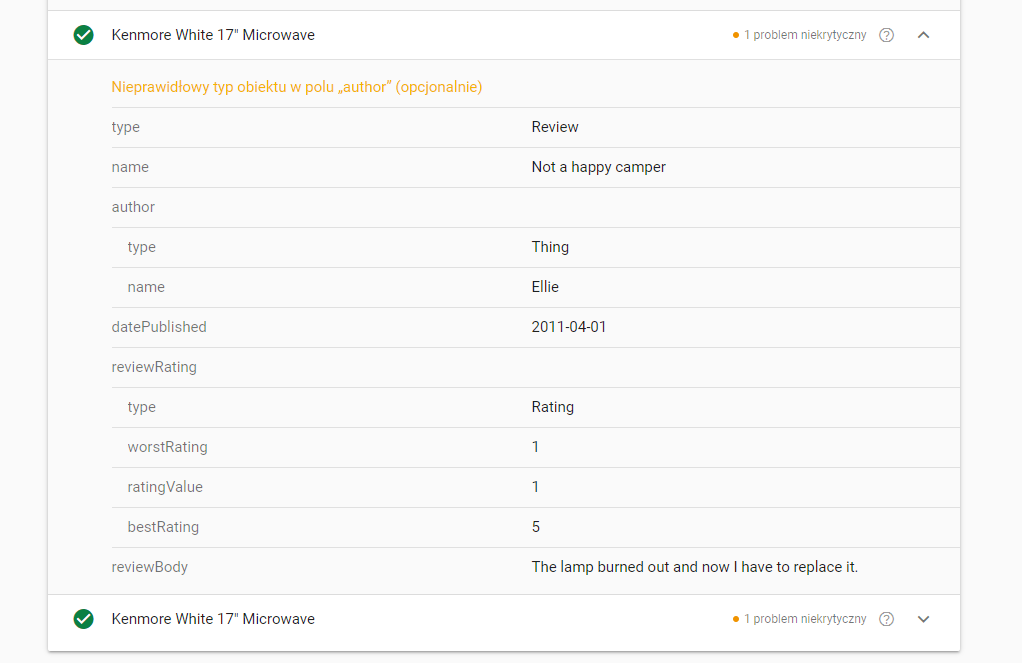
W tym kodzie wymagana jest niewielka zmiana, aby był poprawnie interpretowany przez Google. Trzeba zmienić kod:
<span itemprop=”author”>Ellie</span>
na wersję ze zdefiniowanym typem:
<div itemprop=”author” itemscope itemtype=”https://schema.org/Person”>
<span itemprop=”name”>Ellie</span></div>
Elementy, których często brakuje w ratingach to także ratingValue, ratingCount lub reviewCount. Warto pamiętać, że powinny one być liczbami naturalnymi.
Article
W przypadku typu Article zalecane jest podawanie autora wraz z adresem URL. Można stosować tutaj Właściwość URL lub SameAs. Właściwość name powinna być imieniem i nazwiskiem autora, chociaż praktyka wskazuje, że wiele redakcji dodaje skróty, pseudonimy i inicjały swoich autorów.
Event
W związku z COVID-19 wyszukiwarka wprowadziła dodatkowe właściwości:
- organizer,
- eventStatus,
- eventAttendanceMode,
- previousStartDate.
Widzimy tutaj jednak pewną niekonsekwencję z właściwością previousStartDate. W dokumentacji jest ona określona jako zalecana, jednak testy nie wskazują braku tego elementu jako problem niekrytyczny.
Uporządkowane dane, których nie można przeanalizować
Czasami zdarza się, że podczas wdrożenia danych strukturalnych wszystko się „posypie”. W niektórych przypadkach w Search Console pojawi się dodatkowa pozycja w ulepszeniach.
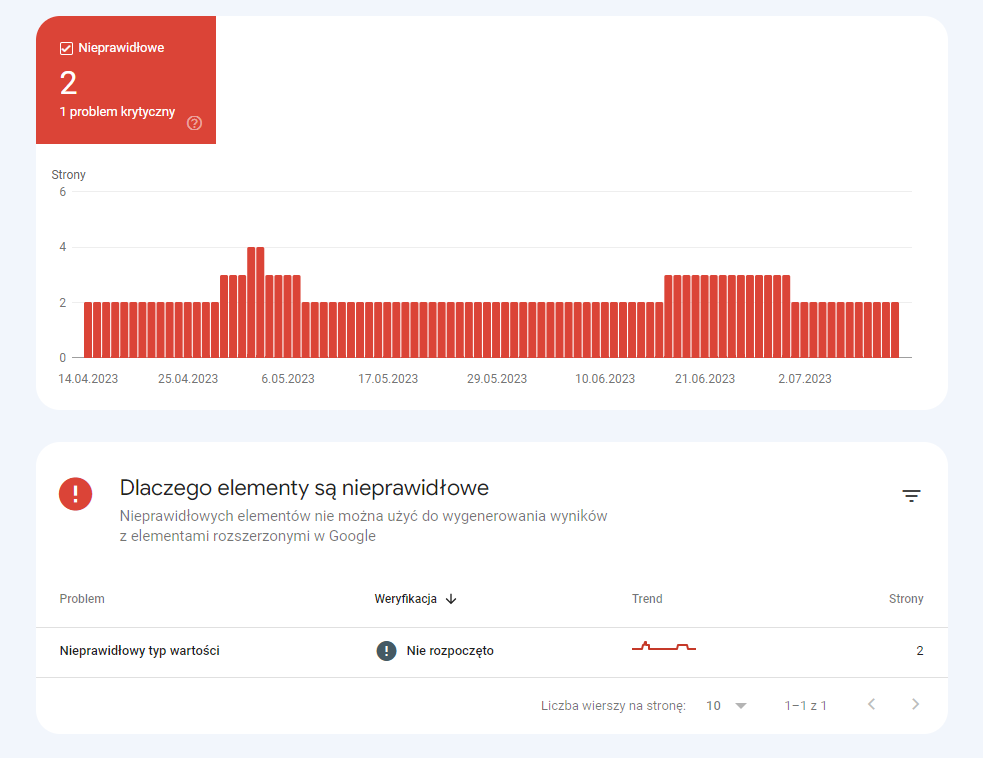
Wszystkie przypadki z tej sekcji wymagają indywidualnej analizy. Czasem wynika to z prostych błędów. W powyższym przypadku dane strukturalne zostały wdrożone z wykorzystaniem JSON, jednak pojawiają się nieprawidłowości, co powoduje, że Google nie może poprawnie odczytać danych. Błędów w powyższym przypadku jest kilka:
- niewłaściwe definiowanie tablicy,
- przecinki na końcu serii,
- błędne dodanie danych,
- znaczniki HTML i inne w danych.
Gdy błędów jest mniej, wyszukiwarka podpowiada, co może być przyczyną błędu:
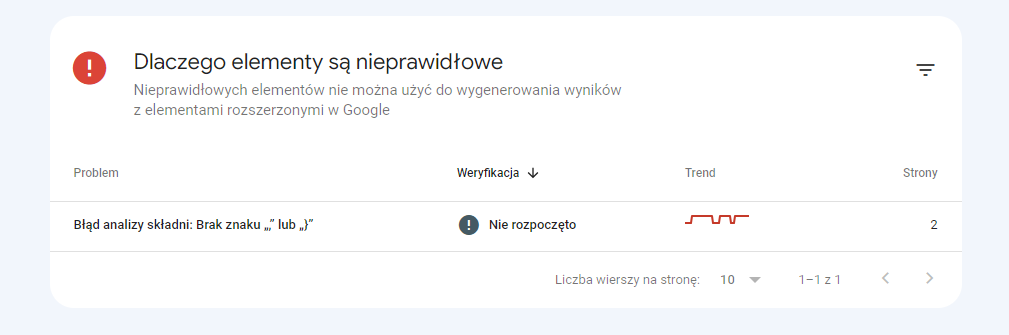
Czego brakuje w Schema.org?
W przypadku bardziej zaawansowanych wdrożeń dokumentacja schema.org nie określa precyzyjnie, jakie elementy można wykorzystać i jaki jest zakres użycia. W przypadku wielu bardziej specyficznych i nowszych typów i właściwości w dokumentacji brakuje przykładowych kodów.
Podsumowanie
Zdarza się, że dane strukturalne nie otrzymują wystarczającej uwagi. Moim zdaniem takie działanie może w negatywny sposób wpłynąć na działania SEO, głównie dlatego, że dane strukturalne ułatwiają robotom Google poruszanie się po stronie i interpretowanie jej treści. Biorąc pod uwagę, że – przy odrobinie wiedzy i doświadczenia – wdrożenie danych strukturalnych nie jest aż tak skomplikowane, warto wrócić do rozwijania stron o te elementy.
Uwagi końcowe:
1. Najwyższe poziomy organizacji danych, w danych strukturalnych schema.org, staram się konsekwentnie nazywać „typami”.
Analogicznie jak to robione jest na stronie schema.org. To jest typ „Article” https://schema.org/Article i posiada on „właściwości” lub „własności”/
Powyższy typ na podstronach dokumentacji Google jest różnie nazywany. Można spotkać się z takimi określeniami jak np. znaczniki, funkcje, definicje, atrybuty, obiekty – rekomenduję uważne wczytywanie się w polski przekład dokumentacji.
2. Nie jest to jasne wskazane w tekście, jednak wraz z kolejnymi akapitami zawężą się zakres terminu „dane strukturalne” – od wszystkich hipotetycznych danych strukturalnych, do 30 elementów schema.org wykorzystywanych przez Google.
3. Artykuł nie wyczerpuje tematyki. Wiele zagadnień zostało przedstawionych skrótowo, a inne zostały pominięte. Być może artykuł doczeka się części 2 lub wersji nr 2, w której dodatkowo będą opisane:
- ruch z fragmentów rozszerzonych,
- dodatkowe przykłady wdrożenia,
- gotowe kody do wykorzystania.
4. Wszystkie typy danych strukturalnych akceptowane przez Google
- Article (Article),
- Book (Book),
- Menu nawigacyjne (BreadcrumbList)
- Karuzela (ItemList)
- Course (Course)
- Dataset (Dataset)
- Edukacyjne pytania i odpowiedzi (Quiz, Question i Answer)
- EmployerAggregateRating (EmployerAggregateRating)
- Szacowane zarobki (Occupation)
- Event (Event)
- Informacje zweryfikowane (ClaimReview)
- Najczęstsze pytania (FAQPage, Question, Answer)
- Sposoby spędzania czasu w domu (VirtualLocation)
- Instrukcje (HowTo)
- Metadane obrazu (ImageObject)
- JobPosting (JobPosting)
- Film edukacyjny (LearningResource, VideoObject, Clip)
- Firma lokalna (LocalBusiness)
- Logo (Organization)
- Movie (Movie)
- Ćwiczenia (Quiz)
- Product (Product)
- Pytania i odpowiedzi (QAPage)
- Recipe (Recipe)
- Fragment opinii (Review, AggregateRating)
- Pole wyszukiwania z linkami do podstron (WebSite)
- Aplikacja (SoftwareApplication)
- Speakable (Speakable)
- Subskrypcja i treści płatne (CreativeWork)
- Video (Video)
Autor artykułu

Mateusz Pająk, SEO Specialist w DevaGroup
Od dziesięciu lat związany z branżą marketingu internetowego. Doświadczenie zdobywał w pracy dla znanych brandów. Posiada szerokie kompetencje w działaniach off-site i on-site SEO. Na co dzień tworzy i realizuje strategie pozycjonowania dla klientów, skupiając się nie tylko na wynikach, ale też na dobrych relacjach. Nieustannie rozwija swoje umiejętności i testuje nowe strategie SEO.

- Jak zdobywać ruch organiczny na blogu w erze AIO i LLM? 7 praktycznych wskazówek - February 6, 2026
- AI a link building – jak sztuczna inteligencja zmieniła ten proces? - February 2, 2026
- Czym jest GEO i jak działa? - January 29, 2026
Warto stosować dane strukturalne i to nie tylko ze względu na pozycjonowanie. To sposób, by przyciągnąć uwagę użytkowników, przekazać im ważne informacje, zachęcić do odwiedzenia strony. To również sposób, by wyróżnić się na tle konkurencji:) Ciekawy artykuł:)
August 28, 2023 at 8:13 pm