





TLDR; Majestic hat eine viel tiefere Link-Analyse erhalten. Diese Analyse verbessert die Klarheit der frischen Backlink-Daten, indem sie uns erlaubt, einige Zeilen von Link-Daten zu entfernen, die wenig Wert bieten.
Heute haben wir einen großen Schritt nach vorne gemacht, um die Analyse auf Linkebene voranzutreiben. Ab sofort zeigen die Tabs Backlinks und Linkkontext im Site Explorer für Fresh Index die Ergebnisse der Erkennung doppelter Links an!
In diesem Beitrag erklären wir:
- Warum die Erkennung doppelter Links Ihnen einen besseren Einblick in die Qualität von Links gibt
- Warum die Erkennung doppelter Links eine enorme Verbesserung gegenüber der siteweiten Analyse darstellt
- Wie wir die Erkennung doppelter Links nutzen werden, um die Menge an nützlichen Daten in unserer Datenbank zu erhöhen
Sind Sie bereit? Dann fangen wir an!
Wie genau funktioniert die Erkennung von doppelten Links?
Diese Version markiert die nächste Stufe unseres Backlinks Fidelity-Projekts 2021, das darauf abzielt, mehr Klarheit zu schaffen und unseren Index auf die Bereitstellung von “High Fidelity”-Backlinkdaten zu fokussieren.
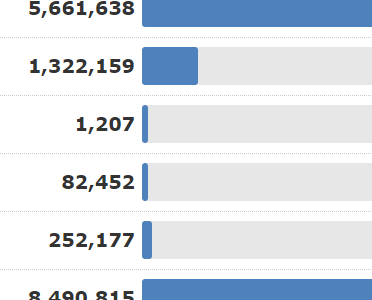
Wir haben den Backlink-Daten aus dem Fresh Index im Site Explorer Labels hinzugefügt, die zeigen, ob ein Link anderen auf derselben Website ähnlich ist.
Die Erkennung doppelter Links funktioniert auf Ebene der Quelldomäne. Der dahinter stehende Algorithmus ist komplex, lässt sich aber wie folgt zusammenfassen:
Es werden alle Backlinks von der Quelldomäne zu einer bestimmten URL auf einer anderen Domäne analysiert. Bei dieser Analyse wird den Backlinkdaten ein Duplikatstatus auf Linkebene zugewiesen.
| Klassifizierung der Duplikatanalyse | Erklärung |
| Eindeutig | Entweder ein einzigartiger Backlink oder der bemerkenswerteste Link aus einer Reihe von Duplikaten auf einer Website |
| Bemerkenswertes Duplikat | Ein Link, der eine Kopie eines anderen Links von derselben Website zu sein scheint, sich aber auf einer Seite befindet, die Trust Flow und Citation Flow überträgt |
| Umleitung | Der Link wurde von einem Vermittler umgeleitet, so dass die Art des Duplikats unklar ist. |
| Klassifizierung ausstehend | Der Link-Analyseprozess dauert länger als der Aufbau des Fresh-Index, so dass es eine Reihe von Links geben kann, die noch klassifiziert werden müssen |
| Kann nicht klassifiziert werden | Die Algorithmen waren nicht in der Lage, den Link zu klassifizieren. |
| Nicht bemerkenswertes | Duplikat Dieser Link scheint derselbe zu sein wie ein höher gerankter Link auf derselben Website an einer anderen Stelle. Er hat nicht genügend “Linkjuice”, um als beachtenswert zu gelten. |
Wir haben einige Zeit damit verbracht, die Duplikat-Analyse zu optimieren und sind nun der Meinung, dass wir die Ergebnisse mit Ihnen teilen können. Die Link-Analyse scheint eindeutige und auffällige Links über verschiedene Größen von Websites hinweg effektiv zu erkennen. Die Analyse auf Link-Ebene ist so scharf, dass sie den Unterschied zwischen einem eindeutigen Link und einem bemerkenswerten doppelten Link auf ein und derselben Webseite erkennen kann!
Die vollständige Aufschlüsselung, wie viele externe eingehende Links in jeder Kategorie platziert wurden, finden Sie im Abschnitt Backlinks Breakdown der Site Explorer-Zusammenfassung für jede Domain, URL oder Subdomain-Suche.
Besser als “Sitewide”
Eine der bekanntesten Formen von doppelten Links in der Suchmaschinenoptimierung sind externe Sitewide-Links.
Viele SEOs werden den Begriff “Sitewide Link” ohne weiteres erkennen und verstehen. Doch wie so viele Herausforderungen bei der Linkanalyse wird auch die Natur eines siteweiten Links komplex, wenn er unter die Lupe genommen wird.
Die typische Definition eines Sitewide-Links ist ein Link, der überall auf einer Website erscheint, normalerweise in den Navigationselementen der Webseiten: Seitenleiste, Kopfzeile oder Fußzeile.
Manche gehen noch weiter und meinen, dass ein Sitewide-Link auf allen Seiten einer Website erscheint. Lassen Sie uns ein wenig darüber nachdenken.
Wenn eine Website zehntausend Seiten hat, von denen neuntausendneunundneunzig einen “Sitewide-Link” haben und eine Seite, auf der er fehlt, ist der Link dann immer noch “sitewide”?
Natürlich ist er das!
Wenn dieselbe Website um einige Seiten erweitert wird, so dass es statt einer Seite nun 100 Seiten ohne den Sitewide-Link gibt, ist der Link dann immer noch sitewide?
Die meisten würden wohl eher der Meinung sein, dass eine Website mit 10.099 Seiten, von denen 9.999 denselben Link haben, ein Sitewide-Link ist.
Sie sehen wahrscheinlich, worauf wir hinauswollen.
Wenn man das Konzept der Sitewide-Links unter die Lupe nimmt, dann gibt es eine implizite Schwelle. Es gibt einen Schwellenwert, ab dem man potenziell viele Links von einer Website haben kann, die irgendwohin verweisen, aber all diese Duplikate gelten nicht als standortübergreifend.
Dies wirft dann die Frage auf. Wie viele Links müssen von einer Website ausgehen, damit sie als standortübergreifend gelten können? 100? 1000? 50%? 51%? 99%?
Wir waren nicht zufrieden mit der Annahme, dass wir wüssten, was der richtige Schwellenwert für eine standortweite Erkennung sein sollte. Unsere Schlussfolgerung war: “Es kommt darauf an.” Wie oft hört man das in der SEO-Branche?
Wir sind der Meinung, dass die Erkennung von doppelten Links die siteweite Analyse übertrumpft. Unabhängig davon, ob ein doppelter Link auf zwanzig oder auf zweihundert Seiten entdeckt wird, ist es unserer Meinung nach wert, ihn als solchen zu kennzeichnen.
Anwendung der Analyse doppelter Links, um Backlink-Treue zu erreichen
Wir sehen diese Veröffentlichung als einen großen Schritt zur Erreichung unserer Ziele, die wir in unserem Beitrag vom September 2020 “Roadmap: Backlink-Treue vs. Backlink-Volatilität” und in unserem Beitrag vom Januar 2021 “Backlinks zählen und unsere Link-Index-Strategie 2021” dargelegt wurden.
Die Klassifizierung der Daten ist jedoch nur ein Schritt in unserer Mission, die höchste praktische Backlink-Treue zu erreichen. Der nächste Schritt ist ein großer. Wir möchten Ihnen bessere, besser nutzbare Daten liefern, indem wir unser Versprechen einlösen, “WENIGER Backlinks in Fresh” anzuzeigen. Wir werden dies erreichen, indem wir die Linkvielfalt und die Anzahl der verweisenden Domains beibehalten, ABER die Anzahl der doppelten Links, die wir speichern, reduzieren.
An dieser Stelle wird das Markieren von nicht bemerkenswerten Duplikaten wichtig, da nicht bemerkenswerte Duplikate Kandidaten für die Entfernung sind. Unser endgültiger Plan ist die Rauschreduzierung, bei der wir Links aus dem Fresh Index entfernen wollen, die als Duplikate erkannt werden und keinen Trust Flow und Citation Flow bestehen.
Wie man Daten über doppelte Links herunterlädt
Majestic bietet eine Reihe verschiedener Möglichkeiten, Daten zu erhalten. Wir arbeiten daran, dies zu vereinfachen, haben aber die Daten zu doppelten Links über den neuen Stil “Raw Export” verfügbar gemacht. Hier eine kurze Auffrischung, wie Sie auf alle Backlink-Daten zugreifen können, die wir für eine URL oder Site haben (Hinweis: Die Verfügbarkeit hängt von der Site und dem Plan ab).
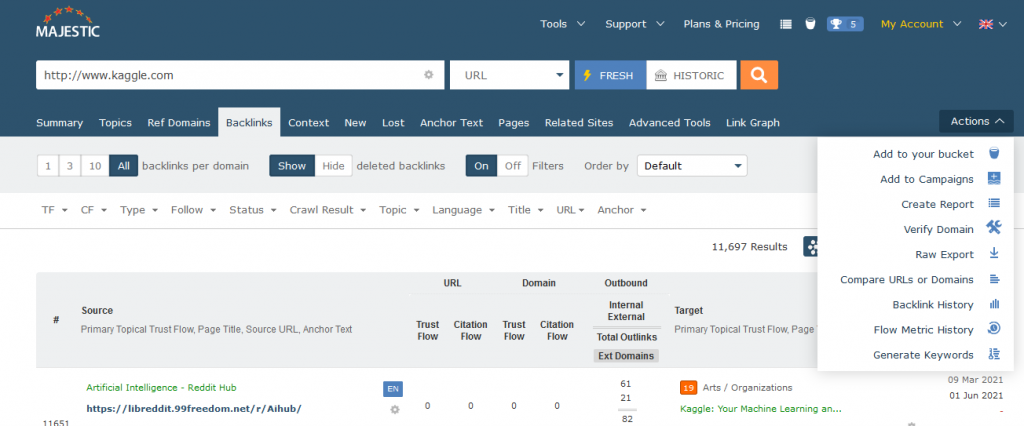
Die Funktion “Rohexport” finden Sie im Menü “Aktionen” im Site Explorer. Wir sind dabei, die Rohdatenexportfunktion zu aktualisieren. Um auf die neuen Felder zugreifen zu können, müssen Sie sicherstellen, dass Sie die neue Version von “Raw Export” verwenden, die wie die untenstehende aussieht:
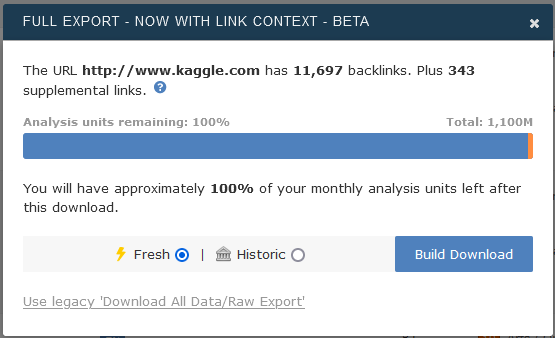
Wenn Ihr Bildschirm etwas anders aussieht, suchen Sie nach der Option “Try the new Full Export”. Nachdem Sie auf “Build Download” geklickt haben, können Sie entweder hier auf die Bestätigung des Downloads warten oder Majestic weiter verwenden und später zum Download-Bildschirm zurückkehren.
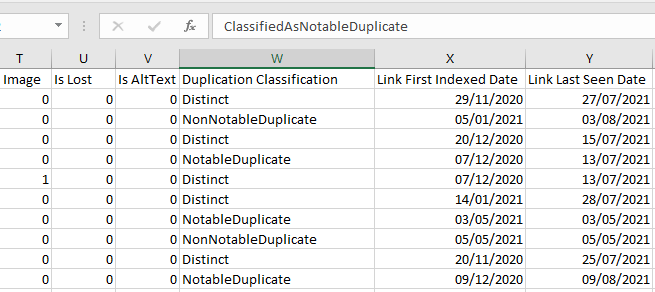
Majestic stellt die Rohexporte im komprimierten “.tar.gz”-Format zur Verfügung. Wenn Sie Windows verwenden, benötigen Sie möglicherweise ein Programm wie 7-zip, um die .csv-Datei nach dem Download zu extrahieren. Sie finden die neue Duplikat-Link-Analyse in der Spalte “Duplikat-Klassifizierung”.
Was zu beachten ist:
Wir haben versucht, die wichtigsten Punkte oben zu erwähnen. Der Vollständigkeit halber sind hier jedoch noch ein paar Details:
- Wir planen, zu gegebener Zeit Filteroptionen für die Backlink- und Linkkontextberichte für doppelte Linkarten hinzuzufügen.
- Zunächst wird die Duplikat-Klassifizierung nur über die Schnittstelle und den neuen Stil des vollständigen Exports verfügbar sein.
- Wir planen nicht, die Analyse der Link-Duplikate in naher Zukunft über die API anzubieten.
- Die Rauschunterdrückung wird auf Link-Ebene erfolgen. Es ist sehr unwahrscheinlich, dass die Anzahl der verweisenden Domains und die Flow Metric Scores davon direkt betroffen sein werden.
- Wenn wir die Anzahl der Datenzeilen in unserem Index reduzieren, haben wir die Möglichkeit, mehr Daten zu speichern. Diese wollen wir dann nutzen, um das Fenster des Fresh Index über das derzeitige Vier-Monats-Fenster hinaus zu erweitern.
- Große Mengen an Berechnungen durchzuführen ist schwierig. Die Analyse doppelter Links wird von Algorithmen mit wenig oder gar keiner menschlichen Beteiligung durchgeführt. Wir sind mit den Ergebnissen dieses Projekts sehr zufrieden. ABER bitte stellen Sie sicher, dass Sie Ihre eigenen Überprüfungen durchführen, bevor Sie sich auf heuristisch generierte Daten verlassen.
Die Analyse doppelter Links ist ab heute im Site Explorer für die Suche nach URLs, Domänen und Subdomänen im Fresh Index verfügbar. Schauen Sie sich unsere kostenlose Demo-Site für ein Beispiel an.

- Majestic Hauptsitz – Umzug - April 17, 2026
- Einführung der Erkennung von doppelten Links - September 20, 2021
- Finden Sie 404s mit Majestic - April 29, 2021