






Już nie od dziś wiemy, że Google rozumie intencję każdego wyszukiwania. Wpisując w Google „psi fryzjer” zauważysz, że wyszukiwarka pokazuje Ci strony „Groomerów”. Mimo że to technicznie inne słowa, to intencja pozostaje ta sama. Czy to magia? Nie. Matematyka.
Za tym zachowaniem stoi pojęcie zwane podobieństwem cosinusowym (ang. cosine similarity). Brzmi jak coś z podręcznika do analizy matematycznej, ale w praktyce chodzi o jedną prostą zasadę: zamiast porównywać słowa do słów, systemy AI zamieniają teksty na liczby, a potem mierzą kąt między nimi. Im mniejszy kąt, tym większa zbieżność znaczeń.
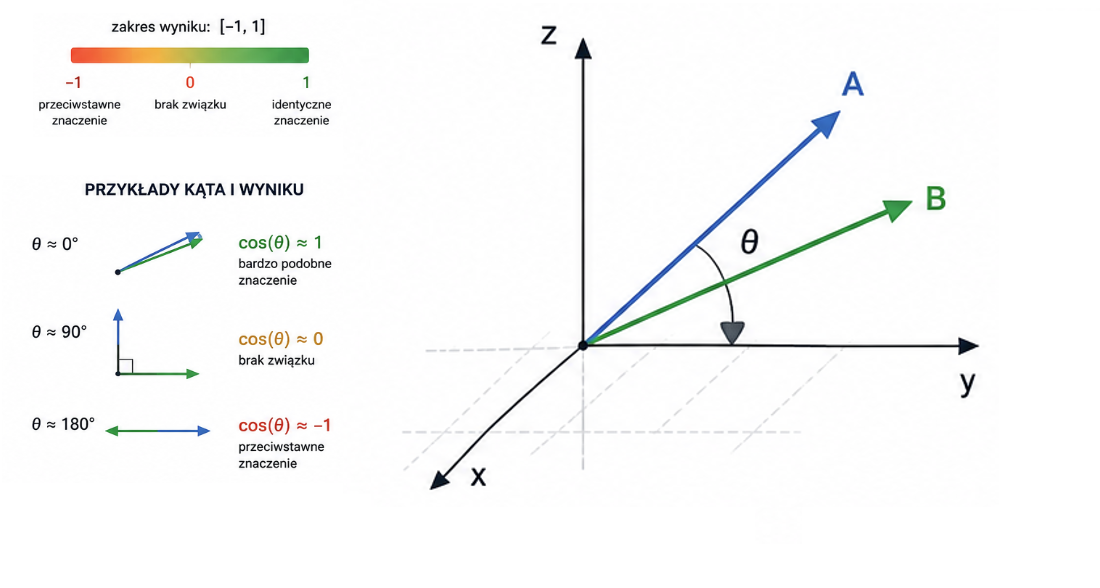
Dwie strzałki w przestrzeni
Wyobraź sobie dwie strzałki wychodzące z tego samego punktu. Gdy wskazują niemal ten sam kierunek, kąt między nimi jest bliski zeru. Cosine similarity to właśnie cosinus tego kąta. Standardowo przyjmuje wartości od -1 do 1, ale w SEO najczęściej spotyka się zakres 0–1, ponieważ wektory embeddingów zwykle mają dodatnie relacje semantyczne. Wynik 1 oznacza identyczne znaczenie. Zero – brak jakiegokolwiek związku. Wartość ujemna wskazuje przeciwstawne pojęcia. Ale żeby porównywać teksty wektorami, trzeba najpierw zamienić słowa na liczby. Właśnie tu wchodzi wektoryzacja.
Źródło: opracowanie własne z wykorzystaniem AI (ChatGPT, OpenAI).
Najstarsze metody po prostu liczyły, ile razy dane słowo pojawia się w dokumencie. Ignorowały kontekst i kolejność. Krok wyżej to TF-IDF: ta metoda waży słowa na podstawie ich unikalności w całym zbiorze dokumentów. Jeśli dany termin występuje rzadko w bazie danych, ale często pojawia się w Twoim artykule, algorytm nadaje mu wysoką rangę. To on decyduje, co jest faktycznym znacznikiem tematu na Twojej stronie.
Prawdziwa zmiana zaczęła się od embeddingów, czyli wektorowych reprezentacji słów i zdań tworzonych przez modele takie jak Word2Vec, GloVe czy BERT.
Słowa o podobnym sensie lądują blisko siebie w tej wielowymiarowej przestrzeni. Dlatego np. „Apple” w kontekście owoców trafia do zupełnie innego miejsca niż „Apple” jako firma technologiczna.
Co ujawnił wyciek dokumentów Google z 2024 roku?
Branża SEO od lat dyskutuje, czy Google oficjalnie stosuje cosine similarity. Google nie potwierdza publicznie żadnej konkretnej metryki. Dokumentacja BigQuery, potężnego narzędzia do analizy danych, wprost wskazuje cosine similarity jako fundament wyszukiwania semantycznego. OpenAI stosuje identyczne rozwiązanie. Skoro rynkowi liderzy używają tej samej miary, trudno o lepszy dowód na jej znaczenie.
Ujawnione dokumenty Google rzuciły nieco więcej światła na mechanikę. Według ich analizy system używa metryk takich jak SiteFocusScore, SiteRadius, SiteEmbeddings i PageEmbeddings. SiteFocus sprawdza, czy konsekwentnie trzymasz się jednej dziedziny, a SiteRadius mierzy, jak bardzo nowe osadzenia (embeddings) podstron odbiegają od rdzenia witryny. Google tworzy matematyczny portret Twojej marki i każdą treść ocenia właśnie przez ten pryzmat.
To wyjaśnia, dlaczego serwisy „o wszystkim” tracą na znaczeniu. Artykuł o kryptowalutach wrzucony na portal kulinarny rozmywa profil wektorowy, co algorytm natychmiast wychwytuje jako błąd. Algorytm po prostu nie lubi szumu.
Kiedy wpisujesz „noclegi w Rzymie”, Google w czasie poniżej jednej dziesiątej sekundy przeszukuje biliony stron i zwraca wynik dopasowany do Twojej lokalizacji i czasu zapytania. Ten proces nie byłby możliwy bez operowania na wektorach. Fizyczna analiza każdego słowa w każdym dokumencie byłaby za kosztowna obliczeniowo. Systemy embeddingowe pozwalają odrzucać „szum” na etapie wyszukiwania i skupiać się na 2–3% stron, które naprawdę leżą blisko danego tematu w przestrzeni semantycznej.
Także tutaj backlinkowy przykład jest równie wymowny. Jeśli Twoja strona o noclegach w Rzymie zdobywa linki z serwisów o usługach prawniczych, Google je ignoruje. Widzi te linki jako semantycznie odległe – nie mieszczą się w klastrze tematycznym, który mógłby wzmocnić sygnał dla zapytania o Rzym.
Progi, które warto znać aby unikać kanibalizacji
Z punktu widzenia SEO najciekawsze jest jednak to, że podobieństwo cosinusowe nie służy wyłącznie do dopasowywania wyników wyszukiwania. Tę samą logikę można wykorzystać do analizy własnego serwisu. Jeśli dwie podstrony zawierają odpowiedzi na to samo pytanie użytkownika to w efekcie zaczynają ze sobą konkurować o widoczność w Google zamiast wzajemnie się wspierać. To właśnie zjawisko znane w SEO jako kanibalizacja treści. Dzięki embeddingom i podobieństwu cosinusowemu można dziś zmierzyć je matematycznie, zamiast oceniać wyłącznie „na oko”.
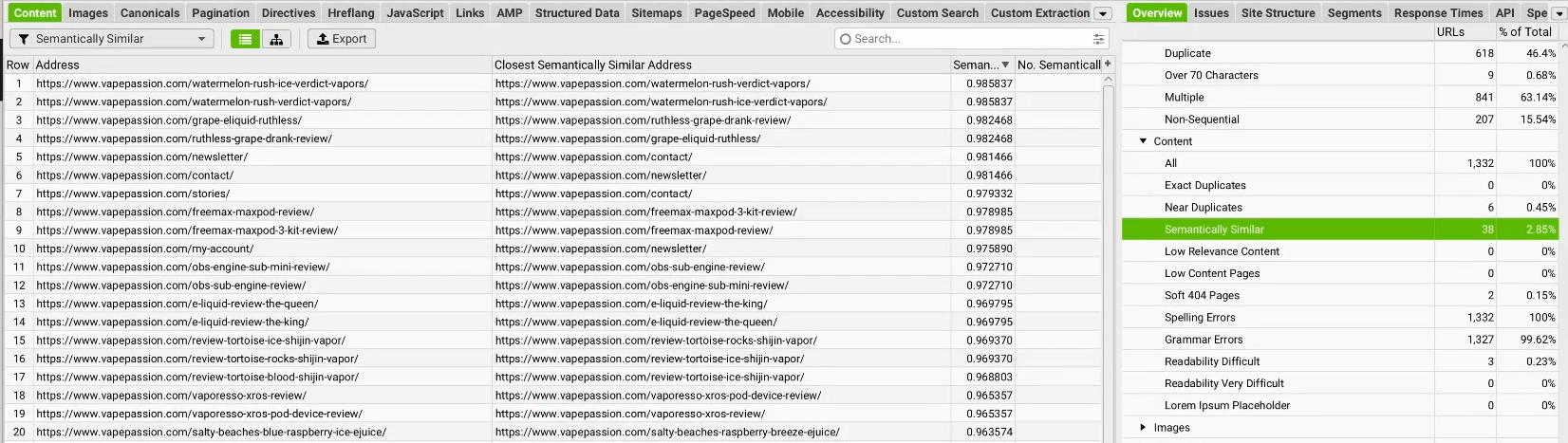
Źródło: youtube.com How to Use LLMs in Screaming Frog for Smarter Content Analysis
Screaming Frog zintegrowany z Google Gemini API stosuje domyślny próg 0,95 do wykrywania treści identycznych tematycznie. To krytyczna granica, powyżej której masz do czynienia z kanibalizacją treści. Masz dwa identyczne teksty? Połącz je albo jeden usuń.
Pięć zastosowań w codziennej pracy SEO
Podobieństwo cosinusowe to matematyczna metoda, która pozwala sztucznej inteligencji ocenić, jak bliskie znaczeniowo są dwa teksty (w skali od 0 do 1). Oto jak możesz wykorzystać tę technologię w codziennej pracy nad widocznością strony:
Kanibalizacja treści
Jeśli masz kilka stron na zbliżone tematy, wektorowe porównanie pokaże, czy nie konkurują o tę samą intencję, nawet jeśli słownictwo się różni. Wynik powyżej 0,95 to sygnał natychmiastowej interwencji.
Przykład: Jeśli posiadasz na blogu kilka artykułów o podobnej tematyce, sztuczna inteligencja potrafi ocenić, czy nie konkurują one ze sobą w Google o te same intencje użytkownika – nawet jeśli używasz w nich zupełnie innych słów. Wynik podobieństwa cosinusowego powyżej 0,95 oznacza to, że artykuły są niemal identyczne i wymagają natychmiastowego połączenia lub ustawienia tagów kanonicznych.
Klastry tematyczne i linkowanie wewnętrzne
Screaming Frog po integracji z API modelu AI pozwala na masowe pobieranie embeddingów całej witryny i identyfikację najlepszych par do linkowania na podstawie znaczenia, a nie ręcznego przeszukiwania. Strony o współczynniku podobieństwa między 0,6 a 0,8 to idealni kandydaci na wzajemne linkowanie. Są powiązane tematycznie, ale nie są swoimi duplikatami.
Content gap
Zamiast zgadywać, czego brakuje w Twoim artykule (lub na Twojej stronie), możesz porównać semantycznie swój tekst z tekstami konkurencji z TOP3 w Google. Taka analiza wskaże różnice w przestrzeni znaczeniowej, pokazując jakich konkretnych podtematów, definicji lub pytań brakuje w Twojej treści, aby stała się ona najbardziej kompletnym źródłem informacji dla wyszukiwarki.
Optymalizacja pod odpowiedzi AI
Nowoczesne wyszukiwarki działają w systemie RAG (Retrieval-Augmented Generation). . Gdy użytkownik zadaje pytanie, sztuczna inteligencja najpierw szuka pasujących tekstów przez podobieństwo semantyczne, a potem wybiera te, które dają najlepszą odpowiedź. Aby Twoja strona była cytowana przez AI, bliskość tematu nie wystarczy. Treść musi być konkretna – precyzyjny akapit z definicją i liczbami ma znacznie większą szansę na znalezienie się w podsumowaniu AI niż ogólny, lany tekst o trendach.
Inteligentne rekomendacje w e-commerce (Cross-selling)
W sklepach internetowych technologia ta pozwala stworzyć sekcje typu „Może Ci się spodobać”, które działają bez sztywnych ram kategorii. Model AI analizuje opisy, cechy i specyfikacje produktów, zamieniając je na punkty na cyfrowej mapie znaczeń. Produkty pasujące do tego samego stylu życia lądują blisko siebie. Dzięki temu klient oglądający drewniany stół w stylu skandynawskim zobaczy pod nim rekomendację lnianego obrusu lub minimalistycznego wazonu, mimo że te przedmioty leżą w zupełnie innych kategoriach sklepu.
Narzędzia, które warto znać
Dla praktyków bez doświadczenia programistycznego platformy contentowe takie jak Surfer SEO, Contadu czy Neuronwriter mierzą pokrycie tematyczne i sugerują brakujące pojęcia.
Screaming Frog po podłączeniu do Gemini API pobiera embeddingi masowo ze stron, a potem pozwala przeszukiwać zawartość witryny semantycznie, co jest szczególnie przydatne przy linkowania wewnętrznym i analizie kanibalizacji w dużych serwisach.
Dla bardziej zaawansowanych analiz Python oferuje biblioteki takie jak Scikit-learn, Gensim, spaCy czy Hugging Face Transformers – pozwalają budować własne modele i przeprowadzać dokładne obliczenia na niestandardowych zbiorach danych.
Google Search Console to obowiązkowe narzędzie seowca. Pokazuje realne zapytania, na które strona pojawia się w wynikach. To dane prosto od Google, które pozwalają ocenić, czy strategia idzie w dobrym kierunku.
Majestic uzupełnia tę układankę od strony profilu linkowego. Jego autorska metryka Topical Trust Flow przypisuje każdą domenę do jednego lub kilku tematycznych koszyków (np. Travel, Law, Finance) na podstawie tego, skąd pochodzi jej autorytet linkowy. W praktyce to semantyczna klasyfikacja sieci odnośników: jeśli linki do Twojej strony płyną głównie z serwisów turystycznych, Majestic zakoduje Twoją domenę jako tematycznie zbliżoną do podróży. Google nie jest jedynym systemem, który widzi te tematyczne odległości — i właśnie dlatego backlink z serwisu prawniczego na stronę o noclegach w Rzymie nie wzmacnia sygnału nie tylko w matematyce embeddingów, ale też w Topical Trust Flow. Analizując profil linków przez pryzmat tej metryki, możesz sprawdzić, czy Twoje zewnętrzne sygnały są semantycznie spójne z tematyką serwisu — albo czy przypadkowe odnośniki rozmywają Twój tematyczny wektor w oczach algorytmów.
Dlaczego to ma znaczenie teraz
Musimy pamiętać, że wysoki wynik podobieństwa semantycznego nie gwarantuje od razu wysokiej pozycji. Ranking Google uwzględnia autorytet domeny, UX, szybkość ładowania, Core Web Vitals, backlinki i dziesiątki innych czynników. Cosine similarity pomaga wskazać, gdzie treść mija się z intencją, gdzie strony się kanibalizują i gdzie warto dołożyć brakujące fragmenty odpowiedzi. Ale decyzja strategiczna zawsze pozostaje po stronie człowieka.
Kilka lat temu budowanie widoczności opierało się na prostym schemacie: fraza w tytule, fraza w nagłówkach, meta tagi, linki. Ten model wciąż działa, ale coraz częściej przestaje być wystarczający. Systemy AI coraz precyzyjniej oceniają, czy treść naprawdę odpowiada na problem użytkownika, czy tylko zawiera odpowiednie słowa.
Semantycznie kompletne treści (z definicjami, przykładami, logicznie rozbitą strukturą i fragmentami, które odpowiadają na konkretne pytania), zbierają widoczność na wiele wariantów zapytań jednocześnie. Nie trzeba tworzyć dziesiątek „byle jakich” podstron pod każde słowo kluczowe. Jeden dobrze napisany materiał wystarczy.
Matematyka tu nie kłamie. Albo Twoja treść leży blisko intencji użytkownika w przestrzeni semantycznej, albo nie.
Natomiast integracja BigQuery z Looker Studio pozwala na tworzenie interaktywnych raportów, które łatwo dostosować do potrzeb biznesowych. Choć dane z Search Console można wizualizować w Looker Studio bezpośrednio, to korzystanie z BigQuery oferuje kluczową przewagę – dostęp do pełnej historii danych bez ograniczeń czasowych, w przeciwieństwie do 16-miesięcznego limitu w Search Console.
Autor artykułu

Anna Jurczyk-Wojnar
SEO Specialist w DevaGroup
W DevaGroup odpowiada za prowadzenie kampanii SEO, przeprowadzanie audytów i optymalizację stron internetowych klientów. Prywatnie miłośniczka podróży, aktywnego stylu życia oraz psów rasy Border Collie.
