






Zduplikowana treść składa się z co najmniej dwóch wystąpień tej samej treści w internecie. Może być zarówno celowym działaniem, jak i “wypadkiem” przy pracy podczas tworzenia zawartości witryny. Walka z duplikacją treści jest priorytetem Google już od ponad dekady, czyli od 2011 roku, kiedy to wprowadzony został algorytm Panda. Algorytm ten ma za zadanie dbałość o unikalność treści w internecie i zapobieganie przesycania treści frazami kluczowymi.

Zduplikowany content może przybierać różne formy, ale przede wszystkim dzieli się na duplikację wewnętrzną i zewnętrzną.
Duplikacja zewnętrzna
Zewnętrzna duplikacja czyli sytuacja gdy ta sama treść znajduje się na różnych witrynach. Do najczęstszych powodów zaliczamy:
- Korzystanie z opisów produktów od producenta – tak samo jak konkurencja.
- Nielegalne kopiowanie treści.
- Tworzenie wpisów na seriwsy społecznościowe, wykorzystując te same treści, które mamy na stronie.
- Umieszczanie cytatów w treści, ale nieoznaczanie ich w kodzie strony przy pomocy znacznika <blockquote>.
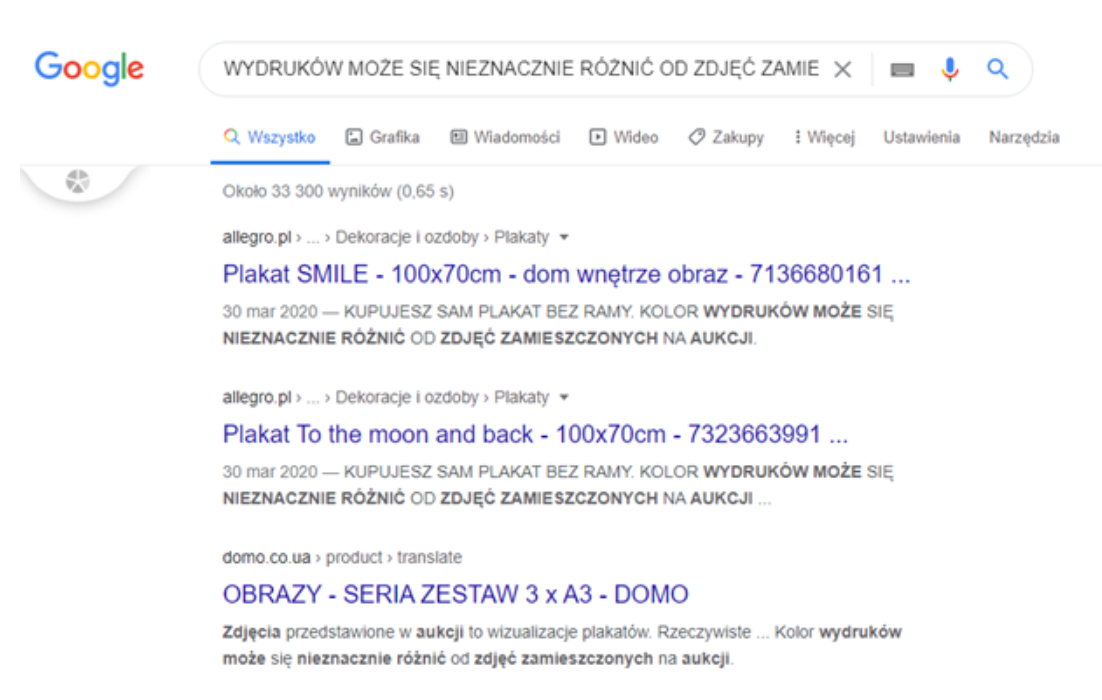
Nielegalne kopiowanie treści może być problemem, na który nie mamy żadnego wpływu. Niestety, może się zdarzyć tak, że witryna, na której została umieszczona kopia naszego tekstu osiągnie wyższą pozycję w wyszukiwarce Google. Plagiat można wykryć poprzez skorzystanie z narzędzia antyplagiatowego lub wyszukania go ręcznie przy wykorzystaniu wyszukiwarki Google. Wystarczy wkleić w okienku wyszukiwarki fragment naszego tekstu, aby zobaczyć czy występuje on także na innych stronach w internecie:
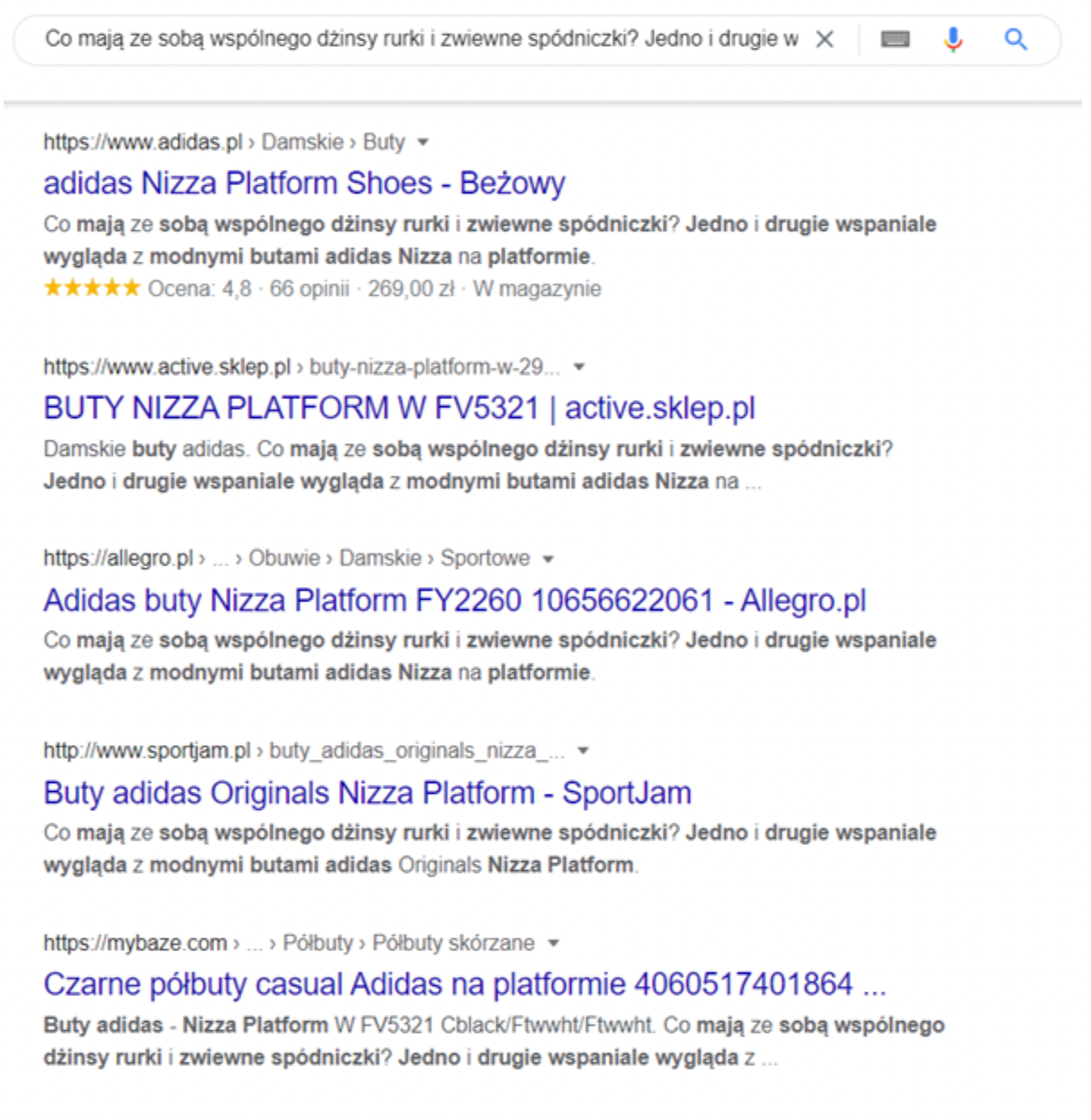
Problem jest niestety taki, że nie ma skutecznego sposobu na zabezpieczenie strony przed nieuczciwym działaniem innych internautów. Można jedynie nieco utrudnić kopiowanie treści poprzez zablokowanie możliwości zaznaczania i kopiowania tekstu lub blokowanie prawego przycisku myszy na stronie.
Duplikacja wewnętrzna
Duplikacja wewnętrzna to powtarzająca się ta sama treść w obrębie jednego serwisu. Problem mogą stanowić podobne lub takie same opisy produktów, czy też stron kategorii. Ale warto mieć świadomość, że problem duplikacji może dotyczyć także błędów technicznych, np. nieprawidłowego wdrożenia SSL, które jest przyczyną powstawania różnych adresów URL mających taką samą zawartość strony.
Innym przykładem wewnętrznej duplikacji jest niepotrzebne powielanie tego samego tekstu na kilku podstronach w witrynie. Na przykład, bardzo często zdarza się, że tekst opisujący firmę umieszczony jest w stopce – która jak wiadomo pojawia się na każdej podstronie serwisu. Podobna sytuacja może wystąpić z pojawianiem się zasad wysyłki lub gwarancji na każdej stronie produktu. Takie bloki tekstu zaleca się zastąpić linkami do odpowiednich podstron. Często zdarza się też, że opisy produktów dostępne są na stronie kategorii, w której te produkty się znajdują.
Kilka możliwych przyczyn duplikacji
Poniżej kilka przykładów najpopularniejszych przyczyn duplikacji treści. Należy jednak pamiętać o tym, że każda strona jest inna i przyczyn duplikacji należy szukać indywidualnie, poprzez skrupulatną analizę strony.
Nieprawidłowe Wdrożenie SSL
Problem występuje często po wdrożeniu w witrynie SSL, gdy nie zastosowane zostaną odpowiednie przekierowania adresów URL z HTTP na HTTPS. Pojawiają się wtedy w witrynie zduplikowane podstrony, posiadające dwa różne adresy URL. Rozwiązanie jest proste – wystarczy stworzyć odpowiednie przekierowania (najlepiej globalnie) wszystkich adresów HTTP na HTTPS.
Powielone opisy produktów
Jest to najczęściej występująca przyczyna duplikacji, zwłaszcza gdy produktów w sklepie internetowym jest bardzo dużo. Pierwszym, możliwym rozwiązaniem które przychodzi na myśl jest przeredagowanie treści tak, aby opisy nie były do siebie podobne. Ale w przypadku dużych stron e-commerce, na których znajdują się tysiące produktów, sprawa staje się nieco bardziej skomplikowana. Warto na stronach produktowych wprowadzić moduł dodawania opinii ponieważ recenzje od użytkowników z pewnością nieco zróżnicują zawartość podstrony produktu. Można także skorzystać, w niektórych przypadkach, z tagów kanonicznych. Jeżeli chcemy, aby jeden konkretny produkt (z kilku innych zawierających tą samą treść) był indeksowany i uznawany przez robota Google za najważniejszy, to w sekcji <head> pozostałych wersji strony wklejamy specjalny element kodu HTML. Tagi fragment kodu ma na celu wskazać kanoniczny czyli ten oryginalny – najważniejszy adres URL. Jest to tak zwany link kanoniczny:
<link rel=”canonical” href=”https://domena.pl/xyz” />.
Warto jednak pamiętać, że link kanoniczny nie jest nakazem, a jedynie sugestią, z której roboty Google mogą, ale nie muszą skorzystać.
Zduplikowane meta tagi w obrębie kilku podstron witryny
Problem duplikacji może wystąpić także wtedy, gdy nasza witryna posiada takie same meta tagi na wielu różnych podstronach. W takim przypadku wyszukiwarka nie wie, którą podstronę pokazać w wynikach i może wybrać tą, na której nam mniej zależy lub wyświetlać je na zmianę. Niestety takie sytuacje prowadzą do wahań pozycji na daną frazę kluczową i często nawet do jej obniżenia. Rozwiązaniem jest dokładna analiza meta tagów w witrynie i ich maksymalne zróżnicowanie.
Problemy z paginacją
Wykorzystując paginację na stronie kategorii, może zdarzyć się tak, że powielona została treść strony kategorii z pierwszą stroną paginacji. Taka sytuacja przeważnie jest spowodowana automatycznym generowaniem przez CMS pierwszej strony paginacji jako kopii strony bazowej. Rozwiązaniem w tym przypadku jest usunięcie pierwszej strony stronicowania (zastąpienie jej “głównym” adresem url kategorii). Jeżeli nie jest to możliwe to należy zastosować przekierowanie 301 adresu pierwszej strony paginacji na główną stronę kategorii.
Problem z paginacją występuje także wtedy gdy opis kategorii pojawia się na każdej stronie paginacji. Rozwiązaniem jest pozostawienie opisu tylko na 1 stronie paginacji (na głównej stronie kategorii) i nie powielanie go na następnych. Jest to też korzystniejsze dla użytkownika ponieważ na kolejnych stronach paginacji nie jest on rozproszony przez opis.
Kilka wersji strony głównej lub innych podstron w serwisie
Często zdarza się też tak, że strona główna witryny pojawia się pod różnymi adresami: np. z końcówką /index.php, czy też /index.html lub w wersji z “www” i bez “www”. Podobnie może być w przypadku innych podstron serwisu.W takim wypadku należy wyeliminować występowanie takich duplikatów w obrębie serwisu i wprowadzić przekierowanie 301 z błędnych na poprawne adresy URL.
Może być też tak, że CMS generuje adresy produktów w zależności od kategorii w jakiej się znajdują (np. gdy ten sam produkt znajduje się w kilku kategoriach, oznacza to, że jest dostępny pod różnymi adresami). Tutaj zaleca się stworzenie indywidualnych adresów URL dla każdego produktu, bez uwzględniania w takim adresie nazwy kategorii.
Wersja deweloperska została zaindeksowana przez Google.
Może zdarzyć się też tak, że Google zaindeksowało wersję „roboczą” strony. W takim przypadku należy jak najszybciej stworzyć przekierowania 301 z wersji deweloperskiej na wersję finalną witryny. Jeśli jednak wersja deweloperska jest nadal używana można zablokować ją w robots.txt
Jak wykryć duplikację treści?
Istnieją narzędzia, które umożliwiają wykrywanie duplikatów treści. Do najpopularniejszych zaliczamy:
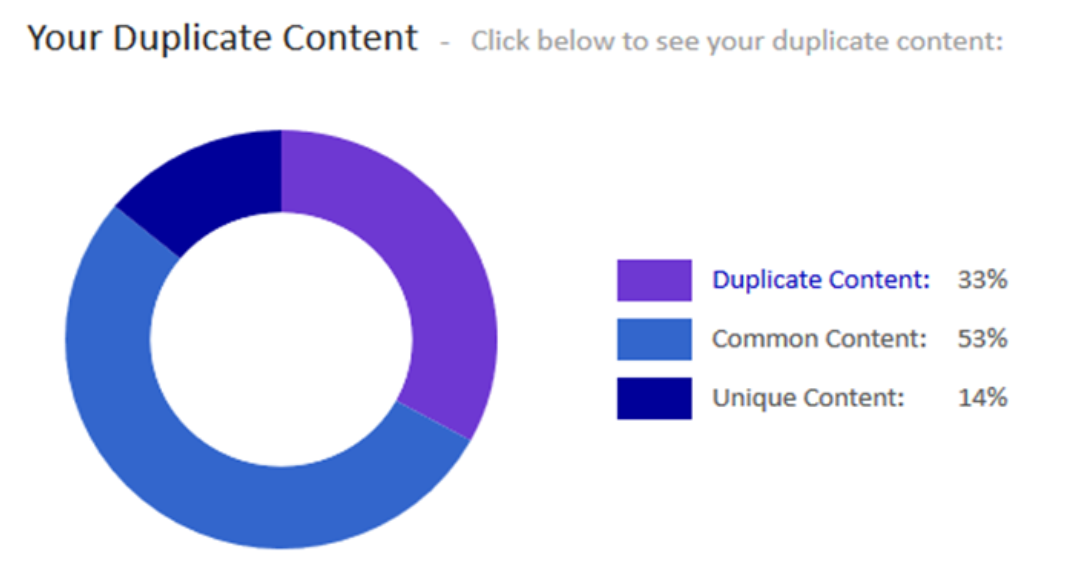
Siteliner – narzędzie, z którego możemy skorzystać za darmo, ale taka wersja ma ograniczenia co do ilości adresów, które skanuje. Analiza narzędziem pokazuje jaki procent podstron w serwisie to treści zduplikowane, a jaka część to treści w pełni unikalne. Siteliner porównuje także ile słów z danej podstrony pokrywa się z tekstami z innych podstron.
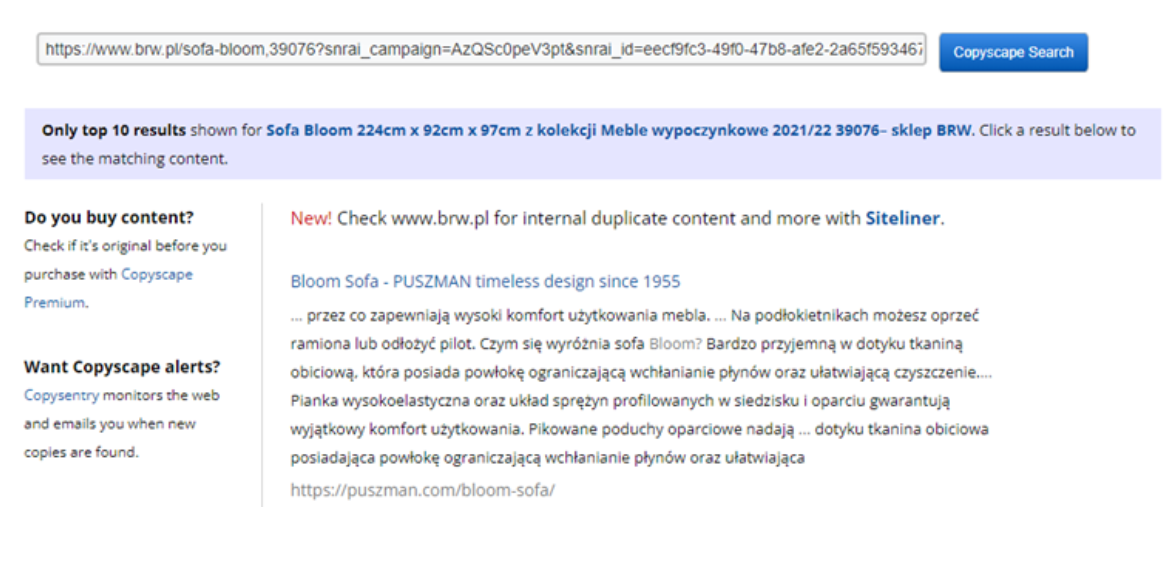
Copyscape – narzędzie, które analizuje zewnętrzne duplikaty treści. Copyscape znajduje linki do zduplikowanych stron oraz zaznacza skopiowane treści. Dostępne jest w wersji darmowej i płatnej.
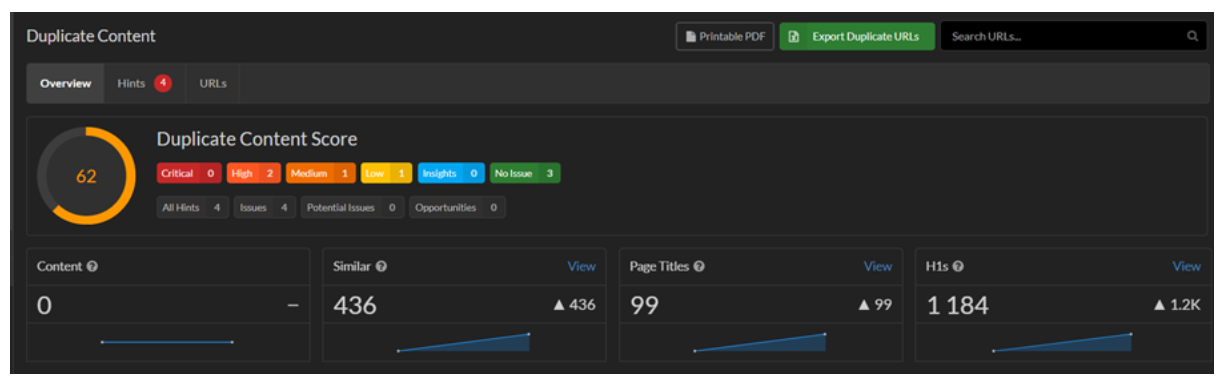
Sitebulb – jest to płatny crawler, który potrafi wskazać powielone podstrony, meta tagi czy nagłówki w witrynie.
Wyszukiwarka Google – warto wspomnieć także o tym (nieco mozolnym) sposobie. W wyszukiwarce Google także możemy szukać zewnętrznych zduplikowanych treści. Warto korzystać z tego sposobu gdy mamy do przeanalizowania jedną lub dwie podstrony (nie całą witrynę). Wystarczy krótki fragment tekstu wkleić do Google i zobaczyć wyniki.
Podsumowanie
Zduplikowana na małą skalę treść nie zawsze musi się skończyć karą ze strony Google, ale utrzymujący się, bardzo duży problem z duplikacją może spowodować problemy np. z indeksowaniem witryny lub wahaniami w rankingach SERP.
Co więcej, powtarzające się w internecie treści nie są wartościowe dla użytkownika. Nawet jeżeli strona nie zostanie ukarana przez Google, to użytkownicy nie będą chętnie czytać tych samych treści, z którymi spotkali się wcześniej, co automatycznie zmniejszy wskaźnik ich zaangażowania.
- Kontynuuj działania z funkcją Ostatnia Aktywność! - April 4, 2023
- Budowa wizerunku eksperta z wykorzystaniem zasad SEO - March 13, 2023
- Linkowanie wewnętrzne – jak robić to mądrze? - March 9, 2023