






SEO to dziedzina, w której ważna jest obserwacja bieżących zmian w ekosystemie Google. Jednak czasem warto spróbować wyprzedzić bieg wydarzeń i pomyśleć o działaniach, które na dziś nie przyniosą konkretnej wartości, ale mogą zaowocować za jakiś czas. Jakie więc trendy warto obserwować licząc na korzyści dla SEO w przyszłości?
MREIDs
MREIDs to skrót od umownej nazwy Machine-Readable Entity IDs. Są to numery ID nadawane przez Google… wszystkiemu. Każde zjawisko, rzecz i osoba poznane przez algorytm posiada swoje własne cyfrowo-literowe oznaczenie, które z łatwością można sprawdzić. MREIDs nie są kwestią z przyszłości i Google powszechnie używa ich już teraz.
Dlaczego to takie ważne? Otóż fakt, że Google kategoryzuje zagadnienia i jednostki wiedzy w ten sposób przede wszystkim pokazuje, jak daleko odeszliśmy od pierwotnego sposobu kategoryzacji wiedzy według keywordów. Google nadaje ID kompletnym jednostkom wiedzy i analizuje je całościowo, łącznie z relacjami między poszczególnymi jednostkami.
MREID nadawane jest wszystkiemu, co może mieć znaczenie dla użytkownika – własny MREID posiadają większe firmy, przedmioty, zjawiska, osoby, a nawet wydarzenia historyczne czy jednostki chorobowe.
Więcej o tym, jak sprawdzić MREID interesującego nas tematu, a także o tym jak skojarzyć swoją stronę z danym zagadnieniem pisałem w artykule o MREID w Google.
Entity-Oriented Search
Wiedza o istnieniu MREIDs jest wstępem do zrozumienia, jak wyszukiwanie informacji w internecie wyglądać będzie w niedalekiej przyszłości (a w pewnym sensie – jak wygląda już teraz).
Idea Entity-Oriented Search jest naturalnym następstwem ewolucji w podejściu Google do gromadzenia, klasyfikowania i prezentowania informacji. Od prostego kolekcjonowania treści bazującego na keywordach, poprzez łączenie keywordów w klastry powiązane tematycznie, aż do tworzenia pełnych jednostek wiedzy, czyli Entities.
Z biegiem lat Google przestaje serwować nam pojedyncze wyniki wyszukiwania, a raczej zmierza do prezentowania kompleksowej wiedzy na temat zagadnienia. Dopiero rozwój machine learning pozwolił gigantowi zrobić to precyzyjnie, opierając się jedynie na prostym zapytaniu w postaci słowa kluczowego.
Współcześnie Google bazuje na szerokiej kolekcji danych, będących mieszanką ustrukturyzowanych danych pochodzących z uporządkowanych źródeł jak i luźnych danych z milionów stron internetowych.
Cały wysiłek Google w tym obszarze skierowany jest teraz na sklasyfikowaniu i zmapowaniu tego drugiego rodzaju danych z tym pierwszym. Proces ten jest głównym celem Google i wiele z zawirowań i update’ów w SERPie jest jego efektem ubocznym. Mówiąc inaczej – Google stara się dopracować “rozumienie” danych, bo dopiero w 100% rozumiejąc dane, będzie mógł w 100% poprawnie serwować je użytkownikom wtedy, kiedy tego potrzebują.
Zmapowanie i zrozumienie koncepcji, znaczeń i kontekstów jest więc kluczowe by prezentować wiedzę, a nie tylko – jak do tej pory – prezentować listę dokumentów HTML, które mogą tę wiedzę zawierać. Już teraz więc działania specjalistów SEO powinny prowadzić do tego, by nasze strony internetowy stały się częścią tej wiedzy. A to osiągnąć można tylko przez szereg żmudnych działań takich jak strukturyzowanie danych, zdobywanie autorytetu, wprowadzanie elementów semantycznego SEO i wiele innych.
W temacie polecam darmową książkę Krisztiana Baloga z Uniwersytetu w Stavanger: Entity-Oriented Search.
Satysfakcja mierzona biometrycznie
O tym jak ważne w SEO jest User Satisfaction nie trzeba już chyba nikogo przekonywać. Oprócz wielu innych sygnałów, może o tym świadczyć chociażby patent uzyskany kilka lat temu przez giganta z Mountain View.
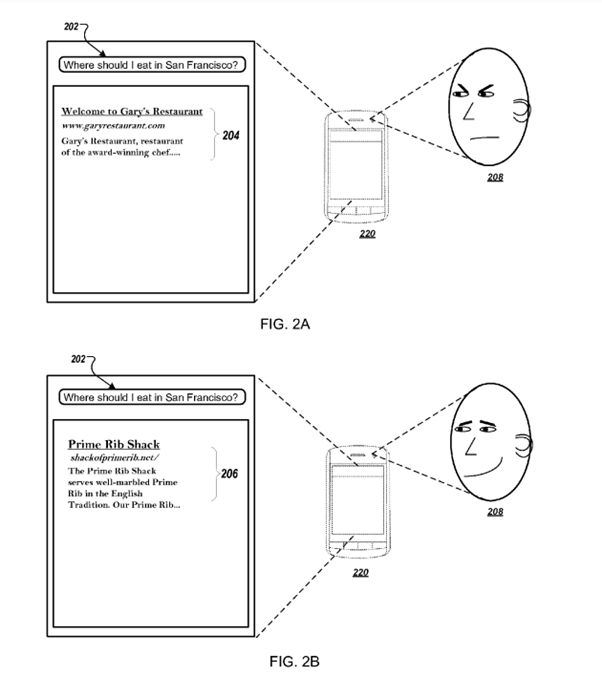
Polega on na modyfikowaniu rankingu w oparciu o fizyczną reakcję użytkownika na wyniki wyszukiwania. Bierze pod uwagę między innymi:
- zmianę temperatury ciała
- rozszerzanie źrenic
- drganie oczu
- rumieńce na twarzy
- zmiana tempa mrugania oczami
- zmiana rytmu serca.
Dane te miałyby być dostarczane oczywiście poprzez naszego smartfona czy smartwatcha i analizowane anonimowo za pomocą machine learning.
Oczywiście dziesiątki tego typu patentów nigdy nie zostało przez Google wdrożonych. Nawet jeśli powyższy pomysł podzieli ich los, to jednak pokazuje to w którą stronę zmierza Google i jak dużą wagę przykłada do satysfakcji użytkownika.
Personal Knowledge Graphs (PKG)
Knowledge Graphy na dobre zadomowiły się w naszych wynikach wyszukiwania. Warto zwrócić jednak uwagę na kolejne patenty, jakie w tym temacie złożyło Google.
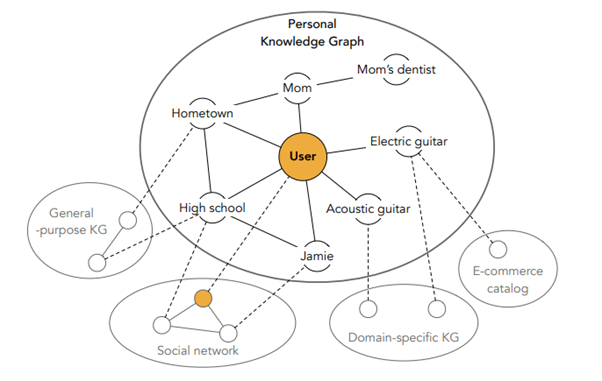
Początkowo Knowledge Graph miał za zadanie gromadzić w jednym miejscu dane na temat istotnego zagadnienia opartego na wpisanym w wyszukiwarkę keywordzie. Choć wciąż wydaje się to być czymś nowym i nieco inwazyjnym, tego typu boxy z informacjami są z nami już od 2012 roku.
Jednak już w 2013 Google złożyło patent modyfikujący nieco przeznaczenie Knowledge Graphów, dopuszczając tam personalizację treści na podstawie między innymi historii wyszukiwania czy otrzymanych e-maili. Patent ten, ostatecznie przyznany w 2019 roku, zyskał swoje rozwinięcie w postaci dokumentu przygotowanego na International Conference on Theory of Information Retrieval 2019 przez Krisztiana Baloga i Toma Kentera.
W tej właśnie pracy nowy rodzaj wyświetlania danych nazwano Personal Knowledge Graph (PKG), wskazując kierunek jego dalszego rozwoju. Zasadniczą zmianą jest podejście do tego, co w Knowledge Graphie może się znaleźć. Pierwotnie, istotną zasadą było, iż informacje te muszą mieć znaczenie globalne. PKG ma być nie tylko spersonalizowany, ale wyświetlać Entities ważne dla użytkownika, włączając te, które ze względu np. na swoją skalę nie miały szans znaleźć się w tradycyjnym Knowledge Graphie.
Specjalistom SEO otworzy to nowe pole do działania i nowy kanał dotarcia do użytkownika. I z pewnością zapewni wiele godzin rozgryzania sposobów dotarcia i jak najczęstszego wyświetlania się w Personal Knowledge Graphach.
Linkless link building
Kiedy Google stworzyło Page Rank, oparcie się w głównej mierze na linkach było naturalną koleją rzeczy – linki to coś, co stworzyło młody jeszcze wtedy twór, jakim był internet. Jednak w drugiej dekadzie XXI wieku linki jako takie nie wskazują wartościowych stron, a w większości wskazują jedynie, że dana strona jest pozycjonowana.
“Naturalne” linkowanie funkcjonuje w nielicznych branżach, w innych odbywa się raczej tylko w social mediach, w pozostałych jest kompletną fikcją.
Czy linki działają? Oczywiście, jednak trudno byłoby spodziewać się, że ich znaczenie utrzyma się wiecznie. Google dysponuje już wystarczającą liczbą jakościowych sygnałów, dzięki którym potrafi ocenić stronę, jednak czynnik popularności i rangi nadawany poprzez linkowanie musi być zastąpiony czymś solidnym.
I tu pojawia się Linkless Link Building, coś co przez wielu rodzimych specjalistów jest niesłusznie wykpiwane jako mit. Jeden z patentów Google z 2014 roku mówi o tzw. “implied links”, czyli domniemanych linkach.
Brytyjski specjalista Simon Penson przybliża nam ów patent, sugerując, że jeśli po wpisaniu nazwy brandu użytkownicy klikają w SERPie określony wynik, to pomiędzy nazwą a adresem URL powstaje w oczach Google relacja. Następnie wszystkie wspomnienia nazwy brandu w sieci – oczywiście biorąc pod uwagę kontekst – stają się czynnikiem rankingowym działającym na podobnej zasadzie co linki.
Również Gary Illyes z Google podczas jednego z wystąpień w Brighton mówił o tym, że ważne są nie tylko linki, ale również “”mówienie” o marce. Z kolei Bing już w 2016 otwarcie oświadczył, że potrafi przyporządkować brand mentions do odpowiedniej strony i traktuje je na równi z linkami.
Spodziewać się można, iż ten trend będzie się dalej pogłębiał, bo tego wymagają realia. Tak czy siak, przepis na sukces w budowaniu linków bez linków i tak nie jest rewolucyjny i nie różni się wiele od innych podobnych technik: polega m.in. na budowaniu brandu, autorytetu, byciu aktywnym w swojej niszy.
Semantyka w technicznym SEO
Jednym z problemów szybkiego rozwoju branży SEO są nieścisłości w nazewnictwie. Często przytaczanym pojęciem jest semantyczne SEO. Rozumiemy przez to zwykle w dużym skrócie tworzenie treści obejmujące pełne zakresy tematyczne, a nie pojedyncze słowa kluczowe.
Semantyka jako nauka zajmuje się jednak przede wszystkim relacją między znakami, symbolami i tekstami a ich znaczeniem. I na takie znaczenie semantyki w SEO warto również spojrzeć – jako relacji między technicznymi elementami naszej strony a ich znaczeniem.
Najprostszym przykładem semantyki w SEO jest oznaczanie ważnych nagłówków atrybutami H1, H2, itd. Prostym symbolem informujemy robota Google, iż oznaczony tekst jest wyróżniony z reszty tekstu jako tytuł strony, części lub rozdziału.
Innym rodzajem znaczeniowych technikaliów, których znaczenie może być kluczowe dla zrozumienia naszej treści przez wyszukiwarkę są oczywiście dane strukturalne. O ich zaletach nie trzeba już współcześnie chyba nikogo przekonywać.
Jednak nie wszyscy zdają sobie sprawę jak duży potencjał semantyczny tkwi już w samym języku HTML. Wraz z jego 5. wersją zakres komend, które między wierszami mówią maszynom, czym jest oznaczony tekst, znacznie wzrósł.
W HTML5 możemy nadać znaczenie pojedynczym elementom tekstu; np. oznaczyć definicję jakiegoś pojęcia (<dfn>), oznaczyć czas lub datę (<time>), objaśnić skrót (<abbr>) czy oznaczyć adres (<address>). Możemy też poinformować roboty o tym, jak zbudowana jest nasza strona, pokazując gdzie znajduje się nawigacja, która część to stopka, a która zawiera główną treść.
W tym artykule napisałem dużo o semantyce w HTML5 i myśląc o przyszłości w SEO warto się z tą wiedzą zapoznać. Wdrożenie jej w życie teraz nie przyniesie jeszcze bezpośrednich korzyści, ale w świetle wzrostu voice search, asystentów głosowych i urządzeń dla osób z niepełnosprawnościami w przyszłości może się to okazać bardzo korzystne.
Computer accessibility
Computer accessibility może być w przyszłości znaczącym trendem. Idea ta polega na tworzeniu stron i aplikacji z myślą o osobach zagrożonych wykluczeniem cyfrowym, czyli np. osobach z niepełnosprawnościami.
Strony takie powinny być tworzone w zgodzie z wytycznymi takimi jak standardy ADA czy WCAG. Już teraz w Polsce strony podmiotów publicznych i dostawców usług telefonicznych muszą według prawa te standardy spełniać; podobnie jest w UE i USA.
ONZ idzie o krok dalej i w konwencji Convention on the Rights of Persons with Disabilities zobowiązuje do dostępności wszystkie serwisy społeczeństwa informacyjnego i technologie komunikacyjne.
Choć obecnie przedstawiciele Google i Binga otwarcie przyznają, że dostępność nie jest czynnikiem rankingowym, to niewykluczone, że zgodnie z obecnymi trendami społecznymi może się to w przyszłości zmienić. Szczególnie zważywszy na fakt, że większość tych wytycznych pokrywa się z dobrymi praktykami SEO, takimi jak przejrzysty układ strony, podpisywanie grafik, opisowe anchory, transkrypcje wideo itd.
Actions on Google i Schema.org Actions
Projekt Schema.org powstał po to, by porządkować informacje, Asystent Google powstał po to, by te informacje wygodnie serwować. Jednak wraz z rozwojem technologii prezentowanie informacji nie wystarcza – użytkownicy będą z nimi wchodzić w interakcje i wykonywać z nimi różnorakie działania.
Wyobraźmy sobie stronę lokalnej pizzeri. Już dziś możemy ją “oschemować” tak, by pokazać maszynom możliwą interakcję ze stroną. Możemy również stworzyć aplikację Actions on Google, którą później obsłuży Asystent Google. Akcją będzie w tym wypadku oczywiście zamówienie pizzy.
Tworzenie aplikacji tego typu może również posłużyć do obsługi internetu rzeczy, dzięki czemu będziemy mogli poprosić Asystenta Google o zlecenie ekspresowi do kawy przygotowanie podwójnego sojowego latte. Nas jednak interesują akcje dzięki którym wejdziemy w interakcję ze stroną internetową, a te w branży e-commerce czy usługowej mogą stać się bardzo popularne.
Co ciekawe, wielu z nas stworzyło na swoich stronach akcje dla Asystenta Google nawet o tym nie wiedząc. Tworzone są one bowiem automatycznie przy wdrożeniu niektórych typów danych strukturalnych, takich jak FAQ, HowTo, Recipe itp., lub np. przy udostępnianiu do indeksacji podcastów.
To, że w przyszłości tworzenie tego typu akcji będzie w każdym niemal biznesie bardzo ważne jest właściwie pewne. Już dziś Actions on Google wdrożyły firmy takie jak Uber, Spotify, Netflix, PZU, Frisco, Media Markt, Ceneo, CCC i wiele innych.
Co jeszcze może przynieść przyszłość?
To oczywiście nie wszystkie trendy, na jakie warto zwrócić uwagę w przyszłości. Pozostaje mnóstwo zagadnień, których zastosowanie stoi pod dużym znakiem zapytania, lub które są zbyt oczywiste by o nich mówić.
Dane strukturalne z pewnością będą wciąż zyskiwały na znaczeniu i coraz więcej ich typów będzie miało bezpośredni wpływ na wygląd i funkcjonalność witryny w SERPie.
Śledzenie patentów Google będzie zawsze dobrym pomysłem, bo nawet jeśli ostatecznie trafiają one do szuflady, to jednak pokazują co zaprząta głowy specjalistów z Mountain View.
Machine learning już teraz stanowi podwalinę rozwoju ekosystemu Google. Być może jest to dobry moment na dokształcenie się w tym kierunku. Nawet jeśli nie znajdziemy dla tej wiedzy bezpośredniego zastosowania w działaniach SEO, to przynajmniej lepiej zrozumiemy co dzieje się “pod maską” wyszukiwarki.
Portale branżowe coraz częściej przebąkują coś o Augmented Reality w SEO, ale na chwilę obecną jest to coś kompletnie oderwanego od rzeczywistości. Niewykluczone jednak, że za jakiś czas pojawi się na rynku szerokodostępne urządzenie, które ten stan rzeczy zmieni.
Wielką zagadką jest dalszy rozwój visual contentu. O ile o rozwój wideo i YouTube możemy być spokojni, o tyle inne rodzaje treści wizualnych takie jak AMP Stories mogą niedługo zakończyć swój żywot, lub rozkwitnąć w pełni – tego nie wie chyba nikt.
Projekt AMP i jego przyszłość również jest wielką zagadką. Krytykowany, niechętnie przyjmowany, robi krok naprzód i dwa wstecz. Mimo to Google nie rezygnuje z jego promowania i myślę, że właśnie teraz ważą się jego losy. Może równie dobrze zniknąć w odmętach historii, co stać się standardem.
A co z Voice Search? Być może przesyt branżowych artykułów na ten temat przyprawił niektórych o zniecierpliwienie, ale spokojnie. Rewolucja Voice Search nie została odwołana, nikt po prostu nie twierdził, że będzie to rewolucja, która wydarzy się jutro.
Dokąd więc zmierza SEO?
Wszystko wskazuje na to, że za kilka-kilkanaście lat dojdzie w całym inbound marketingu do rewolucji.
Wyszukiwarki internetowe zyskały popularność, bo nie wciskały nachalnie treści użytkownikom. To użytkownicy przychodzili do wyszukiwarki po informacje. Myślę, że jesteśmy świadkami ewolucji tego modelu – coraz częściej informacje serwowane są użytkownikowi, zanim ten w ogóle wyeksponuje wolę ich poznania.
Stało się to możliwe dzięki zaawansowanym, uczącym się algorytmom i to zjawisko będzie przybierać na sile. Już dziś zapowiedzią i małą namiastką tego jest chociażby Google Discover.
Wyszukiwarki chcą więc zaoferować użytkownikowi kompletne doświadczenie – nie tylko odpowiadać na jego pytania kompletnym przeglądem wiedzy i danych, ale również przewidzieć jego zachowanie i wyjść mu naprzeciw. Specjalista SEO musi więc przestać myśleć o searchu jak o prostej czynności wyszukiwania i traktować customer journey jako całość.
Należy rozważyć, jak za pomocą podanych wyżej pomysłów będziemy w przyszłości wstrzelać się w ten proces i na ile będziemy potrafili skonwertować użytkowników podczas jego trwania lub regulować jego kierunek.
Powyższe trendy warto obserwować, nakreślają jakiś kierunek rozwoju tej branży. Ale na konkretne prognozy i rozwiązania przyjdzie jeszcze czas. SEO to bez wątpienia dziedzina w której trzeba śledzić tendencje i nowinki technologicznie, ale jednocześnie w codziennej pracy stosować sprawdzone i działające na dzień dzisiejszy metody.
Autor wpisu:

Piotr Samojło – pasjonat technicznego SEO, działa jako freelancer pod marką Audytorium.xyz. Autor bloga Audytorium SEO.
- Kontynuuj działania z funkcją Ostatnia Aktywność! - April 4, 2023
- Budowa wizerunku eksperta z wykorzystaniem zasad SEO - March 13, 2023
- Linkowanie wewnętrzne – jak robić to mądrze? - March 9, 2023