






In diesem Beitrag nehmen wir zwei Artikel zum gleichen Thema aus verschiedenen Qualitätszeitungen auseinander – ein Artikel rangiert bei Google ganz oben, der andere nicht. “Warum?” ist die naheliegende Frage. Ein wesentlicher Teil der Antwort wird durch Googles Natural Language Processing API enthüllt, sagt Dixon Jones – und er zeigt, wie Sie die gleiche Technik problemlos mit Ihren eigenen und den Inhalten Ihrer Mitbewerber verwenden können.
Diesen Monat habe ich das Natural Language Processing API-Tool von Google getestet, und ich fand es ein großartiges Werkzeug, um SEOs zu helfen, stärkere Inhalte zu schreiben, bei denen “stärker” zu einer numerisch messbaren Bewertung darüber wird, was Google unter dem Material versteht. Alles, was messbar ist, ist selten für eine SEO-Taktik! Sie können sogar testen, ob der Inhalt relevanter (oder herausragender) ist als der Inhalt, der derzeit bei Google platziert ist. Es ist ein mächtiges Tool, das höchstwahrscheinlich viele der Algorithmen von Google nutzt, also lassen Sie uns eintauchen.
Verwendung von Googles NLP Schritt für Schritt
Die Magie beginnt hier: https://cloud.google.com/natural-language/, die leistungsstarke Textanalyse-Maschine von Google. Wenn Sie nicht kodieren können, müssen Sie auf dieser Seite nach unten scrollen. Wenn Sie nach unten scrollen, werden Sie sehen, dass Google Cloud eine webbasierte Benutzeroberfläche entwickelt hat, mit der Sie jeden beliebigen Text in die Seite ausschneiden und einfügen können. (Screenshot unten.)
In dieser Box spielt sich die Magie ab. Sie wird den Text analysieren, um Ihnen zu sagen, worum es geht. Sie sollten eine solche Box sehen, wenn Sie nach unten scrollen, was ziemlich intuitiv ist:

Auf jeden Fall versuchen Sie den Beispieltext, den Google in diese Box stellt, aber ich habe ihn benutzt, um herauszufinden, warum eine wirklich gute Inhaltsseite in der New York Times nicht höher als Seite drei der SERPs wird, während der Telegraph ihren Inhalt ganz oben hat.
Zuerst habe ich mir eine Seite angesehen, in der mein Kollege Ken McGaffin über einen Artikel der NY Times über Craft Beer spricht.
Die NY Times ist eine großartige Zeitung (die meiste Zeit) und man würde denken, dass ihr Inhalt im Allgemeinen gut ist, aber laut dem Team von SEMRush könnte diese Seite etwas Hilfe benötigen:
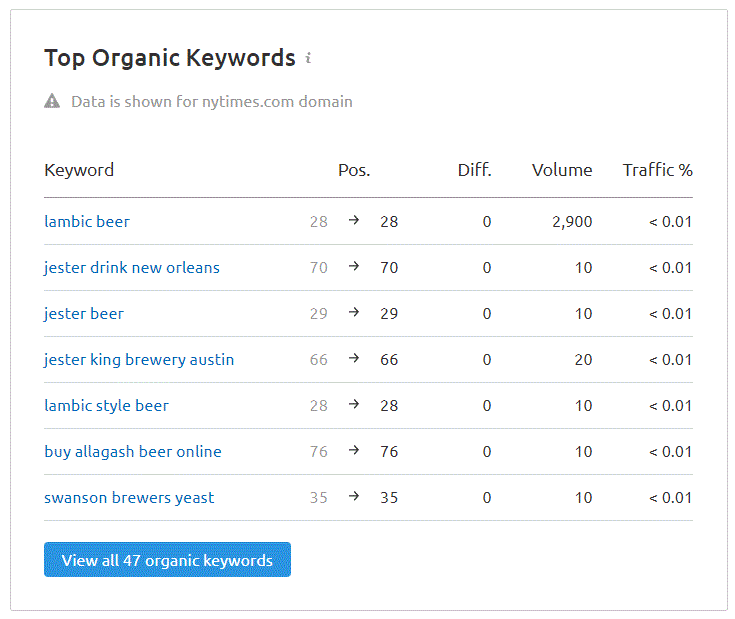
In der obigen Tabelle scheint diese Seite STARK (in den Augen von Google) für den Ausdruck “Lambic Beer” zu sein…. aber sie rangiert nur auf Platz 28. Wir können nur sehen, WIE viel Google denkt, dass es in diesem Artikel um Lambic Beer dreht, indem wir den Textkörper aus dem Artikel ausschneiden und in das Feld Google Cloud NLP “try it” einfügen. Wenn wir das tun, sehen wir zunächst dies:

Googles NLP AI nimmt den Inhalt und teilt ihn in das auf, was wir als “Entitäten” verstehen. Die Entitäten sind farbig dargestellt, wobei eine kleine Zahl unter jeder Entität steht. Die Zahlen sind eigentlich relative Rankings basierend auf dem SALIENZ der Entität innerhalb des Artikels selbst. So ist die auffälligste Entität “(mr.) stuffings”(!) – Es scheint, dass der Satz “mr” bewertet wird, aber dann in der letzten Analyse fallen gelassen wird. Wenn Sie unterhalb dieser Tabelle nach unten scrollen, sehen Sie diese Entitäten aufgelistet, in auffälliger Reihenfolge und mit einer Punktzahl zwischen 0 und 1 für jede Entität:
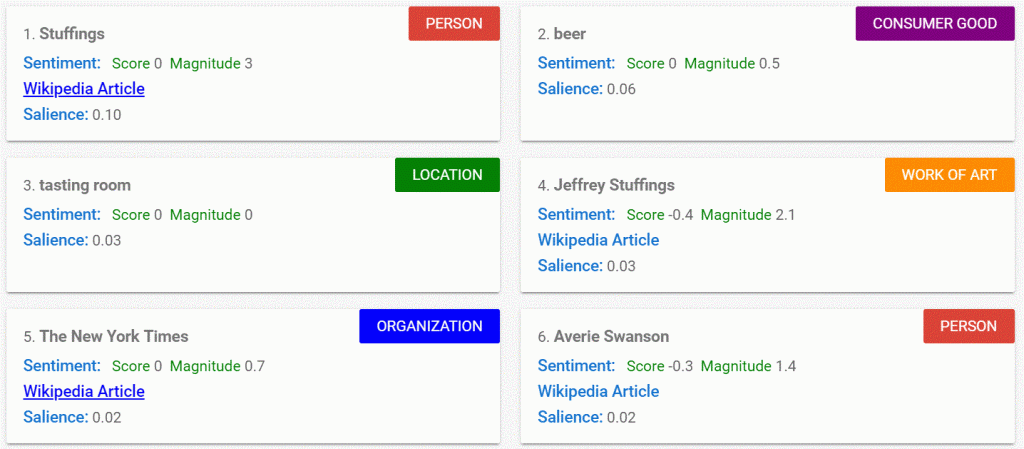
Dies sind die sechs wichtigsten Einheiten…. das Wort “Bier” ist die zweithäufigste (oder relevanteste) Einheit, wobei Mr. Jeffery Stuffings zweimal aufzutreten scheint. “Lambic Beer”, die laut SEMrush die beste Bio-Performance-Phrase ist, beginnt erst auf Platz 8 zu erscheinen:

Jetzt haben wir also einige absolute Zahlen. Die Hervorhebung von “Bier” in diesem Artikel ist 0,06 (von maximal 1). Die Aussagekraft von “Lambic” ist 0,02 von 1. Ohne Vergleich ist es schwer zu wissen, ob das gut oder schlecht ist, also geben wir “Lambic Beer” in Google ein und ziehen einen Konkurrenzartikel heraus. Ich habe das hier aus dem „Telegraph“ herausgeholt. Wieder einmal habe ich einen Teil der Geschichte ausgeschnitten und in das Google NLP-Tool eingefügt. Diesmal gibt es einen großen Unterschied!

Googles NLP-Tool zeigt, dass das Wort “Lambic” die Nummer 1 ist, die in diesem Artikel erwähnt wird. Die Punktzahl ist 0,25 von einer maximalen Punktzahl von 1, das ist um einiges stärker als die 0,02, die wir im ersten Artikel gesehen haben.
Nicht nur das, sondern Google hat uns auch die Entitätstypen… “Organisation”, “Person”, “Konsumgüter” gezeigt, wie Google die Wörter nicht nur verstanden hat, sondern auch, was sie bedeuten.
Aufzeigen der Relevanz und Salienz eines Inhaltselements
Google hat seit einigen Jahren verstanden, dass unstrukturierte Inhalte schwer zu archivieren und zu kategorisieren sind. Wenn du in eine reale Bibliothek gehst und nach einem Buch über die “Erde” fragst, führt dich der Bibliothekar dann zur Astronomieabteilung oder zur Geologieabteilung? Der Abschnitt Geschichte oder der Abschnitt Karten? Ohne weitere Informationen über Ihre Anfrage kann der Bibliothekar es nicht sagen, aber hier ist der Kniff, der Bibliotheken tötet: Sie müssen jedes Buch bereits in einen Abschnitt gelegt haben, bevor Sie den Bibliothekar fragen! Eine wirklich clevere Bibliothek könnte mehrere Kopien des richtigen Buches in mehreren Abschnitten haben, um alle Grundlagen abzudecken, aber letztendlich ist die Einschränkung der Bibliothek, dass das Verschieben der Bücher (oder Seiten oder Kapitel) zwischen den Abschnitten einfach nicht möglich ist.
Indem Google den gesamten Inhalt aller unstrukturierten Seiten liest, zerlegt Google die Inhaltsteile, jedes einzelne Stück Bedeutung, in immer kleinere Komponenten. Nun handelt eine Website nicht nur über viele Dinge, sondern jede einzelne Seite. Tatsächlich dreht sich so schon ein einziger Satz um viele Dinge.
Der natürliche Endpunkt dabei ist, dass Google in einigen Jahren kaum echte Web-URLs zurückgeben wird, was ein philosophischer Punkt ist, den ich gerne mit SEOs auf Konferenzen diskutiere. In der Zwischenzeit wollen SEOs Traffic auf ihre Webseiten, so dass die Herausforderung die gleiche bleibt, wenn das das Ziel ist…. wie kann man Ihren Webseiteninhalt hervorstechender machen als den der Konkurrenz?
Googles Toolkit für die Natural Language Processing API
Google und die Information und der Rest der Industrie haben inzwischen immense Ressourcen in die Entwicklung mehrerer Ansätze zur natürlichen Sprachverarbeitung investiert. Es gibt CBOW (Continuous Bag of Words), Word2Vec, Skipgrams, nGrams, Harmonic Centrality und Topical PageRank, um nur einige Schlagwörter zu nennen, die alle durch Forschungsarbeiten, Patente und Algorithmen ergänzt werden. Aber woher wissen wir, was Google tatsächlich verwendet, und was passiert, wenn wir eine neue Methodik entwickeln, nur um festzustellen, dass Google seine Algorithmen ändert, während wir live gehen?
Ich denke, die Antwort ist die Verwendung der von Google entwickelten Natural Language Processing API bei der Erstellung Ihrer Inhalte. Googles NLP API ist nicht nur öffentlich zugänglich, sondern Sie müssen auch kein Programmierer sein, um sie zu nutzen! Wahr – Ich stelle mir vor, dass die meisten SEO-Tools nach dem Lesen dieses Beitrags anfangen werden, nach Ihren Google-API-Schlüsseln zu fragen, damit sie diese Daten nutzen können, aber im Moment werde ich Ihnen zeigen, wie Google nicht nur Ihren Inhalt, sondern auch Ihren Wettbewerbsinhalt interpretiert.
Hypothese: NLP Auffälligkeit ist ein großer und messbarer Suchfaktor!
Barry Schwarz brach die Nachricht im Jahr 2016, dass der Inhalt einer der drei Hauptfaktoren in Googles Algorithmen (zum Zeitpunkt seines Beitrags) mit dieser nun berüchtigten Schlagzeile ist:
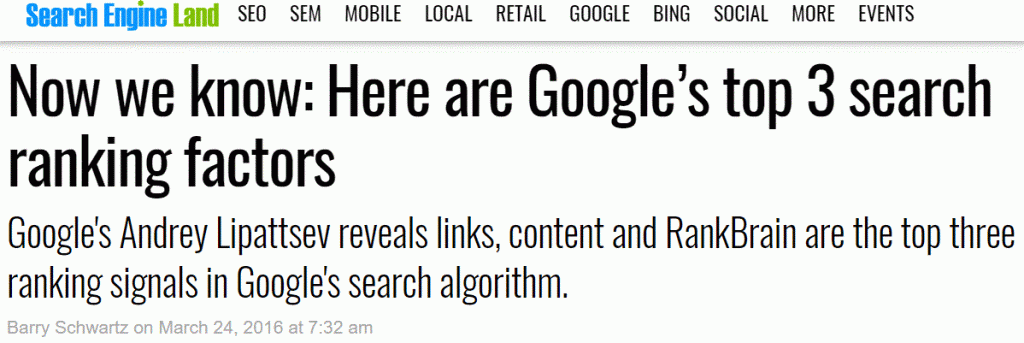
Ich denke, dass es Sie schlimmer treffen könnte, wenn nicht die Salienzbewertung verwendt werden würde, um zu beurteilen, wie Google Ihre Inhalte bewertet und interpretiert. Googles ERSTES Ziel (noch mehr als Geld) ist es, zu versuchen, dem Nutzer RELEVANTE Ergebnisse zurückzugeben. Andernfalls kommt es schnell zu einem Vertrauensverlust der Kunden. So ist es sinnvoll, dass Salience/Relevance Expertise, Autorität und Vertrauen bis zu einem gewissen Grad übertrifft. Google muss ZUERST das Gefühl haben, dass das Ergebnis des Kandidaten eine Schwellenwertüberschreitung erreicht, bevor es sich an diese anderen Faktoren wenden kann, um verschiedene Inhalte zu unterscheiden, die es selbstbewusst als etwa gleichwertig beschreiben kann.
Hier ist eine andere Möglichkeit, darüber nachzudenken. In unserem Beispiel “Lambic Beer” fand Google ein Top-Ergebnis, dass es zuversichtlich genug war, über Lambic Beer zu sein, Alle Dinge sind gleich, der Benutzer würde sich wahrscheinlich nur darum kümmern, wenn er versuchen würde, die Organisation hinter Lambic Beer zu finden, aber da es sich um ein generisches Produkt handelt, gibt es keins (zumindest kein signifikantes, das Google finden könnte), so dass Google sich dann auf E-A-T-Faktoren konzentrieren kann, in dem sicheren Glauben, dass sie die Ordnung eines Datensatzes verbessern, anstatt die herausragenden Informationen zu verlieren.
Keyword Relevanz vs. Keyword Dichte
Damals, in den goldenen Tagen der Suche, haben wir einen Begriff namens “Keyword-Dichte” verwendet. Es war wirklich nie eine gute Metrik…. es war Keyword-Füllung, anstatt nützliche Informationen zu vermitteln. Im Laufe der Jahre begannen SEOs, sich übermäßig mit Keywords zu beschäftigen, indem sie betrachteten, welche Wörter die meisten Ansichten hatten, indem sie die Google Adwords API und andere Tools verwendeten und dann Inhalte schrieben, die versuchten, die Lücken zu schließen. Schließlich wurde der Ansatz so allmächtig, dass Google den reinen SEO-Tools die AdWords-API entzog. Sie können immer noch viele Keyword-Vorschläge Methoden finden. Ich werde heute nicht darauf eingehen.
Für kurze Zeit hat uns Google überzeugt, dass wir keine Keywords verfolgen sollten. Stattdessen sollten wir uns “nur auf gute Inhalte konzentrieren, die die Menschen lieben werden”. (Das – genau da – ist ein Abgrund der gleichen Philosophie, der mit unterschiedlichen Gefühlen beschrieben wird. )
Interessanterweise besteht die Gefahr, dass Googles unerbittlicher Schritt hin zur Umwandlung unstrukturierter Daten in strukturierte Daten den Kreis der SEOs schließt.
Es gibt noch viel zu testen für SEOs
Dieser Ansatz ist intuitiv sinnvoll, aber andere SEOs sollten sich dieses Tool weiter ansehen und versuchen zu verstehen, wie wichtig die Algorithmen hinter dem Tool sind. Ich bemerkte eine Reihe von unbeantworteten Dingen, als ich diesen Test machte. Zum Beispiel:
- Google behandelt großgeschriebene Wörter anders als nicht großgeschriebene Wörter in der NLP-Entitätsausgabe. Aber wie wird ein fauler von einem nicht faulen User unterschieden?
- “Mr. Stuffing”, “Stuffings” und “Jeffery Stuffing” wurden alle in der Textliste aufgeführt, aber “Mr. Stuffing” und “Stuffing” wurden als die gleiche Einheit eingestuft, während “Jeffery Füllung” einzigartig war. Sie wurden alle als Individuum identifiziert und mit dem gleichen Wikipedia-Artikel verknüpft, warum also überhaupt trennen?
- Beachten Sie, wie sehr sich Google auf Wikipedia verlässt, um seiner Bewertung eine gewisse Gültigkeit zu verleihen…. aber dies ist eine Verzerrung in ihren Algorithmen, die langfristig zu Problemen führen kann. Ein schurkischer Wikipedia-Editor kann verheerende Auswirkungen auf die Bearbeitung der Konkurrenz haben.
- Betrachtet man schließlich das Attribut der Entität in der oberen rechten Ecke jedes Kastens, so sieht dies wie der Entität “Typ” aus, wie in der Dokumentation beschrieben, jedoch kann eine einzelne Entität viele Typen haben, so ist es interessant zu sehen, dass Google einen Typ im Kontext ausgewählt hat.
Ich lade SEO-Praktizierende ein, sich damit eingehender zu befassen.
- Wie wichtig werden Backlinks im Jahr 2023 sein? - February 23, 2023
- Was steckt eigentlich in einem Link? - October 31, 2022
- Ein Interview mit… Ash Nallawalla - September 13, 2022