






Czas poświęcony na wypełnianie raportów dla wszystkich klientów i prezesów można liczyć w dziesiątkach godzin. Dlatego warto zautomatyzować chociaż część tego procesu. W tym tekście znajdziesz przydatne wskazówki, jak wykorzystując Google Spreadsheets oraz XPath zaoszczędzić swój czas.
Co to jest xPath?
XPath jest to język służący do adresowania części dokumentu XML. Możemy wykorzystać go do odnoszenia się do znaczników w drzewie HTML strony internetowej. Prostszym językiem i adaptując do HTML – dzięki regułom języka XPath jesteśmy w stanie odwołać się do określonych elementów HTML na stronie internetowej, a następnie pobrać ich zawartość.
Funkcja importXML w Google Docs
W arkuszach Google Spreadsheets dostępna jest funkcja
=importXML()
Zgodnie z jej opisem, importuje ona dane z ustrukturyzowanych dokumentów. To właśnie z jej pomocą będziemy pobierać ze strony interesujące nas znaczniki HTML, ich zawartość oraz atrybuty.
Składnia funkcji importXML
Funkcja importXML składa się z:
- adresURL – adresu URL którego drzewo XML będziemy przeszukiwać (w adresie URL musi być protokół http:// lub https:// – funkcja tego wymaga),
- regułaXPath – reguły w języku XPath (musi być umieszczona w cudzysłowach),
- lokalizacja – informacji o lokalizacji, która pomoże poprawnie pobrać stronę w zależności od języka (przydatne przy parsowaniu danych; nie jest obowiązkowe).
Tak więc ostatecznie otrzymujemy:
=importXML(adresURL, regułaXPath, lokalizacja)
i według powyższych wytycznych ją wypełniamy.
Przykłady użycia:
Poniżej kilka przykładów innego wykorzystania funkcji importXML.
Przykład I
Pracując nad audytem treści na stronie, wcale nie musimy posiadać narzędzi typu Screaming Frog, które skanują wskazane adresy URL. Podstawowe parametry tekstu dla strony, takie jak znacznik title czy nagłówek h1 możemy pobrać stosując funkcję:
=importXML(B2;"//h1";"pl") oraz =importxml(B2;"//title";"pl").
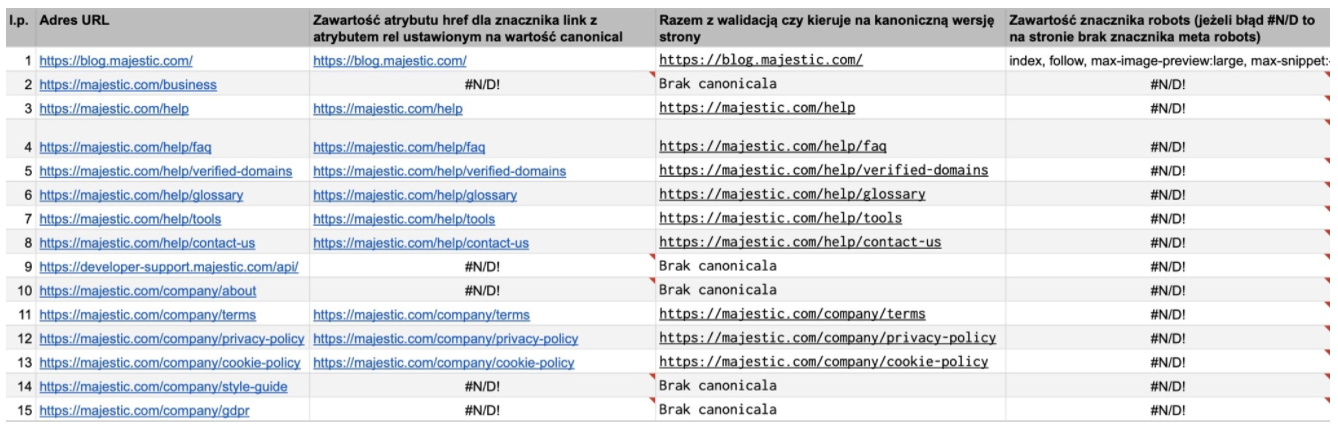
Uwaga: warto zadbać, aby reguła pobierała tylko pierwsze lub konkretnie określone występowanie adresu danego elementu na stronie (otrzymamy to poprzez dodanie nawiasu kwadratowego z liczbą w środku; liczba wskazywać będzie, które wystąpienie np. nagłówka ma zostać pobrane). W przypadku kilku sprawdzonych podstron w domenie https://majestic.com powinniśmy pobrać drugi nagłówek h1, zamiast pierwszego – reguła XPath wygląda wtedy następująco:
(//h1)[2]

Przykład 2
W ten sposób możemy również stworzyć prosty arkusz, dzięki któremu będziemy mogli szybko sprawdzić, czy na monitorowanej przez nas stronie nie zmieniły się znaczniki takie jak:
- canonical,
- meta,
- title.
W przypadku znacznika canonical, wystarczy funkcja:
=Importxml(B2;"//link[contains(@rel,'canonical')]/@href";"en")
Przykład 3
Nie jest wcale powiedziane, że w naszej regule, zawsze musimy odnosić się do wszystkich elementów jakie zostaną znalezione na stronie. Możemy pobrać też ze strony tylko linki (znaczniki <a>) znajdujące się w określonym elemencie blokowym na stronie. Stosując funkcje:
=Importxml(D6;"(//nav/ul/li/a/@href)")
oraz
=Importxml(H6;"(//nav/ul/li/ul/li/a/@href)")
pobierzemy ze strony https://t3n.de/news/google-alternative-474551/ linki z menu głównego, zarówno z pierwszego jak i drugiego poziomu.
Pobieranie danych do raportu
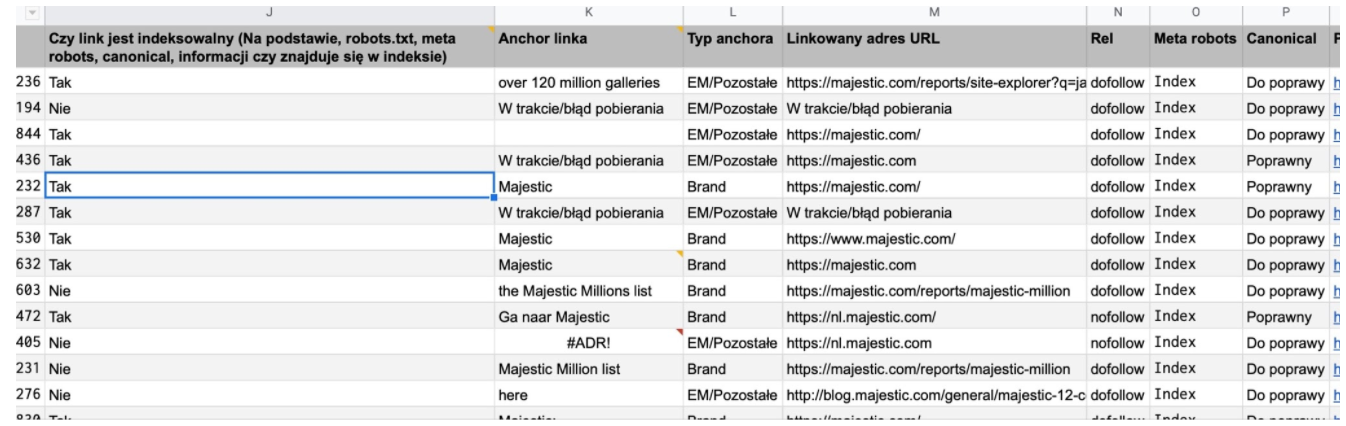
Znając już funkcję import XML, musimy teraz określić, czego potrzebujemy w naszym raporcie oraz utworzyć reguły XPath dla każdego elementu. Do raportu będziemy musieli ręcznie skopiować adresy URL na których znajdują się linki (pobrane np. z eksportu z platformy content marketingowej typu Linkhouse). Tych adresów URL będziemy używać w Google Spreadsheets. W pełnym raporcie powinny się znaleźć informacje o:
- Linkowanym adresie URL
(//a[contains(@href,’linkowanadomena.pl’)]/@href)[1] - Anchorze linku
(//a[contains(@href,’linkowanadomena.pl’)])[1] - Atrybutach rel linku
(//a[contains(@href,’skupszop.pl’)]/@rel)[1] - tym, czy nie ma blokady przed indeksacją meta robots noindex
(//meta[contains(@name,’robots’)]/@content)[1] - tym czy wartość atrybutu href znacznika link z atrybutem rel canonical nie wskazuje na inny adres URL?
(//link[contains(@rel,’canonical’)]/@href)[1]
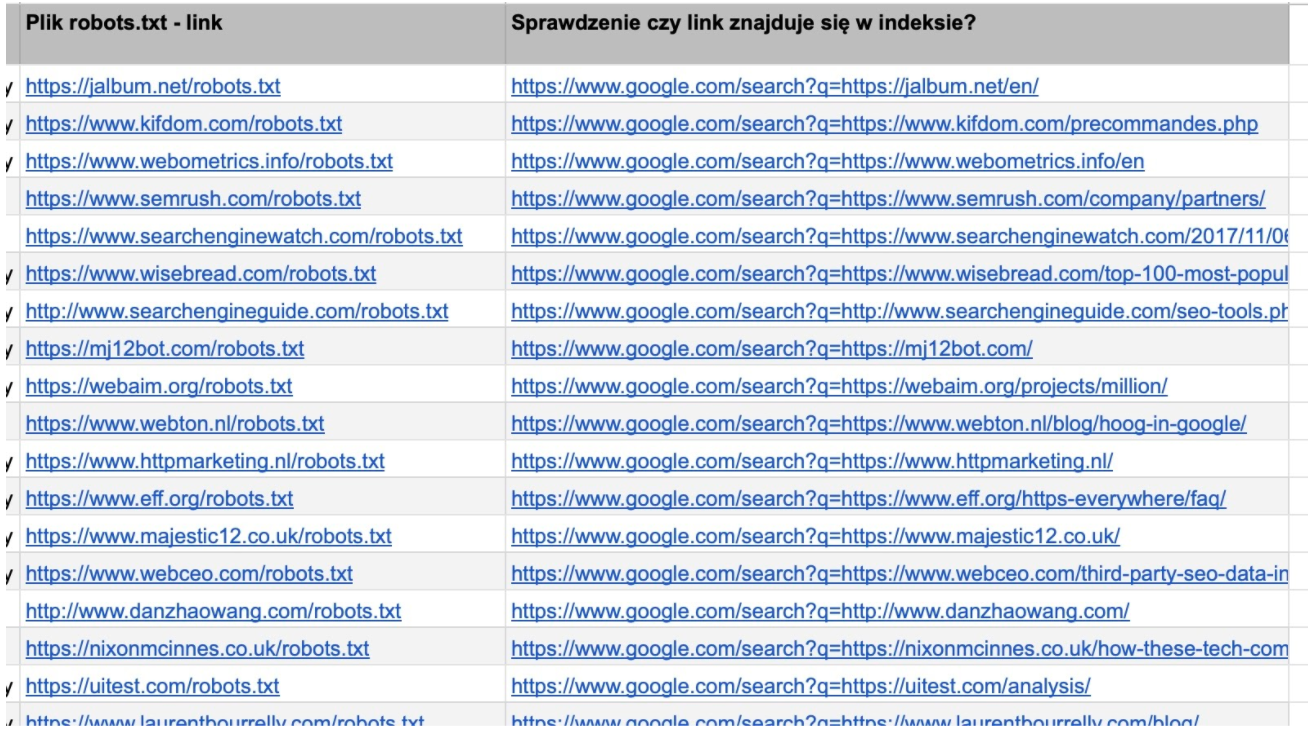
Dodatkowo możemy automatycznie wygenerować linki, aby móc ręcznie sprawdzić, czy strona:
- nie jest blokowana w pliku robots.txt:
Przykładowo możemy zrobić to, stosując funkcję Lewy oraz Znajdź. Poniżej przykład zastosowania tych funkcji tak, aby wybierać z adresu URL tylko główny katalog domeny.
=LEWY(B2;ZNAJDŹ("/";B2;9))&"robots.txt"
- jest zaindeksowana:
="https://www.google.com/search?q="&B2
Dla porządku powinniśmy również zadbać o oznaczenie każdego pozyskanego linku:
- datą jego pozyskania (np. sierpień 2021)
- informacją, w jaki sposób został pozyskany (publikacja sponsorowana, outreach, szeptanka, strona zapleczowa itd.)
- informacją, na ile słów kluczowych jest widoczna domena, z której pozyskaliśmy link (przykładowo poprzez API Senuto i następnie poprzez skrypt zaimportować do Google Spreadsheets).

Co jeszcze powinien zawierać raport linków zewnętrznych?
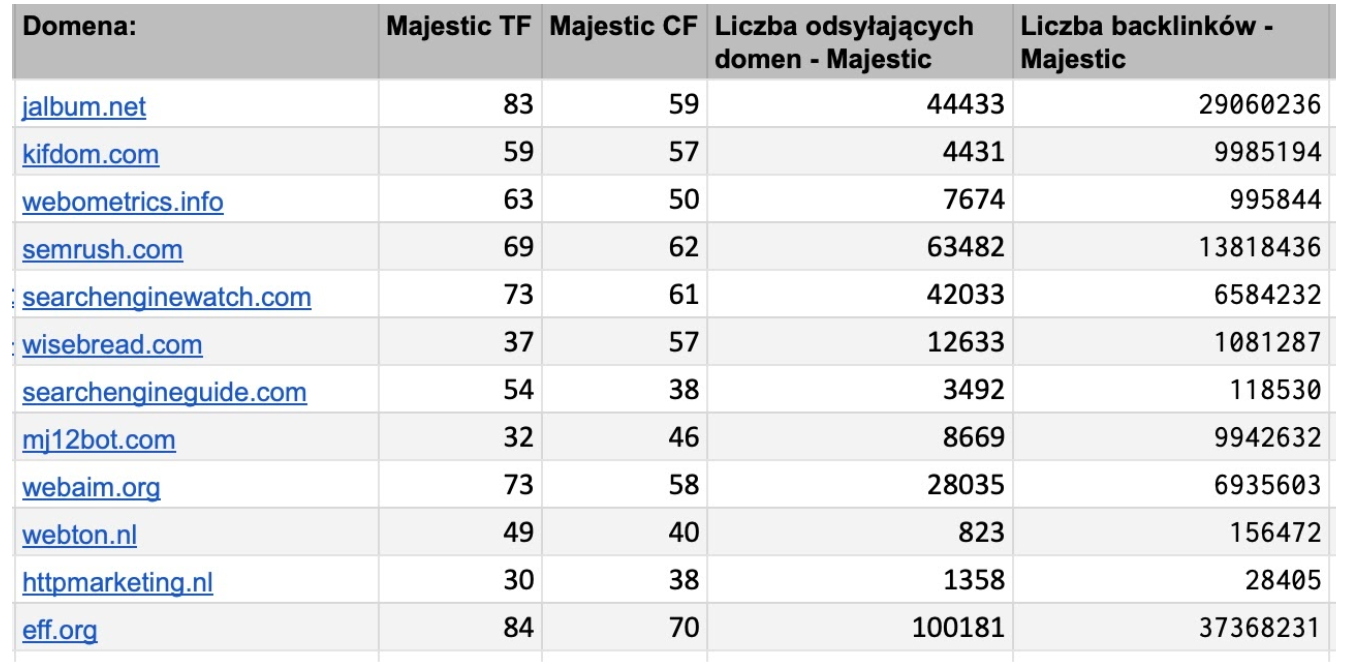
Poza dokładnymi informacjami dotyczącymi nowo pozyskanych linków, powinniśmy również zadbać o przesłanie do klienta informacji o aktualnym stanie całej witryny. W związku z tym powinniśmy pobrać (ręcznie lub przez API i następnie skryptem automatycznie umieścić w pliku Google Docs) statystyki witryny, takie jak:
- współczynniki Citation Flow oraz Trust Flow,
- liczbę odsyłających do serwisu domen,
- liczbę odsyłających do serwisu backlinków,
- liczbę pozyskanych i liczbę utraconych kierujących do serwisu domen z ostatniego miesiąca.
Wykresy
Do arkusza powinniśmy dodać również wykresy prezentujące zmieniającą się w czasie liczbę domen

i backlinków kierujących do naszej strony.
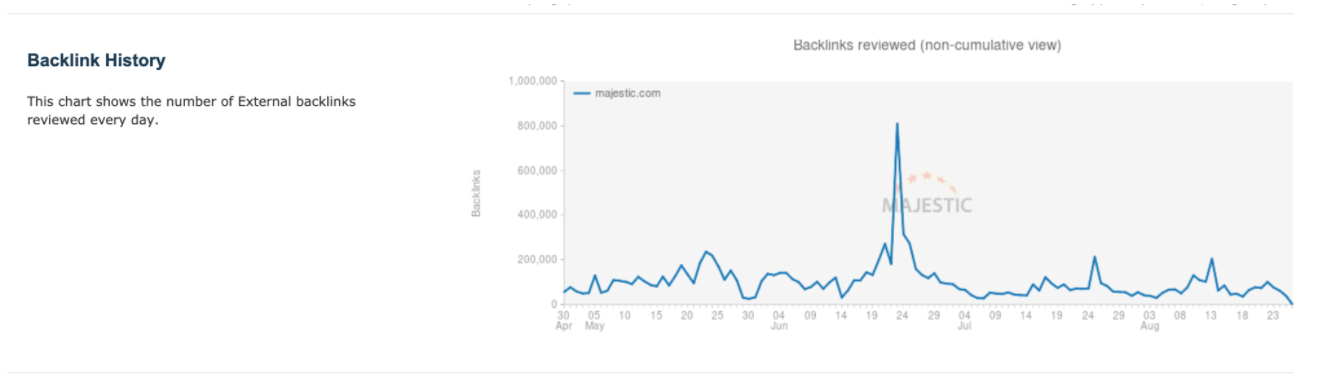
Opcjonalnie w raporcie możemy również umieścić wykres, na którym od liczby pozyskanych w danym miesiącu domen odejmiemy liczbę utraconych w tym miesiącu domen, dzięki czemu uzyskamy dokładne informacje, jak zmieniała się liczba domen, linkujących do naszego serwisu.
Historia kampanii pozyskiwania linków
Rozpoczynając kampanię link buildingową, czasem wyznacza się również potencjalne domeny – miejsca, skąd możemy pozyskać linki do strony klienta. Taką listę można przygotować na podstawie domen konkurencji biznesowej lub internetowej. Dzięki umieszczeniu w arkuszu tak przygotowanej listy, jesteśmy w stanie automatycznie weryfikować, które z wyznaczonych w kampanii linków już pozyskaliśmy i w jakim stopniu zrealizowaliśmy tę kampanię.
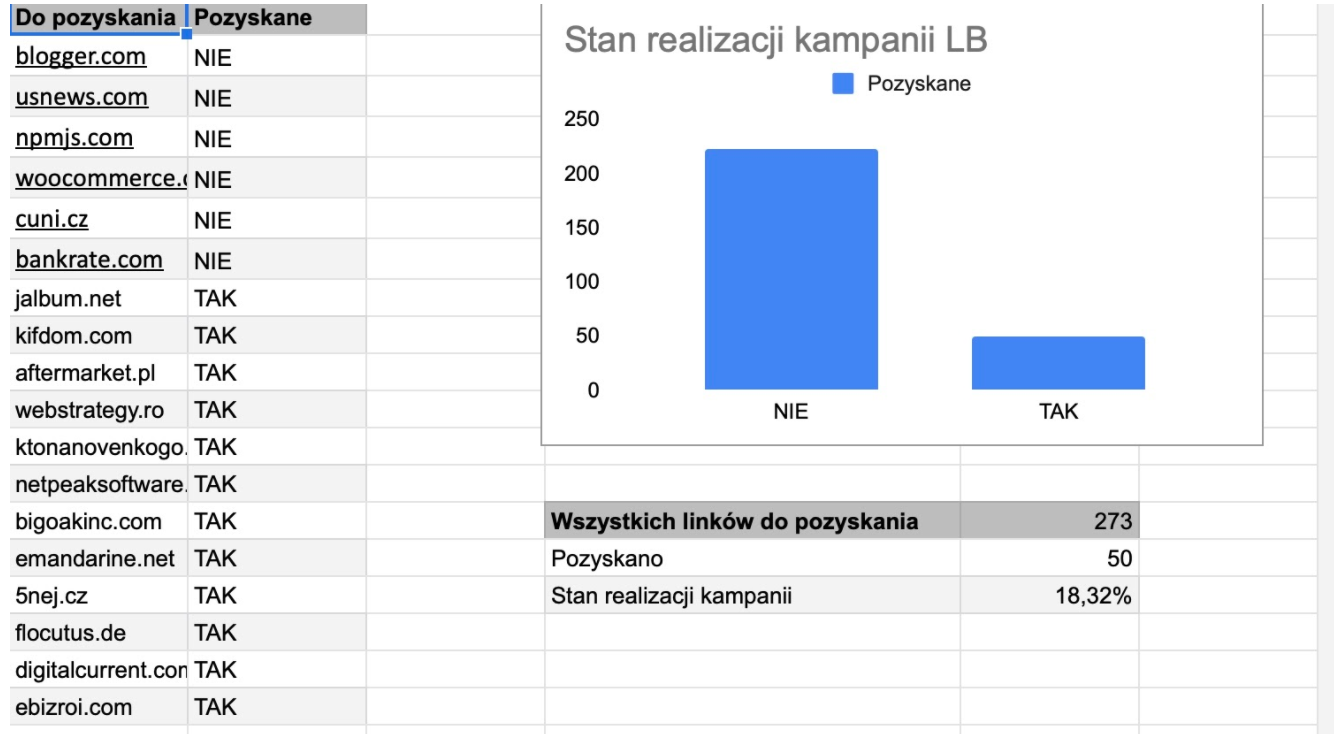
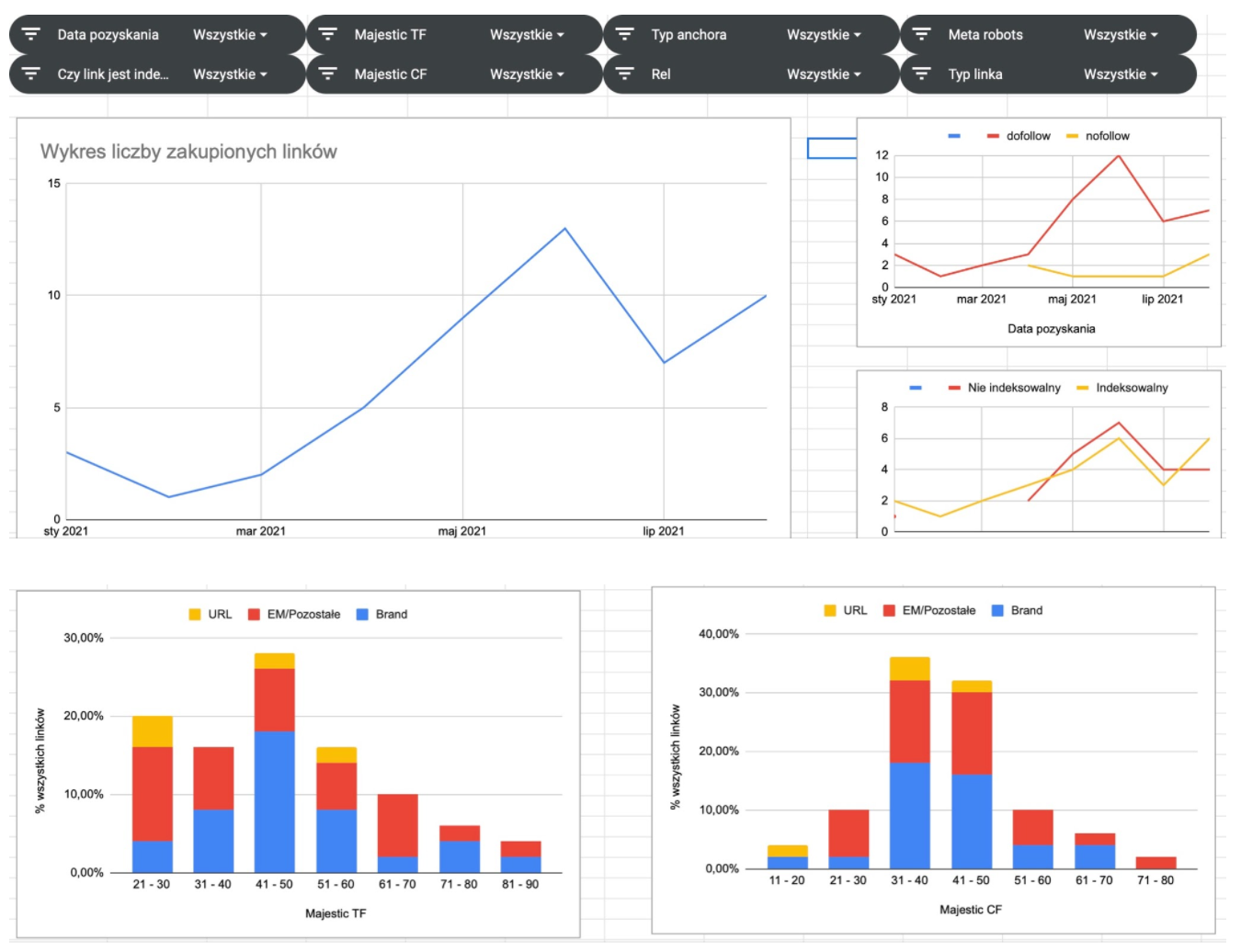
Prosta analiza zakupionych linków
Na podstawie tak pobranych danych możemy przygotować kilka prostych analiz związanych z naszą kampanią link buildingową. Przykładowo możemy opracować tabele, zawierające informacje o:
- liczbie pozyskanych linków, zgrupowanych po adresie URL, do którego prowadzi link,
- liczbie linków na określonym anchorze (w uproszczonym modelu ograniczenie do podziału: linki URL, zawierające brand, pozostałe jako EM – zakładając, że kontrolujemy anchory linków kampanii, anchory powinny być zawsze określone poprawnie),
- porównaniu liczby linków dofollow i nofollow ogółem oraz w podziale dla każdego adresu URL,
- statystykach domen agregujących informacje, np. po Majestic TF
oraz wykresy:
- liczby pozyskanych linków w danych miesiącach,
- liczby pozyskanych linków dla każdego z typu anchorów w danych miesiącach.
Czy funkcja IMPORTXML zadziała zawsze?
Niestety, powyższa metoda nie zawsze działa. Funkcja IMPORTXML zadziała wyłącznie wtedy, kiedy wszystkie dane, które pobieramy ze strony są wysyłane jako HTML. W sytuacji, gdy tagi lub treści doczytywane są np. przez kod JS, nie pobierzemy właściwych danych. Z pomocą w takiej sytuacji przychodzą aplikacje typu Screaming Frog, umożliwiające przed pobraniem danych ze strony jej wyrenderowanie. Wybierając właściwą opcję renderowania w SF, możemy wczytać stronę oraz wykonać kod JS, który się na niej znajduje.
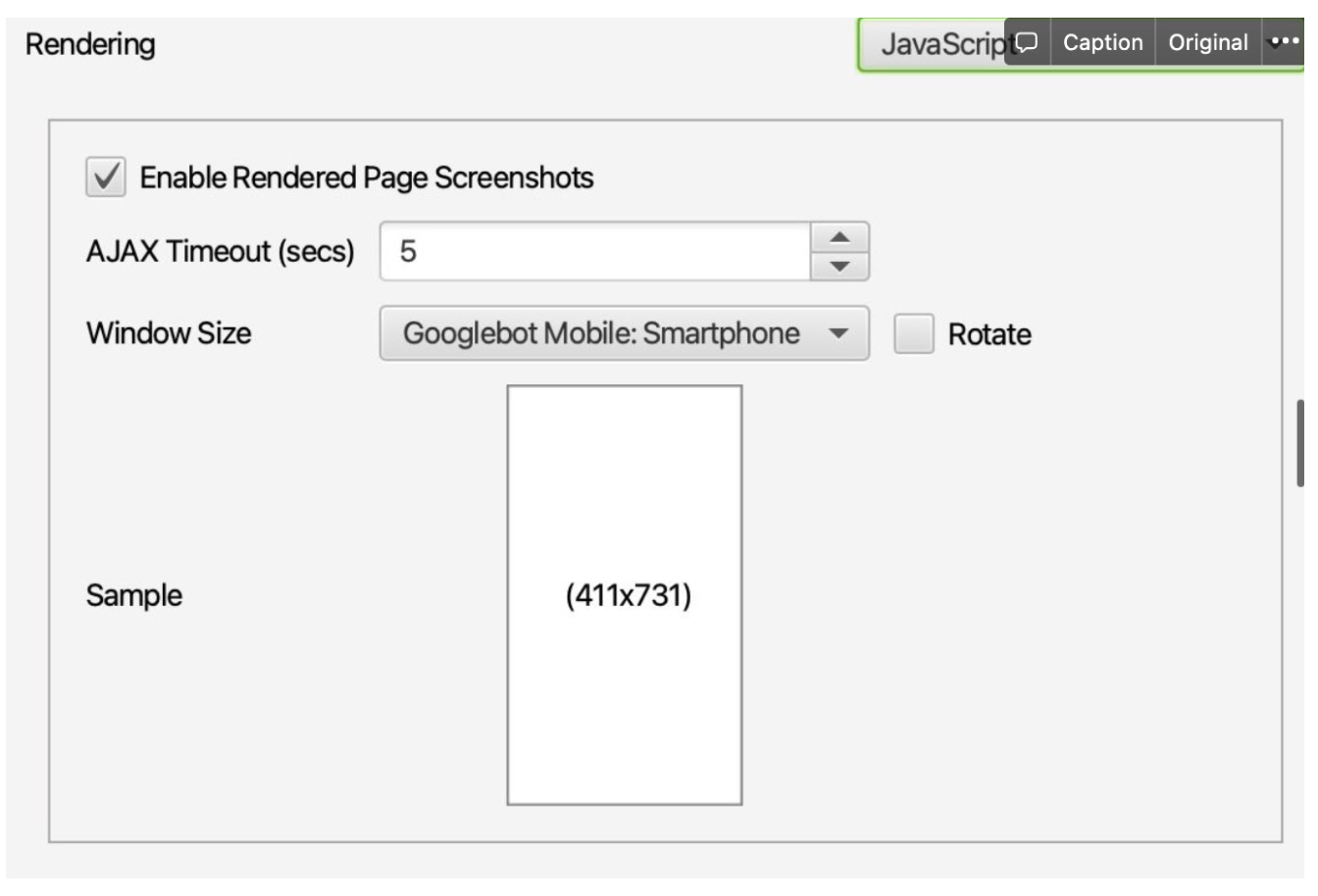
Następnie korzystając z funkcji Custom Extraction ustawionej tak jak na grafice poniżej
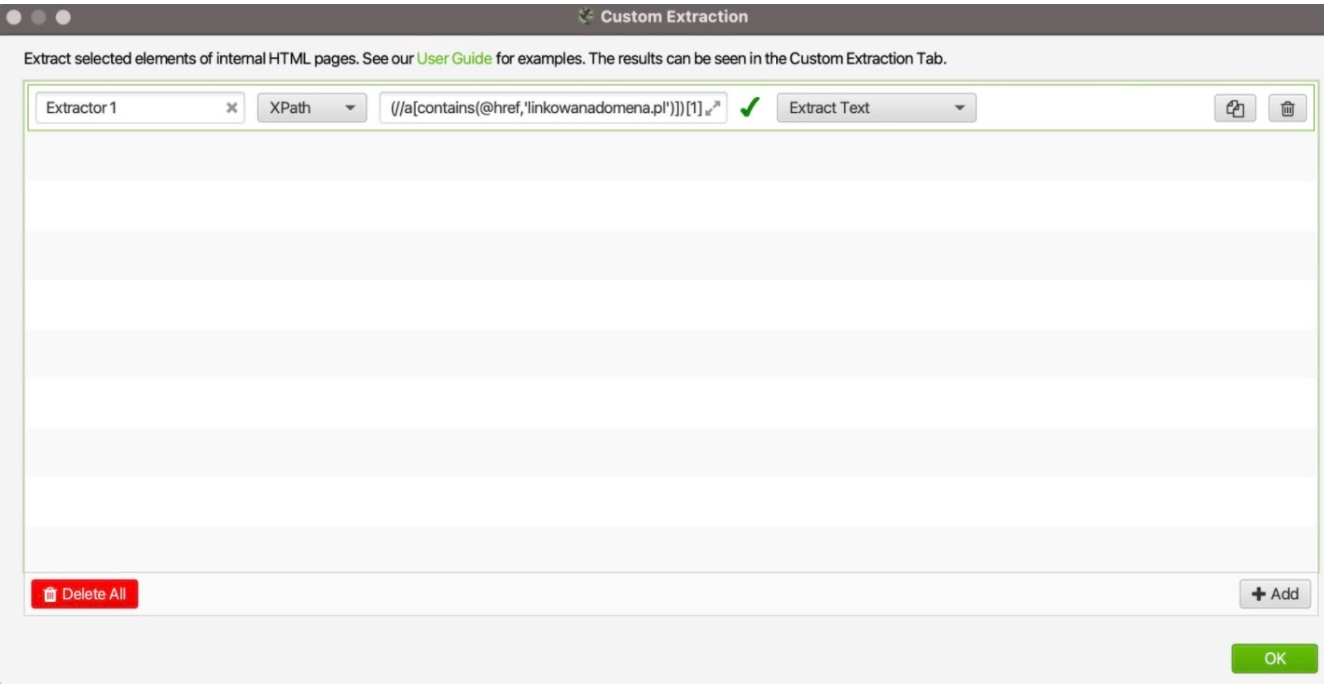
i tych samych reguł XPath można uzyskać ten sam efekt, co w Google Spreadsheets po prostu skanując przygotowaną przez nas listę stron z linkami do naszego serwisu.
Podsumowanie
Niestety całkowita automatyzacja raportów link buildingowych jest trudna do zrealizowania. Jednak, dzięki przygotowaniu szablonu, nawet bez zaawansowanych narzędzi możemy kontrolować pozyskane przez nas linki, stale monitorować ich obecność w sieci oraz uprościć sobie pracę. Szablon umożliwia nam również utworzenie samo aktualizującej się minianalizy wszystkich pozyskanych linków i weryfikację przebiegu ich pozyskiwania.
Pod adresem URL:
znajdziesz opracowany przeze mnie szablon w którym wykorzystuje powyższe reguły oraz funkcje. We wpisie znajdziesz również opis zmian, które należy wykonać aby zaadaptować go do swoich potrzeb.
Autor artykułu:

Piotr Smargol – lubi nowe wyzwania i nie boi się zmian. Pracę w branży SEO zaczął w 2018 roku, a pół roku później trafił do Vestigio, gdzie dziś zajmuje się kluczowymi projektami jako Senior SEO Specialist. Prywatnie miłośnik aktywnego spędzania wolnego czasu, w pracy — z lenistwa automatyzuje, co może. Specjalizuje się w technicznym SEO i analizie danych.
- Kontynuuj działania z funkcją Ostatnia Aktywność! - April 4, 2023
- Budowa wizerunku eksperta z wykorzystaniem zasad SEO - March 13, 2023
- Linkowanie wewnętrzne – jak robić to mądrze? - March 9, 2023