





TLDR; Far deeper link analysis has arrived in Majestic. This analysis enhances the clarity of Fresh backlink data by allowing us to remove some rows of link data that offer little value.
Today we have taken a huge step fowards in advancing link level analysis. As of now, the Backlinks tab and Link Context tab in Site Explorer for Fresh Index show the results of duplicate link detection!
In this post, we explain:
- Why duplicate link detection gives you greater insight into quality links
- Why duplicate link detection is a huge improvement on sitewide analysis
- How we are going to use duplicate link detection to increase the amount of useful data in our database
Ready? Let’s begin!
What is duplicate link detection?
This release marks the next stage in our 2021 Backlinks Fidelity project which aims to provide better clarity and focus our index on providing “High Fidelity” backlinks data.
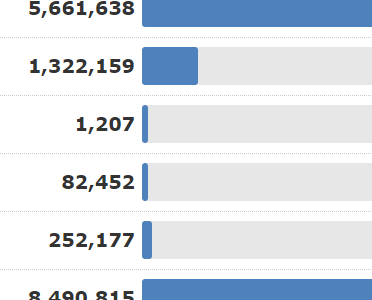
We’ve added labels to backlink data from the Fresh Index in Site Explorer which shows if a link is similar to others on the same site.
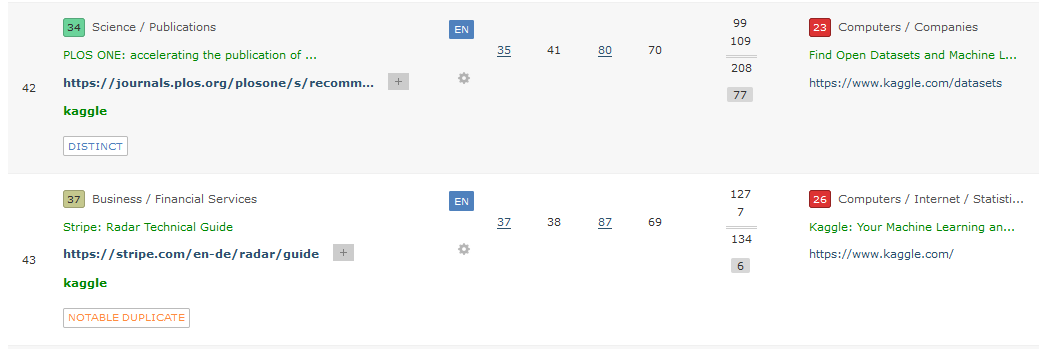
Duplicate link detection works at source domain level. The algorithm behind this is complex, but can be summarised as follows:
It analyses all the backlinks from that source domain to a given URL on an different domain. This analysis assigns a duplicate status at link level to backlink data.
| Duplicate Analysis Classification | Explanation |
| Distinct | Either, a unique backlink, or the most notable link from a set of duplicates on a site |
| Notable duplicate | A link that appears to be a copy of another link from the same site, but is on a page that transfers Trust Flow and Citation Flow |
| Redirect | The link has been redirected by an intermediary and hence the duplicate nature is uncertain |
| Pending classification | The link analysis process takes longer than the Fresh index takes to build so there may be a number of links that are yet to be classified |
| Cannot be Classified | The algorithms haven’t been able to classify the link |
| Non-notable duplicate | This link appears to be the same as a higher ranked link on the same site in a different location. It carries insufficient “link juice” to be considered notable. |
We’ve spent time tuning duplicate analysis and now feel the results are ready to share with you. The link analysis appears to spot distinct and notable links effectively over various sizes of website. The link-level analysis is so sharp it can identify the difference between a distinct link, and a notable duplicate link, on the same webpage!
The complete breakdown of how many external inbound links have been placed in each category can be found in the Backlinks Breakdown section of Site Explorer summary for any domain, URL or subdomain search.
Better than “Sitewide”
One of the most familiar forms of duplicate links in SEO are sitewide external links.
Many SEO’s will recognise and understand the term “sitewide link” without a second thought. However, like so many challenges in link analysis, the nature of a sitewide link becomes complex when subjected to scrutiny.
The typical definition of a sitewide link is one that appears all over a website, normally in the navigation elements of the webpages; sidebar, header or footer.
Some may go further and suggest that a sitewide link appears on all pages of a website. Let’s think about this a little bit.
If a site has ten thousand pages, nine thousand nine hundred and ninety nine of which have a “sitewide link” and one page that omits it, is the link still sitewide?
Of course it is!
If the same site has a few pages added, so rather than one page there are now 100 pages without the sitewide link, is the link still sitewide?
Most would probably err on the side of agreement that a site with 10,099 pages of which 9,999 have the same link is a sitewide link.
You can probably see where we are going.
If you subject the concept of sitewide links to scrutiny, then there is an implied threshold. Some level at which you can potentially have lots and lots of links from a site pointing somewhere but all these duplicates don’t qualify as sitewide.
This then begs the question. How many links must link out from a site to qualify them as sitewide? 100? 1000? 50%? 51%? 99%?
We weren’t happy assuming we knew what the right threshold for sitewide detection needed to be. Our conclusion was, “it depends.” How many times do you hear that in SEO?
We believe duplicate link detection leapfrogs sitewide analysis. Regardless of whether a duplicate link is detected on twenty pages, or two hundred pages, we feel it is worth flagging as such.
Applying duplicate link analysis to achieve backlink fidelity
We see this release as a huge step to achieving our goals set out in our September 2020 post “Roadmap: Backlink Fidelity vs Backlink Volatility” and our from January 2021 post “Counting Backlinks, and our 2021 Link Index Strategy”.
However, classifying the data is just one step in our mission to achieve the highest practical backlink fidelity. The next stage is a big one. We want to give you better, more usable data by delivering on a promise to “show FEWER backlinks in Fresh”. We will achieve that by preserving link diversity and referring domain count BUT reducing the number of duplicate links we store.
This is where flagging non-notable duplicates becomes important, as non-notable duplicates are candidates for removal. Our eventual plan is Noise Reduction, where we want to remove links from the Fresh Index which are detected as duplicate and pass no Trust Flow and Citation Flow.
How to download duplicate link data
Majestic provides a number of different ways to get data. We are working on simplifying this, but have made the duplicate links data available via the new style “Raw Export”. Here’s a quick refresher on how to access all the backlinks data we have for a URL or site ( note: availability depends on site and plan ).
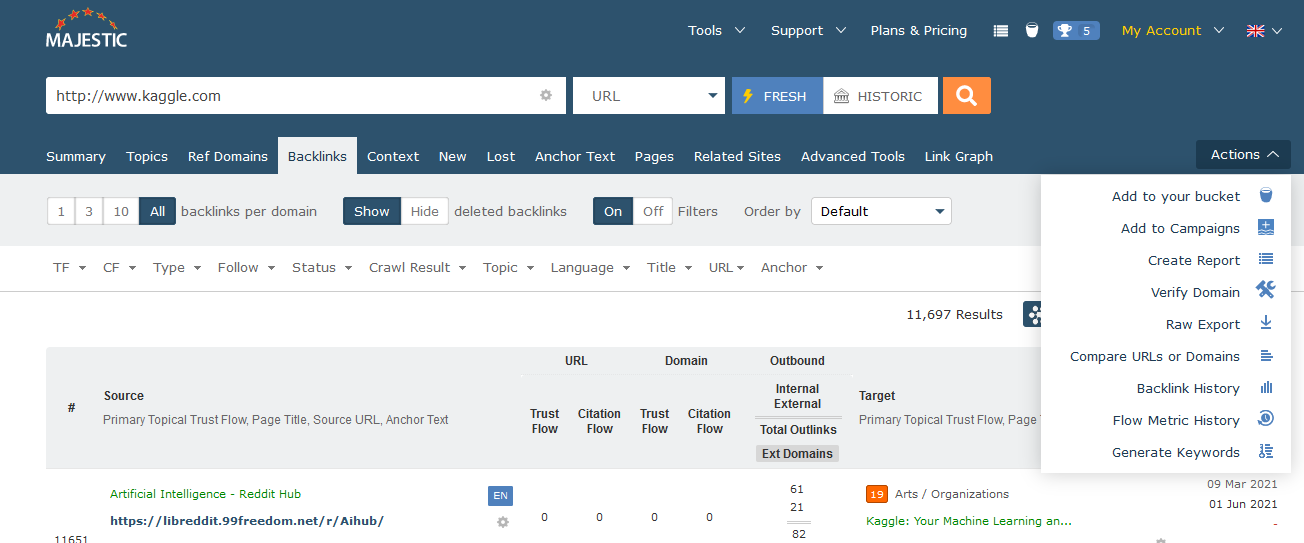
The “Raw Export” facility can be found in the “Actions” menu in Site Explorer. We are in the process of upgrading the Raw Export facility. To access the new fields, you’ll need to ensure you are using the new version of “Raw Export” which looks like the one below:
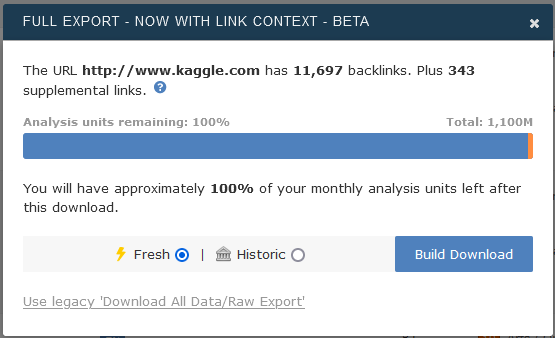
If your screen looks a little different, look for the “try the new Full Export” option. After you click “Build Download” you can either wait for confirmation of download here, or continue using Majestic and return to the download screen later.
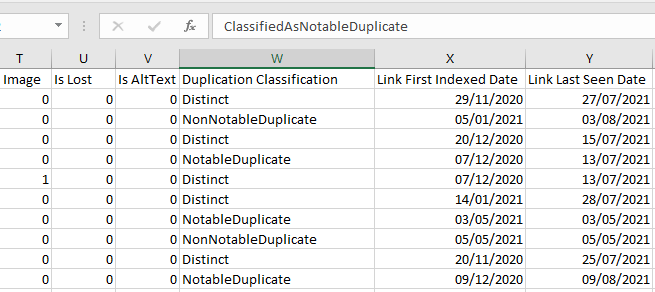
Majestic makes raw exports available in compressed “.tar.gz” format. If you use windows, you may need a program like 7-zip to extract the .csv data file after download. You can find the new duplicate link analysis in the “Duplicate Classification” column.
Things to be aware of
We’ve tried to cover the key takeaways above. However, in the interests of completeness, here are few more details:
- We plan to add filtering options to the backlink and link context reports for duplicate link types in due course.
- Initially the duplicate classification will only be available via the interface and new style full export.
- We are not planning to offer the link duplication analysis in the API in the near future.
- Noise reduction will be a link level operation. Referring domain counts and Flow Metric scores are highly unlikely to be impacted as a direct result.
- Eventually reducing the number of data rows in our index provides the opportunity for us to store more data. We want to then use that to expand the window of the Fresh Index beyond the current four-month window.
- Doing huge volumes of calculations is hard. Duplicate link analysis is performed by algorithms with little or no human involvement. We are delighted with the results of this project. BUT please do ensure you perform your own checks prior to placing reliance on heuristically generated data.
Duplicate Link Analysis is available in Site Explorer, from today, for Fresh Index URL, domain, and subdomain searches. Check out our free demo site for an example.

Steve has been engaged with the Birmingham tech scene for years, co-organising the grassroots open-source conference YAPC:: Europe 2008, and founding the West Midlands Java User Group in 2014.
- Majestic head office – relocation - March 31, 2026
- Introducing Duplicate Link Detection - August 27, 2021
- Python – A practical introduction - February 25, 2020
This looks like an impressive jump forward. Starts to make it obvious why some sites with millions of links go nowhere and others do well with very few.
August 31, 2021 at 9:17 amThank you, Steve, just checked our updated Majestic link profile and that looked different!
August 31, 2021 at 12:44 pmCan I ask a question, please? What will be the scenario if we have 5 articles on one website, a niche blog with probably hundreds of links to other websites as well, and 5 links to our website, 1 link for each article? Will they count as 1 or 5 distinct links.
Thanks, mate.
Hi Pooyan. The five links will be from 5 distinct unique source urls albeit from the same Referring Domain. They will still count individually as long as each source url has TF>0.
October 22, 2021 at 5:15 pm