





Gabrielle Benedetti a posé une question intéressante l’autre jour:
Gabriele Benedetti demande : Quand je dois étudier le trust flow et le citation flow d’un concurrent, que choisir entre “domaine racine” et “sous domaine”? Et pourquoi? Merci
Pourquoi Gabriele pose cette question?
Quand vous utilisez la barre de recherche Majestic, il y a une liste déroulante (ou si vous avez personnalisé vos réglages, des boutons radio après que vous ayez cliqué sur le bouton de recherche :
Cette liste déroulante n’apparait pas par défaut sur la page d’accueil, nous interprétons ce que l’on pense que vous cherchez d’après votre saisie.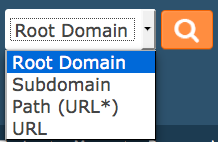
Par exemple, si vous entrez bbc.co.uk nous supposons alors que vous voulez la «racine » du domaine (la partie avant le domaine de premier niveau). Si vous tapez www.bbc.co.uk, c’est en fait un sous domaine de bbc.co.uk, et www.bbc.co.uk/ avec un slash c’est alors interprété comme une url donc nous supposons là que vous voulez des informations sur la page d’accueil de la bbc elle-même et non pas du site entier. Il y a une autre option que l’on appelle « chemin » qui est plus compliquée à expliquer. La question est quand cela se rapporte à un client, qu’elle version choisir ?
Comparer des Pommes et des Oranges
La première chose à comprendre et que si vous comparez www.siteA.com avec [pas de www]siteB.com vous comparez des chiffres qui provienne de calculs complètements différents ! Ainsi, si un site utilise par default www et l’autre pas de www, ils peuvent être comparés directement à partir du comptage des backlinks, des noms de domaines référents ou des flow metrics. Voilà tout…
Nos données sont calculées au niveau de l’URL
Le monde d’internet est fait d’URL et par conséquent nous avons d’abord assimilé le web dans son ensemble puis calculé des scores pour chaque page, individuellement.
Cela nous donne des renseignements comme le nombre de pages provenant d’autres sites qui conduisent à chaque page et le « niveau de confiance » qui découle de chaque page.
Au final cela nous donne des scores absolus pour chaque page que l’on convertit en des nombres entre 1 et 100 simples à visualiser, c’est une normalisation de l’ensemble des données.
Ensuite nous devons combiner toutes les Url pour chaque sous domaine dans un autre ensemble de nombres absolus, que nous normalisons à nouveaux les unes face aux autres pour obtenir des nombres de 1 à 100.
Nous intégrons à nouveaux les URL pour chaque domaine racine au sein d’un troisième ensemble de nombres absolus, que nous normalisons les unes faces aux autres pour obtenir des nombres de 1 à 100.
Ainsi, étant donné qu’il y a plusieurs normalisations, chaque ensemble est comparé en utilisant des ensembles de données complètement diffèrents. On ne compare pas des pommes avec des oranges.
Je n’ai pas l’esprit mathématique, expliquez moi d’une autre façon !
Pour illustrer par un exemple dans la «vrai vie», on pourrait s’intéresser au nombre de mots que chaque personnes a déjà dit, au niveau de la planète, par pays, et par continent. On prend chaque personnes des Etats Unis et nous leurs attribuons une approximation du nombre de mots qu’elles connaissent. Ensuite on peut normaliser ces données afin que chaque personne ait un nombre entre 1 et 100 de manière à ce qu’une note autour de 100 représente quelqu’un qui connait presque tous les mots, tandis qu’un nouveau-né sera à 0. (Au passage, on obtiendra beaucoup plus de 0 que de 100…)
Maintenant, si on fait la même opération pour tous les habitants Américains VS ceux de Grande Bretagne, alors on devra choisir une manière de combiner les données. Allons-nous utiliser la moyenne ? Le mode ? La médiane ? Quelque méthode que l’on choisisse, on a un score pour chaque pays mais l’on voudra classer les pays pour les comparer.
Alors on s’aperçoit qu’une personne peut connaitre excellemment bien sa langue mais provenir d’un pays classé très haut ou très bas.
Vous devriez faire le focus sur les pages, pas les racines ou les sous-domaines!
Je pense que cet exemple le démontre bien… Voilà le top 5 des résultats de mon google SERPS pour la requête « style avance » :
1: advancedstyle.blogspot.com/
2: advancedstylefilm.com/
3: advancedstylefilm.com/screenings
4: http://www.theguardian.com/fashion/2014/may/03/advanced-style-fashion-blog-for-older-women
5: https://www.youtube.com/watch?v=nWKTfqivbRQ
On constate que le 1er résultat est un sous domaine. Le deuxième et un domaine racine. Les autres sont visiblement des pages.
Regardons de plus près… Les deux premiers sont aussi des URL car elles se terminent par un slash
En d’autres mots, Google se rapporte au niveau de la page. Même si quelques-uns de ses algorithmes sont basés sur le facteur « domaine », la plupart se basent sur celui de la page. Quelques signaux sont encore base sur le server ou la nationalité, mais Google revient presque toujours à son unité de mesure la plus basse quand il répond à une requête. Si il ne le fait pas, il y a des chances qu’il ne puisse réponde à la question à votre place et qu’il ne vous renvoit aucun site. (Ce qu’il font de plus en plus souvent)
Mais la réponse que me donne Google n’a pas de backlinks ?
Je pense que la raison pour laquelle les gens continuent à chercher des données sur les domaines est que les données de surface semblent dénuées de sens au niveau de la page. Mais une page se classe sans liens externes car elle a des liens INTERNES vers d’autres pages fortes du même site. C’est pour ça que nous passons par des liens internes pour juger du « niveaux de confiance et citations » même si le fait de répertorier tous ses liens internes requière un espace de stockage 10 fois plus important sur nos serveurs.
Une page sur Mashable.com peut être populaire, tandis que celle d’après complétement ignorée. Cela s’applique aussi pour Wikipédia , BBC, CNN ou Blog spot … En vérité un site plus important a plus d’options pour rediriger ses utilisateurs, mais en fin de compte, Google renvoi des pages et non des sites. Un important maillage interne vers l’une des pages du site augmente ses chances de remonter dans le classement des pages… Mais seulement si ce maillage est fait depuis des pages fortes.
Pour répondre à la question de Gabrielle…
En supposant que Gabrielle pose la question d’un point de vue SEO, la réponse est « aucun » Sélectionnez plutôt la page que Google classe le mieux et utilisez-là. Sinon, vous finirez par comparer des oranges avec des pommes, des petits sites avec wikipedia.org. Cependant, si Gabrielle avait posé la question du point de vue d’un actionnaire, alors c’est le domaine qui est intéressant. A moins que les sous-domaines aient été vendus à des tiers.
- Merci encore à Majestic - April 24, 2015
- Mise à jour de l’index historique : Une nouvelle utilisation pour l’option top Backlinks ! - April 7, 2015
- L’extension chrome de Majestic a été mis à jour pour inclure le Topical Trust Flow - March 27, 2015