






Le sujet des liens internes est l’un des plus passionnants en référencement. Dans le dernier article que j’ai écrit pour le blog de Majestic, je me suis concentré sur la priorisation thématique des URLs avant et après une migration ; (que vous pouvez lire ici). Mais cet article se concentre sur les pages orphelines ; ce qu’elles sont, comment les trouver et pourquoi c’est important de les traiter.
Qu’est ce qu’une page orpheline ?
Le terme technique pages orphelines décrit des URLs ou des sous-pages qui ne peuvent pas être trouvées par des liens internes, puisqu’elles ne sont pas du tout liées. Ces URLs qui ne sont pas liées en interne “flottent” dans l’ensemble d’URL d’un domaine sans être trouvées par un crawl standard. Cela signifie qu’elles ne peuvent pas non plus être trouvées par le bot classique de Google. Donc, en d’autres termes, cette URL, (page), passe à travers les mailles.
Comment détecter des pages orphelines ?
Les pages orphelines ne peuvent être trouvées que si différentes sources de données sont fusionnées. Une analyse des écarts peut donc conduire à la découverte de pages orphelines. Attention cependant, il ne faut pas confondre les pages orphelines avec des “pages sans issue” qui à leur tour ont des liens entrants mais pas de liens sortants. Ces pages représentent donc une “impasse”, qui, certes, peut aussi être un problème pour les liens internes, mais ne sont pas fondamentales pour les pages orphelines et qui en tant que telles ne seront pas discutées plus loin dans cet article.
Comment trouver des pages orphelines avec des données de backlink ?
La chose la plus évidente à faire serait une analyse de l’écart avec les données de backlink d’un domaine.
La combinaison des données du crawl et des backlinks est une première étape facile pour découvrir les pages orphelines. La méthode exacte et la façon de procéder dépendent probablement de vos préférences et des outils disponibles. Si vous avez à la fois un crawler et des données Majestic à portée de main, vous pouvez comparer les URLs du crawl avec les URLs cibles des liens externes. La comparaison des URLs, par exemple avec une simple commande ‘SVERWEIS’ ou ‘LOOKUP’ dans Excel, peut être suffisante pour détecter toute page orpheline existante.

Si vous voulez quelque chose de plus pratique et que vous devez traiter des quantités de données beaucoup plus importantes, vous pouvez résoudre ce problème avec un outil comme Deepcrawl, par exemple. En plus des données standard du crawl, vous pouvez également ajouter les données de backlink de Majestic en un seul clic lors d’un crawl. Cette fonction est gratuite pour l’utilisateur, car les données Majestic sont ajoutées via une API standardisée.
Cependant, vous pouvez également ajouter manuellement jusqu’à 100 Mo de données de lien au crawl. Le résultat est une vue d’ensemble qui reflète l’analyse de l’écart entre les URLs du crawl ou les données de backlink trouvés par l’outil.
Dans le meilleur des cas, le rapport ressemble à cela parce qu’aucune page orpheline avec des données de backlink n’est trouvée ici :

Il est également possible qu’un certain nombre d’URLs apparaissent dans le rapport dédié aux pages orphelines recherchées. Ces URLs devraient faire l’objet d’une analyse plus approfondie. Il convient d’examiner si ces pages :
a) ont un avantage réel
b) leur provenance exacte
c) si ces pages doivent être révisées et mises à jour parce qu’elles ont une valeur ajoutée pour l’utilisateur
d) ou s’il faut les éliminer complètement

Puisque nous savons maintenant comment découvrir des pages orphelines à l’aide de données de backlink, nous pouvons nous tourner vers d’autres sources de données, qui peuvent également contribuer à la découverte (à noter que Deepcrawl a également été utilisé ici).
Trouver des pages orphelines grâce aux sitemaps
Ce chemin est en fait facile à vérifier pour les pages orphelines et pourtant c’est souvent une méthode qui n’est pas utilisée. Dans la plupart des cas, vous voulez savoir si votre sitemap contient toutes les URLs que vous voulez qu’il contienne. Il est rarement vérifié s’il contient des URLs qui ne peuvent pas être trouvées par un crawl.
Cela se produit typiquement lorsqu’une nouvelle page est créée et qu’elle génère automatiquement un sitemap mais qu’elle oublie de lier la page en interne. Une autre raison peut être les pages seulement supprimées du maillage interne, parce qu’elles ne sont plus considérées comme importantes, mais sans que le sitemap ne soit automatiquement mis à jour. Heureusement, divers outils peuvent aussi aider à contrôler cela. Il n’est pas toujours nécessaire que ce soit un grand nombre d’URLs à trouver ; tout ce qui se situe entre 1-10 peut parfois suffire, comme le montre la capture d’écran suivante.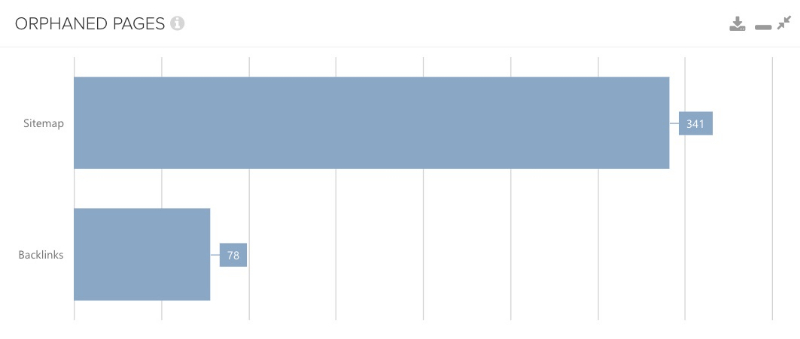
Après la découverte de pages orphelines grâce aux données de sitemap, nous arrivons à un autre ensemble de données passionnant et également important.
Trouver des pages orphelines grâce aux données de la Google Search Console ou d’analytics
Cette comparaison est peut-être la plus intéressante, car les données de Google sont désormais explicitement utilisées. Ainsi, si nous trouvons des pages orphelines en les comparant avec les données de la Google Search Console ou d’Analytics, l’importance de cette découverte peut être un peu plus grande que, par exemple, à travers un sitemap.
Ici, nous pouvons être sûrs que Google connaît ces URLs et que nous ne les avons plus liés en interne. Bien sûr, nous ne supposons pas qu’il s’agit d’une différence d’URL (qui peut avoir été causée par le contrôle du crawler), et nous présupposons toujours que des URLs uniques peuvent être indexées ; (en particulier pas de pages paramètres ou de tri).
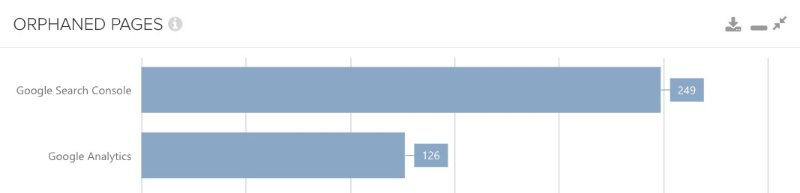
Si d’autres idées vous intéressent, vous pouvez utiliser d’autres sources de données pour trouver des pages orphelines.
Rechercher des pages orphelines à travers les fichiers de logs
J’ai mentionné que la comparaison avec la Google Search Console & Analytics est passionnante, mais je dois aussi dire que la comparaison avec les fichiers de logs est en fait encore meilleure et la raison en est simple : les fichiers de logs sont des données côté serveur qui sont exactes. Les données côté client telles que Google Analytics ou les données de la GSC, pour lesquelles nous ne savons pas d’où elles proviennent, sont ici comme une sorte de “boîte noire”.
Donc, si vous avez vos fichiers de log à portée de main, vous pouvez les utiliser pour faire une comparaison en espérant que le résultat ne ressemble pas à celui de l’image suivante. C’est un état plutôt alarmant.

Si vous n’avez toujours pas assez d’idées pour trouver ces pages orphelines, vous pouvez aussi exporter toutes les pages créées et actives de votre système et les comparer avec l’ensemble des URLs du crawl. Vous serez surpris de voir combien de fois les résultats apparaissent et combien de fois il y a des pages orphelines. Les raisons peuvent être multiples, ce qui nous amène à la section suivante.
Les raisons d’une page orpheline
Nous avons déjà beaucoup travaillé sur la découverte des pages orphelines, mais pas encore sur les raisons de sa création, et celles-ci peuvent être multiples. Voici quelques possibilités, sans prétendre que cette liste soit exhaustive.
- Des pages qui ont été complètement ou successivement supprimées du maillage interne sans être finalement désactivées.
- Des ‘pages de test’ du système marchand, par exemple pour exécuter des tests A/B. Le responsable quitte l’entreprise à un moment donné et plus personne ne connaît ces URLs.
- Les URLs d’un ancien système CRM qui n’ont jamais été complètement désactivées.
- Les landing pages pour des sujets à la mode ou saisonniers qui n’ont jamais été désactivées.
- Une utilisation incorrecte du CMS, qui a généré des pages.
- Des catégories hors ligne n’ont pas été transmises.
- Des pages ont simplement été “oubliées” lors d’une migration.
Le problème avec les pages orphelines
Parfois, il y a des raisons vraiment bizarres qui, aussi amusantes qu’elles puissent paraître, détournent l’attention de la pertinence du sujet. L’une des principales raisons pour lesquelles les pages orphelines peuvent être défavorables, outre le sujet de l’hygiène de l’index, est qu’elles peuvent causer des problèmes dans le ciblage par mot-clé d’un domaine. Par exemple, ces URLs peuvent venir en addition des principaux mots-clés, que personne ne connaît mais qui sont alignées sur le même mot-clé ou des variantes de celui-ci (par exemple ‘frigo vs. réfrigérateur’ etc.), et nuire au succès du classement d’un domaine.
Il serait également défavorable que la mauvaise URL, bien qu’elle ne soit (plus) liée en interne, soit classée parce qu’elle est peut-être historiquement mieux liée en externe que la page plus récente et mieux optimisée ; (oui, parfois les pages ne sont pas non plus transférées !). Il peut également s’agir de la perte du jus de lien qui peut jouer un rôle pour les pages orphelines.
Bien sûr, ces pages devraient toujours être surveillées en terme de trafic. Ce n’est pas pour rien qu’elles sont analysées via Google Analytics. Cependant, il faut également tenir compte du fait que les pages orphelines peuvent perturber la structure des liens d’un domaine, par exemple, si elles se trouvent, de manière hiérarchique, au milieu. Cela signifie que la page orpheline ne fait que des liens vers d’autres pages, qui tombent donc complètement hors de la structure URL parce qu’elles ne sont liées qu’à partir de la page orpheline.
Si vous n’aviez pas encore analysé les pages orphelines de votre domaine, vous savez maintenant ce que c’est, pourquoi c’est important et comment vous pouvez procéder. Espérons que vous ne vous retrouviez pas dans une telle situation :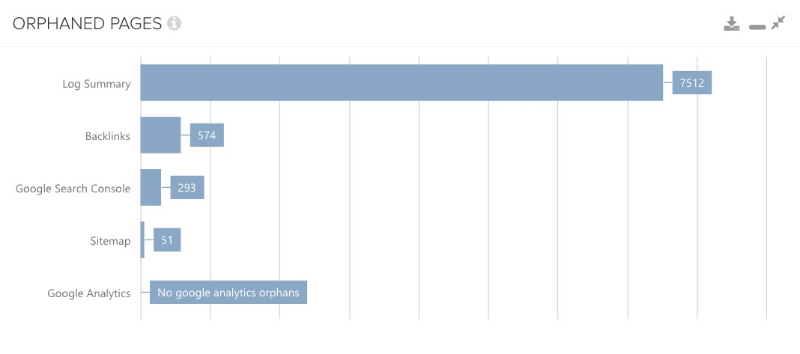
Pourquoi les pages orphelines sont importantes ?
Du point de vue SEO, les pages orphelines signifient que vous pouvez avoir un contenu fort et précieux qui n’est pas lié. Cela signifie que le Trust Flow ou la crédibilité en ligne n’est pas transmise à ces pages, ce qui pourrait aider la visibilité de votre profil. En outre, vos lecteurs et utilisateurs pourraient manquer un contenu potentiellement précieux lors de la recherche de votre site.
Alors un conseil, commencez à identifier ces pages orphelines dès maintenant !