






Ostatnie badanie Incapsula na temat aktywności botów pomogło autorowi zebrać myśli na temat tego, dlaczego mądrzejsze indeksowanie jest lepsze od szybkiego indeksowania. Incapsula już od kilku lat prezentuje raporty z badań. Nowicjusze tak samo jak niektórzy eksperci są zaalarmowani, kiedy zauważają, że tylko połowa ruchu na ich stronach pochodzi od prawdziwych ludzi.
Ten post analizuje niektóre z konsekwencji ścigania się w indeksowaniu, jego wpływu na jakość indeksu oraz niektóre próby spamerów, których celem jest udaremnianie twoich botów. Tak – omówię technikę dotyczącą sieci linków. Naprawdę głupia sprawa, a sprawia, że zapala nam się czerwone światełko.
Dobre i złe boty

Incapsula stwierdziła, że większość światowego ruchu botowego pochodzi od 35 “dobrych” wyszukiwarek (w tym Majestic) i grupy złych wyszukiwarek, którymi dzisiaj nie będziemy się zajmować. Chociaż należy zauważyć, że niektóre szczególnie niewyszukane systemy firewall blokują niektóre boty za pośrednictwem agentów użytkownika, nie dając swoim klientom innego wyjścia. To błędne podejście. Poniżej relatywny wpływ poszczególnych botów na całkowitą przepustowość łącza.
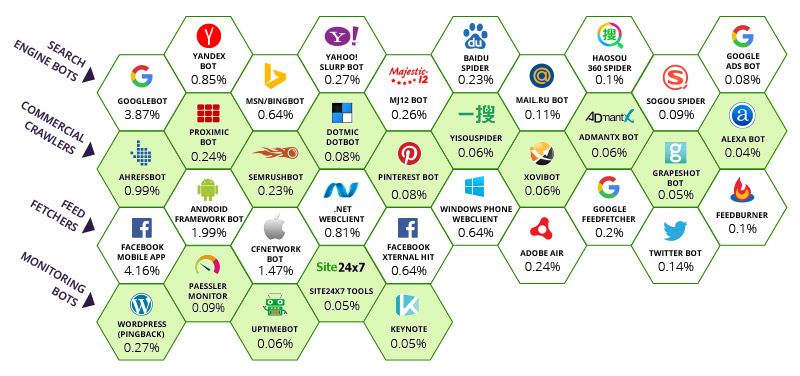
Liczby pod każdym botem reprezentują procent odwiedzin na stronach, które zostały przypisane do każdego bota. A więc na górze, aplikacja mobilna Facebook’a przechwyciła aż 4,16% przepustowości. Google odpowiada za 3,87% przepustowości na całym świecie. Właściwie nawet więcej, jeśli wziąć pod uwagę inne boty w posiadaniu Google. Powiedziałbym, że w gruncie rzeczy taka sytuacja jest sprawiedliwa. Google i Facebook znaczącą przyczyniają się do integracji systemu, który w przeciwnym przypadku byłby chaotyczny, sprawiają, że można nim manewrować i łączyć. Najwyraźniej to cecha wspólna topowych Wyszukiwarek, a Majestic docenia fakt, że Incapsula ujęła Majestic na liscie wyszukiwarek i to z górnej półki. Doceniamy, że mamy kilku konkurentów na naszym poziomie i Majestic nie czuje się tam nie na miejscu.
Znajdując się w rankingu 10 wyszukiwarek, zgodnie z tabelą powyżej, Majestic ma obowiązek wiedzieć, kiedy ZAPRZESTAĆ indeksowania tak samo jak i kiedy indeksować. W społeczności SEO odczuwa się presję, aby wyłapywać „WSZYSTKIE” linki. Albo przynajmniej tyle, ile jest możliwe. Prowadzi to do paradoksu. Kiedy przestaniemy przeszukiwać nieskończoną sieć?
Niekończąca się sieć
Ostatnie wybryki z udziałem Majestic i Międzynarodowej Stacji Kosmicznej były czymś więcej niż chwytem reklamowym. Po części miały na celu podkreślenie nieskończonej natury Internetu. Ta nieskończoność oznacza głębokie konsekwencje dla narzędzi dotyczących linków. Kilka miesięcy temu, Majestic usunął miliardy stron internetowych z swojego indeksowania. Wszystkie te strony były subdomenami generowanymi w locie (automatycznie). To wywołało sporą furorę w tym okresie ze względu na kilka domen, które wykorzystywały przepływ zaufania w wersji „www” domeny (co jest technicznie równoznaczne z wariantem subdomeny) do oceny stron internetowych na sprzedaż na rynkach usług posprzedażnych. Piramida Lego pozwala na wizualizację dylematu:

Wyobraźmy sobie, że ta piramida reprezentuje wszystkie subdomeny w Internecie. Te na górze mają przepływ zaufania na poziomie 90-100 , a te na dole mają przepływ zaufania na poziomie 0. W rzeczywistości … Majestic odkrył, że subdomeny na dole reprezentowały wartość mniejszą niż zero. Nie miały one żadnych linków przychodzących, ale miały za to taką samą domenę główną, a ich liczba wzrastała tak bardzo, że nie były one po prostu rozliczane na najniższym szczeblu, ale i też na następnym poziomie. Algorytm Przepływu Zaufania Majestic opiera się czymś na kształt piramidy, więc im więcej śmieci na dole, tym większy Przepływ Zaufania w przypadku wszystkiego co jest choć trochę lepsze niż spam. Ponieważ jest to niekończący się problem, wyszukiwarka nie jest w stanie go rozwiązać przez zwiększenie zakresu wyszukiwania. Jedyne co osiąga się w ten sposób to, że następny szczebel na drabinie wygląda lepiej niż powinien, a my nadal nie ma czegoś takiego jak „WSZYSTKIE” linki, ponieważ wszystko podzielone przez nieskończoność to nadal duży udział procentowy. Majestic mógłby korzystać z farmy serwerów o wymiarach boiska do piłki nożnej i nadal nie być w stanie rozwiązać problemu. Zamiast tego, Majestic postanowił zrezygnować z dwóch dolnych szczebli. W wizualizacji Lego powyżej, te szczeble stanowią ponad połowę danych! (36 z 70 klocków = 55%). Każdy z nich to strona, której żaden człowiek nigdy nie widział i żadna szanująca się wyszukiwarka nie powinna nigdy brać pod uwagę.
Efekt to zmiana rozmiaru piramidy. Nagle strony, które były na trzecim szczeblem w skali 1-100 znalazły się na najniższym szczeblu. Można sobie wyobrazić panikę, która wybuchła w społeczności domen i jest ona niemal namacalna w komentarzach do tego wątku.
Nie jest to jedyna przyczyna nieskończoności internetu. Sam Majestic.com (i każda wyszukiwarka) tworzy potencjalnie nieskończone pętle po prostu za sprawą swego nadrzędnego celu. Można wprowadzić dowolny zestaw znaków do Majestic.com a system będzie próbował dokonać interpretacji wyników. To z kolei tworzy SERPy (strony będące wynikiem wyszukiwania), a to z kolei tworzy linki. Te linki powinny teraz odwoływać się do stron, które już istnieją, a więc jest to zamknięta pętla, ale same wyszukiwanie url może okazać się z założenia nieskończone. Majestic (i Google) pomaga innym wyszukiwarkom dostrzec te zależności. Obie wyszukiwarki wykorzystują swoje pliki Robots.txt do informowania innych o tym, że prawdopodobnie nie powinni tracić cennych zasobów indeksowania na takie nieskończone adresy URL.
Spamerzy potęgują ten problem
Na początku tego postu wspomniałem, że omówimy “technikę dotyczącą sieci linków”. Zazwyczaj tego nie robię, ale ta konkretna sieć była szczególnie głupia i szczególnie złośliwa jeśli chodzi o MJ12Bot. Zaczynając post zwróciłem również uwagę, że aplikacje klienckie są opcjonalne. Majestic decyduje się na samodzielną identyfikację. Jeśli chcesz, aby Majestic „NIE” indeksował twojej strony, wydaj takie instrukcje korzystając z Robots.txt. NIE rób tego – jak zrobiła to ta sieć linków – dążąc do 301 (przekierowanie) botu Majestic do swojej strony głównej. W efekcie otrzymałem bardzo ciekawy email z powiadomieniem, wskazujący na masowy napływ linków do Majestic.com:
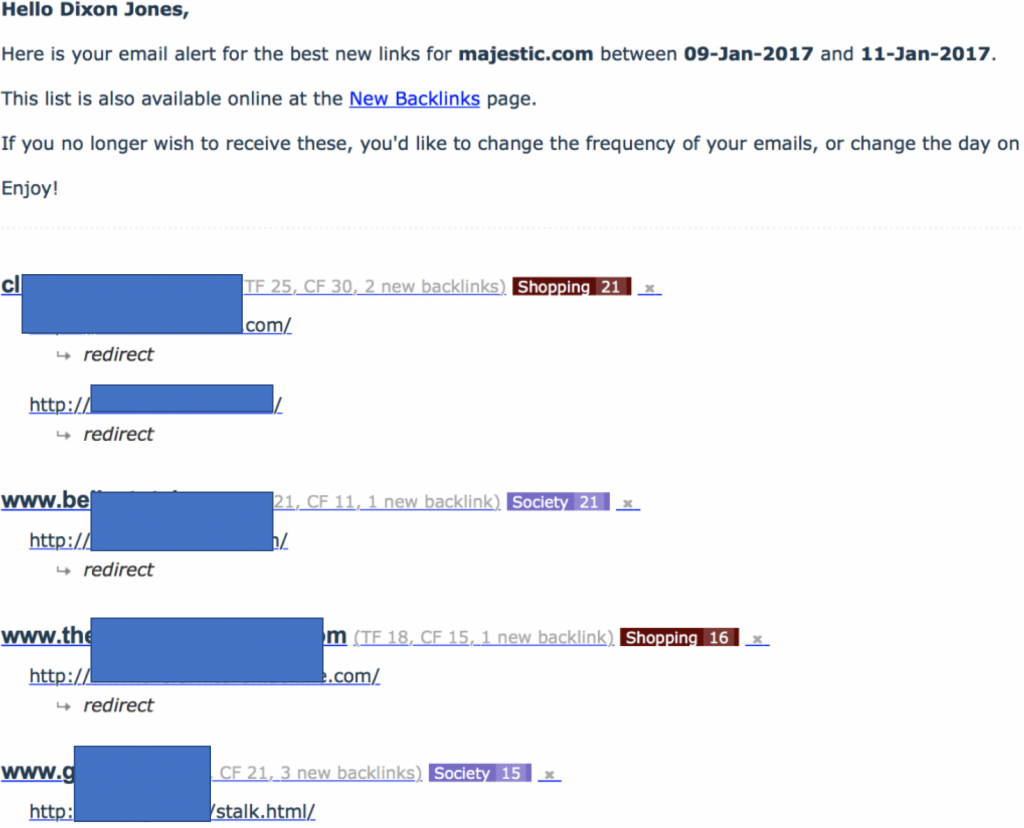
Zauważ, że wszystkie nowo wykryte linki odsyłające do Majestic.com zostały najwyraźniej przekierowane z tych stron. To znak ostrzegawczy, bo kiedy sprawdziłem te strony, znalazłem po prostu fabryki linków, które jednocześnie NIE linkowały do Majestic. Oznaczało to, że te strony maskowały MJ12Bot (ukrywanie treści przed naszym botem). Jestem szczególnie rozbawiony, gdy sieć zaczyna używać nazw takich jak “stalk.html! Gdy oglądamy te strony na normalnej przeglądarce, wszystkie wyglądają tak:
Agenci użytkownika (User agents) są opcjonalni
Ostatnim krokiem w dokładnym opracowaniu tego, co się aktualnie dzieje, było użycie narzędzi firm trzecich w celu sprawdzenia, czy sieć dokonuje przekierowania 301 w oparciu o user agent. Jeśli przyjrzycie się “Http Header Checker” można sprawdzić swoją stronę, ale skorzystanie z Header Checker SEOBook lub użycie Screaming Frog okazuje się szczególnie przydatne, gdyż oba systemy pozwalają zmienić user agent w rozwijanej liście. Mówiąc najprościej – strony te zostały zamaskowanie przez user agent. Jeśli Googlebot lub człowiekowi wchodzi na tą stronę, zobaczą stronę, którą zaprezentowaliśmy powyżej. Jeśli pojawia się MJ12Bot, widzi własną stronę Majestic poprzez przekierowanie 301.
Powrót odpowiedzialnych wyszukiwarek
Sieć podkreśla wyzwanie. Powoduje, że wyszukiwarka patrzy na dwa numery IP, a nie na jeden. Nie ma to dużego znaczenia, zważywszy, że w tym przypadku jedna strona to spamer, a druga to Majestic, ale chcemy podkreślić, że przekierowania 301 nie są doskonałe. Zwiększają obciążenie sieci Internet. Bardziej efektywnym sposobem przekierowania byłoby użycie nazwy zastępczej domeny, ale to powoduje inne problemy dla wyszukiwarek, takie jak to, że kanoniczne (preferowane) domeny mogą być identyfikowane tylko z tabel dns.
Tak więc z niekończącą się siecią i potencjalnie przeładowanymi przekierowaniami oraz wszelkimi innymi sposobami, które komplikują efektywność wyszukiwarki, kontynuacja indeksowania spamu wydaje się nielogiczna… nawet jeśli tylko po to, aby pozbyć się spazmujących linków. O wiele bardziej praktyczne podejście to zebrania wystarczającej ilości danych o stronie, aby zobaczyć linki z każdej kategorii, a następnie przejść dalej. Sztuką jest NIEpobieranie śmieci … bez względu na to czy kosz jest na poziomie stron z nieskończoną ilością stron czy na poziomie subdomeny z nieskończoną liczbą subdomen albo na poziomie strony, gdzie nieskończoność jest bliska powielaniu wyników wyszukiwania lub przekierowań.
Aby tego dokonać wyszukiwarki, które potrafią indeksować w mądrzejszy sposób są w stanie zastosować znacznie mniejsze obciążenie sieci niż te, które indeksują szybciej. Inteligentniejsze indeksowanie działa, gdy wyszukiwarka jest w stanie zrozumieć jeden z następujących sygnałów:
- Czy to ważna strona?
- Czy jest aktualizowana czy statyczna?
- Czy wygenerowano ją automatycznie?
- Czy to spam?
Majestic w szczególności sprawdza się w obserwacji górnych i dolnych poziomów. Metryki przepływu dają Majestic przewagę nad innymi botami, tu skupiam się zwłaszcza na BingBot. Jestem przekonany, że BingBot jest bardziej agresywny niż Majestic, ale nie jestem przekonany czy musi tak być. Może Bing nie ma takiej czystej wartości jak Przepływ Zaufania lub Ranking Strony (tak, oni nadal tego używają), aby wspomóc proces indeksowania, ale nie wierzę, że znajdują o wiele więcej stron wyszukując 250% szybciej niż MJ12Bot. To samo tyczy się naszej konkurencji usytuowanej w drugim rzędzie w tabeli Incapsula.
Lepszym rozwiązaniem – przynajmniej w odniesieniu do Majestic – to wyszukiwanie na tyle wyczerpujące, abyśmy mogli znaleźć wszystkie linki odnoszące się do domen głównych prowadzących do strony, a następnie wykazać i pokazać wystarczająco dużo linków zwrotnych z tej strony tak, aby nasi użytkownicy mogli łatwo zidentyfikować naturę wzoru linków. Tą zależność można prosto uzmysłowić użytkownikom wskazując na zakładkę domen odsyłających. Umieść swoją domenę i sortuj według liczby linków zwrotnych, ustaw na malejące, a zobaczysz licznik linków według domen. Natychmiastowy wgląd uzyskasz na ekranie. Oto własna strona majestic.com:
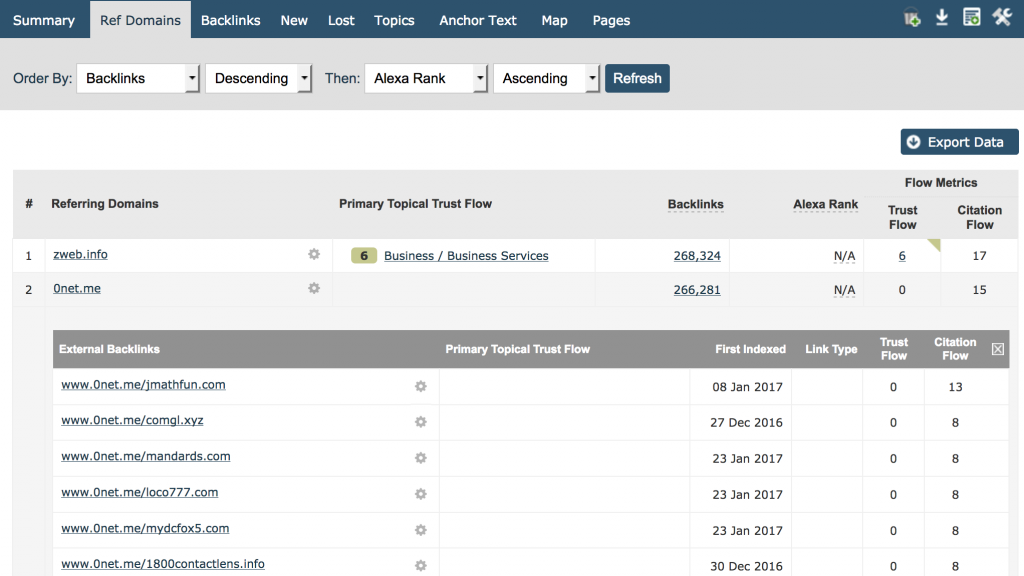
Moim zdaniem wszyscy możemy się zgodzić, że 266,281 linków z www.0net.me nie mówi nam dużo więcej niż, powiedzmy 100.000 linków z www.0net.me!
Zakładka domeny nadaje się idealnie do szybkiej identyfikacji jednych z najgorszych linków spamujących do twojej strony. Przydała się także na potrzeby tego postu przy identyfikacji obszarów, gdzie bot może stać się bardziej inteligentny, a zatem skuteczniejszy w indeksowaniu.
Tani hosting zabija

Inny problem to agresywne boty, które mogą powodować, że many zbyt wiele stron internetowych na tym samym serwerze. Niestety tani hosting wiąże się z tym, że boty mogą się stać większym problemem niż w przypadku bardziej solidnych firm hostingowych. To dlatego, że tani hosting oznacza umieszczanie setek – jeśli nie tysięcy – zaczynając od małych stron internetowych na tym samym serwerze fizycznym. (możesz użyć narzędzia Majestic do sprawdzania z jakimi stronami sąsiadujesz, aby sprawdzić, jak wiele stron jest na twoim serwerze.) Majestic stosuje Opóźnione indeksowanie w pliku robots.txt, ale także zmądrzał, jeśli chodzi o rodzaj stron umieszczonych na tych serwerach. Ma to znaczenie dla ciebie, jak również wtedy, kiedy zależy ci na Google. Googlebot nie stosuje opóźnienia indeksowania! Zamiast tego używa ogólnego limitu na serwerze, aby określić maksymalną szybkość indeksowania dla tej maszyny. Ma to zapobiec nadmiernemu obciążeniu na serwerze. Jeśli witryna ma 1000 innych stron – niektóre ponad 1000 stron więcej niż ty – na tym samym serwerze, trzeba zadać sobie pytanie, jaki właściwie będzie udział indeksowania kiedy Googlebot będzie przeglądał witryny na swojej stronie?
Drzewo decyzyjne służące mądrzejszemu indeksowaniu
Teraz mamy kilka elementów, które mogą pomóc wyszukiwarce w lepszym zarządzaniu własnymi środkami, tym samym zmniejszając wpływ, jaki wywiera na Internet. Takie podejście stwarza sytuację, w której wszyscy wygrywają. Lepsze dane. Szybszy Internet.
Decyzja 1: Odkrywanie czy integralność
W celu utrzymania indeksu sieci według rozmiaru Majestic, czas okazuje się być naturalnym niszczycielem integralności. Każda mijająca sekunda oznacza, że powstają nowe treści, ale także istniejąca zawartość jest niszczona lub zmieniana. Wyobraźmy sobie, że w ułamku sekundy… Majestic ma wybór czy indeksować dalej … URL którego wcześniej nie indeksowano lub ten, który indeksowaliśmy wczoraj. Co wybrać? Nowy? Wspaniale! ale co z następnym wyborem? Co z kolejnymi? Mamy już zidentyfikowane pojęcie nieskończonego internetu, a więc taka logika jest błędna, jeśli NIGDY nie sprawdzasz czy dana strona została zmieniona lub usunięta. Majestic dokonał przełomu w 2010 roku, a w rzeczywistości rozwiązał ten problem, znajdując więcej niż jedno rozwiązanie. Jeśli boty Majestic przeboleją entuzjazm wywołany odkrywaniem stron na rzecz integralności, to nie będziemy bezpieczni w razie awarii w Świeżego Indeksu, bo po 90 dniach, strona, która nie została ponownie indeksowana wypadnie z indeksu całkowicie. Oznacza to, że świeży indeks nigdy nie będzie zawierał danych, które mają ponad trzy miesiące. Na szczęście jednak rzadko się to zdarza … przynajmniej nie w przypadku stron, na których ludziom naprawdę zależy … ponieważ nasze wskaźniki przepływu pomagają nam ustalić priorytety w bardziej zrównoważony sposób, tak, że ważne strony mogą być przekształcane z większą częstotliwością niż te mniej wpływowe. Gdyby Majestic polegał wyłącznie na liczbie linków przy podejmowaniu tych decyzji, wówczas wymagana przepustowość wzrosłaby w znacznym stopniu.
Decyzja 2: Głębokość wyszukiwania
Ile stron wystarczy !? Katalog spam ma więcej stron internetowych niż BBC! A BBC na pewno potrzebuje indeksowania WSZYSTKICH stron i to regularnie, nieprawdaż? Cóż, niekoniecznie. BBC generuje wiadomości, które ze względu na swój charakter, stają się starymi wiadomościami. W końcu w ogóle przestają być jakąkolwiek nowością, a ostatecznie nawet BBC porzuca taką stronę. Jeśli chodzi o wcześniejszy etap BBC ma tendencję do osieracania stron, dzięki czemu można je znaleźć jedynie poprzez wyszukiwarkę używając linka pochodzącego od strony trzeciej. Problem staje się jeszcze bardziej skomplikowany w przypadku stron takich jak eBay i Mashable, gdy zawartość jest tworzona przez użytkowników i mamy do czynienia z szarą strefą pomiędzy jakością i ilością. Wtedy wskaźniki przepływu pomagają ogromnie. Inne narzędzia z branży SEO są w stanie zastosować inne taktyki przy podejmowaniu tak ważnych decyzji. W szczególności mogą one znaleźć zastępstwo dla “jakości” poprzez przeczesywanie SERPów Google na dużą skalę, a następnie wykorzystują podgląd widoczności, który pomaga im w podjęciu tej decyzji. Nie posiadam informacji na temat tego czy tak postępują, ale biorąc pod uwagę, że sprawdzają dane SERPs na dużą skalę, czy miałoby to jakiś sens gdyby nie traktowali ich jako sygnał.
Ale ostatecznie znów musimy chronić nasze wyszukiwarki przed problemem jakim jest nieskończoność Internetu. Musimy też unikać indeksowania tych samym stron (lub serwerów), i to w dużym stopniu, gdyż ma to wpływa na czas oczekiwania prawdziwych użytkowników.
Decyzja 3: Czego się pozbyć
Miałem zamiar zastosować nagłówek “Ilu twardych dysków potrzebujesz”, ale ostatecznie nie jest to teoretyczna decyzja, którą musimy podjąć. Rozumiejąc, że problem indeksowania jest z natury nieskończony, ostatecznie należy zapytać “co odrzucić”. Jakie dane są tak bezużyteczne w odniesieniu do indeksowania, że w ogóle nie powinny być indeksowane – z wyjątkiem być może prób wyplenienia innych złych treści – w celu usunięcia raka trawiącego dane. Dlatego Majestic odnosił sukcesy w tej walce w ciągu ostatnich miesięcy, a efekty są imponujące, mówiąc skromnie. W takiej sytuacji dążenie do szybszego indeksowania wydaje się po prostu irracjonalne.
- Nowa funkcja: Linki wychodzące i aktualizacja języków - October 26, 2017
- Nowość: Wskaźniki linków wychodzących, tytuły i nie tylko - October 16, 2017
- Majestic i SEMRush łączą siły - October 11, 2017