






Das Thema interne Verlinkung ist eines der spannendsten im SEO. Schon im letzten Artikel hatten wir ein Thema aus diesem Bereich, wobei damals der Fokus auf dem Thema Priorisierung von URLs vor und nach einer Migration lag (hier). Dieser Artikel soll sich nun mit dem Thema „Orphan Pages“, zu Deutsch verwaiste Seiten, befassen. Es geht um die Fragen: Was sind Orphan Pages, wie findet man sie und warum ist es wichtig.
Was sind Orphan Pages?
Der Fachbegriff Orphan Pages beschreibt URLs bzw. Unterseiten, die nicht durch die interne Verlinkung gefunden werden können, da sie gar nicht verlinkt sind. Diese nicht intern verlinkten URLs „schweben“ quasi im URL-Set einer Domain mit, ohne dass sie beispielsweise durch einen standardisierten Web-Crawl zu finden sind. Dies bedeutet allerdings, dass sie auch nicht vom normalen Google-Bot gefunden werden können. Diese Seite fällt also “durchs Raster“.
Warum ist das Thema Orphan Pages wichtig?
Aus SEO Sicht ist das Thema wichtig, weil es sich bei Orphan Pages eventuell um starke und wichtige Seiten handeln kann, die aber intern nicht verlinkt sind. Dies kann dann dazu führen, dass durch diese Seiten kein Trust oder andere Signale geleitet werden, wodurch sie auch nicht zur Steigerung der organischen Sichtbarkeit beitragen können. Auch der User kann diese Seiten dann meist nicht erreichen und so gehen eventuell relevante Inhalte leider verloren.
Wie können Orphan Pages gefunden bzw. Identifiziert werden?
Zu finden sind Orphan Pages nur dann, wenn verschiedene Datenquellen zusammengeführt werden. Eine Gap-Analyse kann daher zur Entdeckung von Orphan Pages führen.
Im Übrigen sollten Orphan Pages nicht mit „Sackgassenseiten“ verwechselt werden, die wiederum eingehende, aber eben keine ausgehenden Verlinkungen haben. Diese Seiten stellen daher ein „Dead-End“ dar, was ebenfalls ein Problem für die interne Verlinkung sein kann, an dieser Stelle aber nicht weiter thematisiert werden soll.
Was also tun, um Orphan Pages zu finden? Das Naheliegendsten wäre eine Gap-Analyse mit den Backlinkdaten einer Domain vorzunehmen.
Orphan Pages mit Backlinkdaten finden
Die Kombination von Web-Crawl-Daten und Backlinks stellt einen ersten und einfach umzusetzenden Schritt dar, um Orphan Pages zu entdecken. Wie man hierbei genau vorgeht, hängt wahrscheinlich von den eigenen Präferenzen und dem zur Verfügung stehenden Tool-Set ab. Hat man sowohl einen Crawler als auch beispielsweise Majestic-Daten zur Hand, kann man die aus dem Web-Crawl stammenden URLs mit den Linkziel-URLs der externen Verlinkungen abgleichen. Der Vergelich von URLs, zum Beispiel durch einen einfachen „SVERWEIS“ oder „LOOKUP“-Befehl bei Excel, kann schon ausreichen, um eventuell vorhandene Orphan Pages zu entdecken.

Wer es etwas praktischer haben will und mit deutlich größeren Datenmengen zu tun hat, der kann das zum Beispiel über ein Tool wie Deepcrawl lösen. Neben den Standarddaten des Web-Crawls hat man hier zusätzlich die Möglichkeit, die Backlinkdaten von Majestic mit nur einem Klick beim Anlegen eines Crawls hinzuzufügen. Diese Funktion ist für den Nutzer kostenlos, da die Majestic-Daten hierbei standardisiert über eine API hinzugeführt werden.
Man kann dem Crawl allerdings auch durch einen manuellen Upload von bis zu 100 MB an Linkdaten hinzufügen. Das Ergebnis ist dann eine Übersicht, die euch per Gap-Analyse zeigt, ob das Tool beispielsweise URLs nur aus dem Web-Crawl oder nur aus den Backlinkdaten erschlossen hat.
Im besten Fall sieht der Report dann so aus, da hier keine Orphan Pages mit Backlinkdaten gefunden wurden:

Es kann aber auch sein, dass im Report eine bestimmte Anzahl an URLs auftaucht, die die gesuchten Orphan Pages darstellen. Diese URLs sollten weiter analysiert werden. Es sollte untersucht werden, ob diese Seiten a) einen tatsächlichen Nutzen haben, b) wo sie genau herkommen, c) ob diese Seiten überarbeitet und aufgewertet werden sollten, weil sie einen Mehrwert für den Nutzer haben oder d) ob sie schlussendlich vollständig beseitigt werden sollten.

Da wir nun wissen, wie wir Orphan Pages mit Hilfe von Backlinkdaten entdecken können, wollen wir uns noch weiteren Datenquellen zuwenden, die ebenso zur Entdeckung beitragen können. Auch hierfür wurde im weiteren Verlauf mit Deepcrawl gearbeitet.
Orphan Pages durch Sitemaps finden
Dieser Weg ist eigentlich fast genauso offensichtlich wie einfach zu prüfen und dennoch wird er oft nur genau andersherum vorgenommen. In den meisten Fällen möchte man herausfinden, ob die eigene Sitemap alle URLs beinhaltet, die sie auch beinhalten soll. Eher selten wird danach geschaut, ob sie URLs beinhaltet, die nicht durch einen Web-Crawl gefunden werden können.
Dies passiert typischerweise, wenn eine neue Seite angelegt, die Sitemap automatisch generiert, aber vergessen wird die Seite intern zu verlinken. Eine weitere Ursache wäre, wenn Seiten nur aus der internen Verlinkung genommen werden, weil man sie nicht mehr für wichtig hält, aber eine automatisierte Anpassung der Sitemap nicht erfolgt. Glücklicherweise können auch an dieser Stelle verschiedene Tools helfen, dies zu kontrollieren. Es muss dabei auch nicht immer die Große Menge an URLs sein, die es zu finden sind, alles zwischen 1-10 kann manchmal schon reichen, wie der nachfolgende Screenshot zeigt.
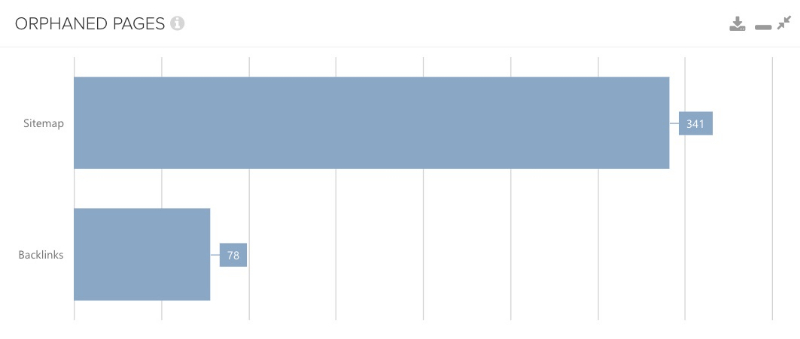
Da wir nun auch die Entdeckung von Orphan Pages per Sitemap-Daten behandelt haben, kommen wir zu einem weiteren spannenden und auch wichtigen Datensatz.
Orphan Pages durch Google Search & Analytics-Daten finden
Dieser Abgleich ist nach dem mit Backlinks vielleicht der interessanteste, da hier nun explizit auf Google-Daten zurückgegriffen wird. Finden wir also Orphan Pages durch den Abgleich mit Google Search & Analytics-Daten, ist die Bedeutung dieser Entdeckung vielleicht noch ein bisschen größer als beispielsweise durch die Sitemap. Hier können wir sicher sein, dass Google diese URLs kennt – woher auch immer – und dass wir sie eben nicht mehr intern verlinkt haben. Natürlich gehen wir hierbei jetzt nicht von einem URL-Unterschied aus, der beispielsweise durch bewusste Crawler-Steuerung entstanden sein kann, sondern setzen hier immer einzigartige und indexierbare URLs voraus (also insbesondere keine Parameter- oder Sortierseiten).
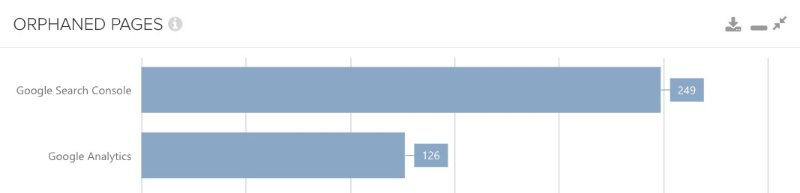
Wer noch nicht genug hat, der kann noch weitere Datenquellen heranziehen.
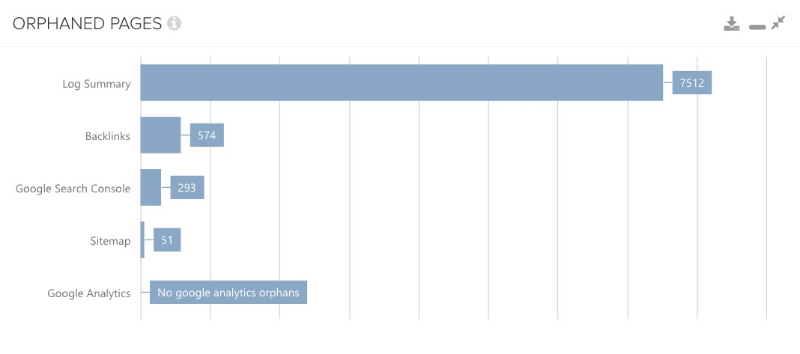
Orphan Pages durch Logfiles finden
Wenn gerade davon gesprochen wurde, dass der Abgleich mit der Google Search Console & Analytics spannend ist, dann muss hier ergänzt werden, dass der Abgleich mit Logfiles eigentlich noch besser ist und der Grund dafür ist einfach: Logfiles sind serverseitige Daten, die exakt sind. Client-seitige Daten wie Google Analytics oder Daten aus der GSC, bei denen wir im Grunde überhaupt nicht wissen wo sie herkommen, sind hier eine Art „Blackbox“. Wer also seine Serverlogs zur Hand hat, der kann beispielsweise auch diese nutzen, um hier einen Abgleich vorzunehmen, in der Hoffnung, dass das Ergebnis nicht so aussieht wie in der folgenden Abbildung. Dies ist dann schon eher ein alarmierender Zustand.

Wer jetzt noch immer nicht genug hat, der kann sich auch mal einen Export aller angelegten und aktiven Seiten aus seinem System ziehen bzw. geben lassen und diesen mit dem URL-Set aus dem Web-Crawl abgleichen. Man wird überrascht sein, wie oft es hier zu Ergebnissen kommt und wie oft es hier Orphan Pages gibt. Die Gründe dafür können vielfältig sein, was uns zum nächsten Abschnitt bringt.
Gründe für Orphan Pages
Wir haben uns jetzt schon viel mit der Entdeckung von Orphan Pages auseinandergesetzt, aber noch nicht mit den Gründen ihrer Entstehung, und diese können vielfältig sein. Im Folgenden einige Möglichkeiten, ohne den Anspruch auf Vollständigkeit zu erheben.
- Seiten, die vollständig oder sukzessive aus der internen Verlinkung entnommen wurden, ohne dass sie final abgeschaltet wurden.
- „Testseiten“ aus dem Shopsystem, um beispielsweise A/B Tests zu fahren. Die betreuende Person verlässt irgendwann mal das Unternehmen und keiner kennt mehr diese URLs
- URLs aus einem alten, vorangegangenen CRM-System, das aber nie ganz abgeschaltet wurde.
- Landingpages für trendige/saisonale Themen, die dann nie abgeschaltet wurden.
- Fehlerhafte Anwendung des CMS, wodurch Seiten generiert wurden
- Offline-genommene Kategorien, die nicht weitergeleitet wurden
- Seiten, die bei einer Migration einfach „vergessen“ wurden.
- tbd
Das Problem mit Orphan Pages
Gelegentlich gibt es wirklich skurrile Gründe, die, so lustig sie klingen mögen, von der Relevanz des Themas ablenken. Einer der Hauptgründe warum Orphan Pages ungünstig sein können, ist neben dem Thema Indexhygiene, dass sie Probleme im Keyword Targeting einer Domain verursachen können. Existieren beispielsweise neben den URLs für die Hauptkeywords Orphan Pages, die keiner kennt, die aber auf das gleiche Keyword oder Varianten davon ausgerichtet sind (z.B. „Kühlschank vs. Kühlschänke“ etc.) kann dieses dem Ranking-Erfolg einer Domain schaden.
Ungünstig wäre auch, wenn die falsche URL, obwohl nicht (mehr) intern verlinkt, ranken würde, weil sie vielleicht historisch extern besser verlinkt ist als die neuere und besser optimierte Seite (ja, manchmal werden Seiten auch nicht weitergeleitet!). Es kann also auch durchaus der Verlust an Linkraft sein, der bei Orphan Pages eine Rolle spielen kann.
Natürlich sollten diese Seiten immer auch auf Traffic geprüft untersucht werden – nicht umsonst gibt es den Abgleich mit Google Analytics. Jedoch sollte ebenso in Betracht gezogen werden, dass Orphan Pages beispielsweise die Linkstruktur einer Domain stören können, wenn sie – hierarchisch gesehen – in der Mitte liegen. D.h. die Orphan Page und nur sie verlinkt auf andere Seiten, die daher komplett aus der URL-Struktur Fallen, weil sie nur von der Orphan Page aus verlinkt sind.
Abschließend sei also gesagt: Wer seine Domain noch nicht auf Orphan Pages analysiert hat, der weiß jetzt, was das ist, warum es wichtig ist und wie er vorgehen kann. Bleibt zu hoffen, dass ihr nicht eine folgende Situation vorfindet:
Also: Just do it!
- Link Graph – Der einfache Weg Domainzusammenhänge zu analysieren - December 16, 2020
- Orphan Pages: Wie sind sie zu erkennen und was ist das Problem - August 20, 2018
- Domain-Migrationen: Achtet auf die (internen) Links! - May 21, 2018