






In diesem Beitrag werden wir KI aus einer kritischen Perspektive betrachten, manche würden vielleicht sagen, einer zynischen oder pessimistischen. Wir werden uns ansehen, wann KI Fehler macht, und einige Untersuchungen untersuchen, bei denen sich Experten die Mühe gemacht haben, komplexe Bilderkennungssysteme zu überlisten.
Dieser Blogbeitrag ergänzt den Vortrag “Resisting the AI Apocalypse”, der im Sommer 2021 auf der Brighton SEO präsentiert wurde. Die folgenden zusätzlichen Ressourcen sind ebenfalls verfügbar:
- Folien zum Vortrag
- Jupyter-Notizbücher, die einen schrittweisen Weg zum Austricksen einer KI und ein Beispiel für das alleinige Austricksen einer KI zeigen
- Ein GitHub Repo, das die oben genannten Notebooks und die dazugehörigen Ressourcen enthält
Wenn KI schief geht
Computer spielen eine immer größere Rolle in unserem Leben. Die Software-Algorithmen, die Suchmaschinen, Social-Media-Plattformen und sogar HR-Systeme antreiben, werden immer ausgefeilter, sind aber noch nicht perfekt und daher fehleranfällig.
@MinutelyHipster hebt zwei Suchergebnisse (bzw. Featured Snippet innerhalb der Suchergebnisse) hervor. Das eine ist für die Suche Weltrekord Rubik’s cube 1×1, die andere Suche fragt “wer hat das Laufen erfunden”. Beide Fragen lösen interessante Antworten aus.
- Der Weltrekord wurde offenbar in beeindruckenden 8 Minuten und 59 Sekunden aufgestellt.
- Es wurde behauptet, dass Thomas Running das Laufen erfunden hat, als er versuchte, zweimal gleichzeitig zu laufen.
Das sind nur zwei heitere Beispiele dafür, dass Dinge schief gehen können. Ich fand sie recht lustig, aber wenn KI schief geht, ist das nicht immer nur ein humorvolles Beispiel. Manchmal kann es ernsthafte Auswirkungen auf die Art und Weise haben, wie unser Leben funktioniert. Manchmal wurde KI in Einstellungs- und Rekrutierungsprozessen eingesetzt, so dass ein Algorithmus Einfluss darauf nehmen konnte, wer der erfolgreiche Kandidat sein sollte.
KI hat zwar keinen eigenen Verstand, aber manchmal tut sie so, als hätte sie einen.
Entscheidungen, die von KI-Systemen getroffen werden, haben nicht immer die Werte widergespiegelt, die Einzelpersonen und Organisationen möglicherweise wünschen. Diese subtile Folge der Delegation von Entscheidungen an Maschinen ist nicht auf das obige Beispiel der Personalbeschaffung beschränkt. Selbst etwas so scheinbar Einfaches wie die Entscheidung, wie ein Foto beschnitten werden soll, kann für KI zu viel sein, um mitfühlend zu sein.
Es muss gesagt werden, dass KI in einigen Fällen so beeindruckende Leistungen erbringen kann, dass man leicht in die Falle des Confirmation Bias tappt und annimmt, dass sie viele Dinge genauso gut macht wie die gezeigten Beispiele. Wie wir jedoch gesehen haben, hat KI Unzulänglichkeiten. KI ist anfällig für Fehler.
Im nächsten Teil sehen wir uns eine Fallstudie an, die zeigt, wie gut KI in Situationen ausgetrickst werden kann, in denen ein menschlicher Verstand dies nicht kann.
Kann KI den Menschen bei der Bilderkennung schlagen? Eine Fallstudie über das Brechen von “besser als menschlicher” KI.
Obwohl KI viele Anwendungen hat, wird sich diese Fallstudie auf die Bilderkennung konzentrieren. Der Inception-V3-Bilderkennungsalgorithmus von Google wurde ausgiebig untersucht. Inception-V3 war einer der ersten Algorithmen, der bei der ImageNet-Bilderkennungs-Challenge eine “besser als der Mensch”-Fehlerquote erreichte.
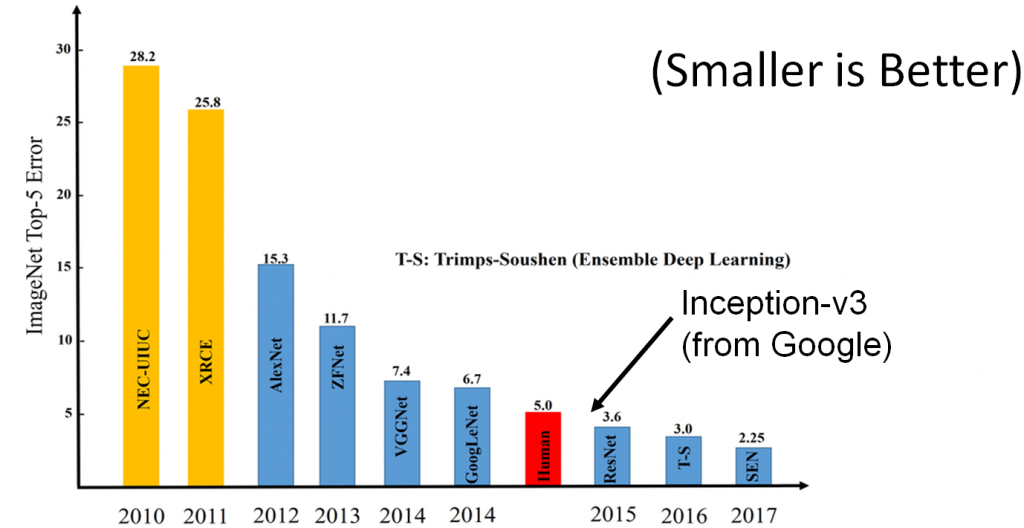
KI-Forscher haben in den letzten Jahren enorme Fortschritte auf dem Gebiet der Bilderkennung gemacht. Das Balkendiagramm oben versucht, diesen Fortschritt zu erfassen. Das Diagramm zeigt die Menge an Fehlern, die verschiedene “state of the art” KI-Bilderkennungsalgorithmen in einem anerkannten Bilderkennungswettbewerb gemacht haben. Das Tempo des Fortschritts ist schockierend. Das Diagramm beginnt im Jahr 2010, mit einer beträchtlichen Fehlerquote, insbesondere im Vergleich zur menschlichen Fehlerquote (in diesem Diagramm als roter Balken dargestellt). In der Grafik ist deutlich zu sehen, dass das Jahr 2012 einen riesigen Sprung in der Leistung der Bilderkennungs-KI darstellt und sich die Leistung danach bis 2014 stetig verbessert, wenn die KI-Fehlerrate beginnt, mit der Fehlerrate von Menschen vergleichbar zu werden.
Im Jahr 2015 sehen wir einen unglaublichen Meilenstein für den Bereich der künstlichen Intelligenz. Im Jahr 2015 übertreffen ResNet und Googles Inception-v3-KI den Menschen in diesem Bilderkennungswettbewerb. Eine enorme Leistung und ein Meilenstein in der Softwareentwicklung. (ResNet hat Inception im Jahr 2015 knapp geschlagen, daher der “Podestplatz” in der Grafik für 2015).
Bedeutet dies, dass die KI im Jahr 2015 den Menschen in Sachen Bilderkennung “schlägt”? Nicht unbedingt. Zwar hat KI eine nachweislich niedrigere Fehlerquote, aber wir haben bereits gesehen, dass KI andere Fehler macht als Menschen, und wie wir sehen werden, können diese Fehler gefördert werden…
Lassen Sie uns zunächst klarstellen, was wir mit einer KI zur Bilderkennung meinen. Bilderkennung ist eine alte Praxis in der KI. Tatsächlich sahen 1966 einige akademische Einrichtungen den Aufbau einer Bilderkennungs-KI als geeignetes Sommerprojekt für ihre Studenten an. Die moderne Bilderkennung hat seither natürlich einen weiten Weg zurückgelegt und ist weitaus intelligenter, mit weitaus größeren Fähigkeiten. Der ImageNet-Test konzentriert sich auf die Klassifizierung – d. h., man übergibt einer Bildklassifizierungs-KI ein Bild von etwas und vergleicht dann die Ausgabe der KI mit dem Namen der Entität im Bild, wie im Beispiel unten gezeigt:


Licence: https://creativecommons.org/licenses/by-sa/3.0/deed.en
“This is Guacamole”
An diesem Punkt mag sich der Test in Bezug auf die menschliche Wahrnehmung einfach anfühlen – Guacamole und Katze sind so unterschiedliche Dinge, dass niemand, auch keine KI-Algorithmen, sie verwechseln könnte. Oder könnten sie doch?
Dies scheint ein guter Punkt zu sein, um einige Forschungsergebnisse eines Teams am MIT vorzustellen, dem es gelungen ist, den Google Inception-V3-Algorithmus so auszutricksen, dass er ein Bild einer Katze für ein Bild von Guacamole hielt!
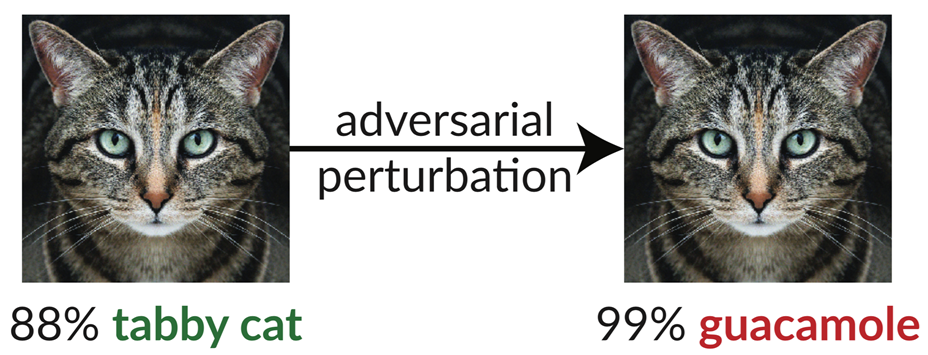
Wie? Sie nahmen ein Bild einer Katze, wie das auf der linken Seite zu sehende, das Inception V3 erfolgreich als gestromte Katze erkennen konnte. Dann wandten sie einen Prozess namens “adversarial perturbation” an, um es in das Bild auf der rechten Seite umzuwandeln. Für Menschen sieht das Bild immer noch ziemlich genau so aus wie das linke, aber für die KI ist diese Katze angeblich zu 99 % Guacamole. Der Begriff “adversarial perturbation” ist ein bisschen langatmig. In Wirklichkeit bedeutet es nichts anderes, als dass das Originalbild genommen und die Pixel auf die kleinstmögliche Art und Weise bearbeitet wurden, so dass die Änderungen für das menschliche Auge nicht wahrnehmbar waren, aber auf eine Art und Weise, die die KI dazu bringen sollte, einen Fehler zu machen.
Bevor wir näher darauf eingehen, wie sie die KI ausgetrickst haben, müssen wir uns erst einmal bewusst machen, wie KI funktioniert.
Eine kurze Einführung in die Funktionsweise der KI
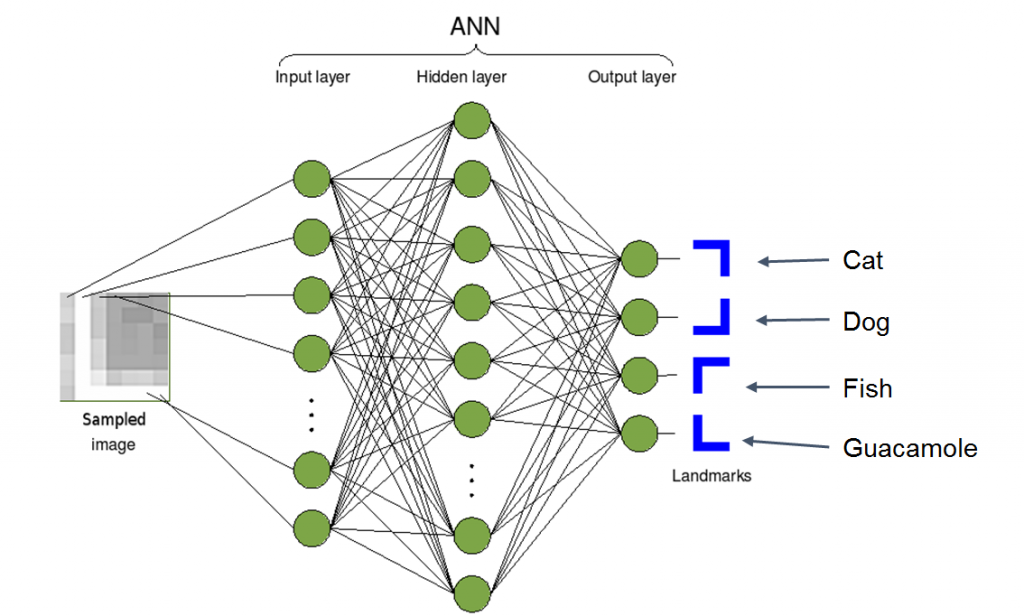
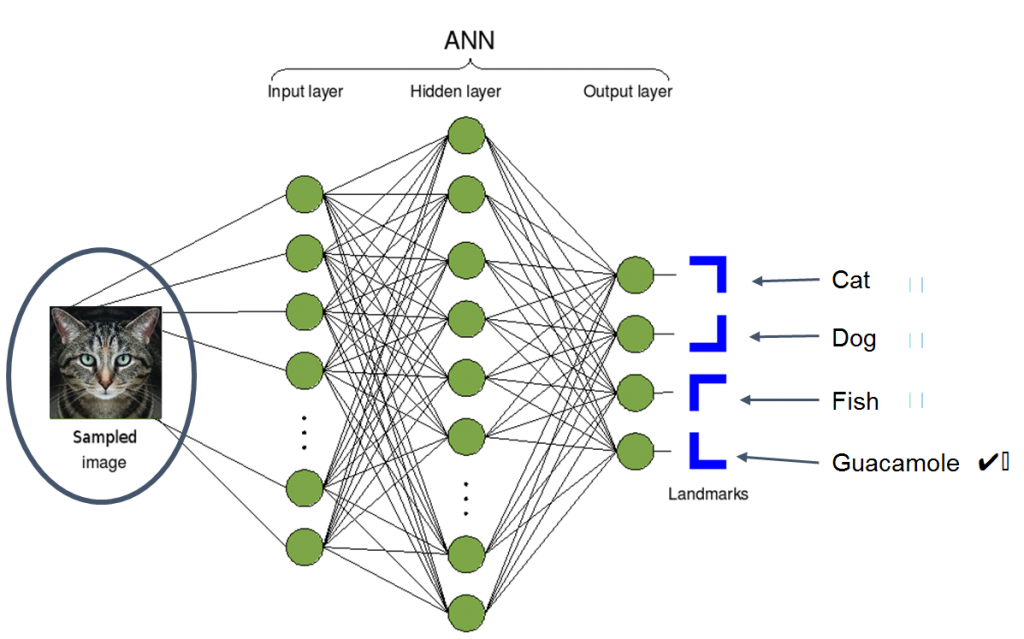
Das folgende Diagramm zeigt einen Überblick über die Funktionsweise eines Bilderkennungsalgorithmus. Auf der linken Seite nimmt die KI ein abgetastetes Bild auf. In der Mitte führt sie ein paar mathematische Berechnungen mit dem gelieferten Bild durch. Und auf der rechten Seite wird sie versuchen, eine Schlussfolgerung darüber zu ziehen, was dieses Bild ist. Es könnte entscheiden, dass das Bild eine Katze, ein Hund, ein Fisch oder in diesem Fall eine Guacamole ist.
<https://creativecommons.org/licenses/by-sa/3.0>,
via Wikimedia Commons
Das Bild geht also rein, die Mathematik passiert, und heraus kommt eine Klassifizierung. Das obige Bild stellt ein neuronales Netzwerk dar, was im Wesentlichen ein Begriff ist, den Informatiker und Mathematiker verwenden, um ein großes Geflecht aus einfachen Formeln zu beschreiben. Was diesem einfachen Diagramm jedoch fehlt, ist die Erklärung, wie etwas so Einfaches schlau werden kann. Die Antwort ist, dass jede der einfachen Formeln in dem Geflecht so abgestimmt werden muss, dass sie ihren Zweck zum Wohle der Allgemeinheit erfüllen kann.
Dieser Prozess, eine ziemlich nutzlose, ungetunte KI zu nehmen und sie so zu tunen, dass sie nützlich wird, wird Training genannt. Um eine KI für ihren Zweck tauglich zu machen, bedarf es einer Menge Training. In der Praxis wird das Training mit Hilfe einiger schöner Mathematik durchgeführt. Wir werden jedoch einen mathematikfreien Ansatz wählen und das Training auf einer konzeptionellen und nicht auf einer mathematischen Ebene beschreiben.
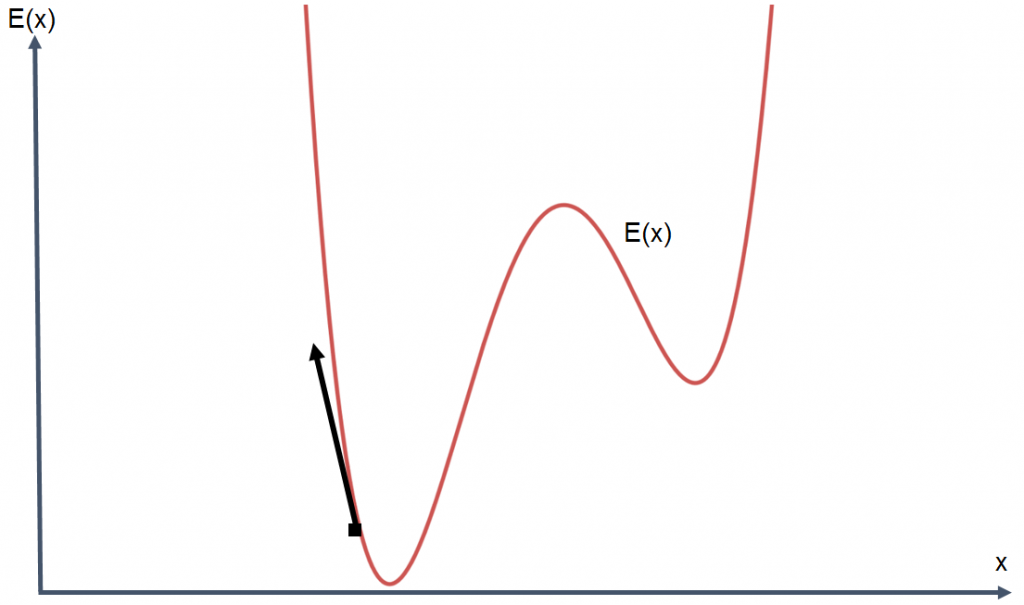
Ein wichtiger Input für das Training einer KI sind Beispieldaten, eine große Menge an Beispieldaten. Während des Trainings wird Mathematik auf die KI angewendet, um das zu tun, was als “Minimierung der Fehlerfunktion” bekannt ist.
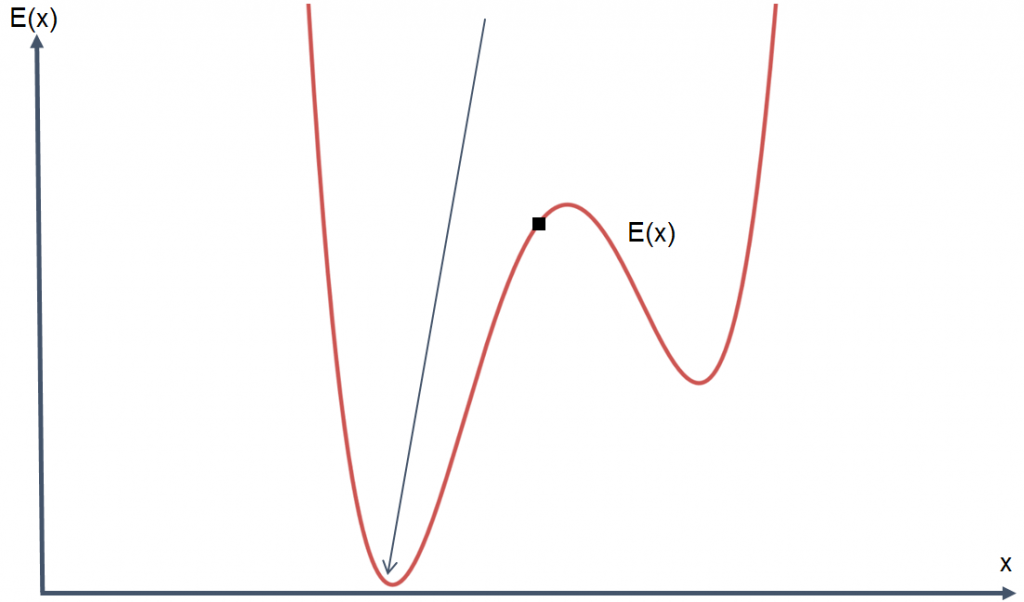
Die Fehlerfunktion kann als ein Maß für die “Falschheit” der KI betrachtet werden. Beim Training werden viele Eingaben und viel Mathematik verwendet, um die “Fehlerfunktion” zu “minimieren”, d. h. die Fehlerhaftigkeit der KI zu verringern. Das Ziel des Trainings und der Verbesserung einer KI ist es, den Fehler so klein wie möglich zu machen. In diesem Fall, Ihre KI an den unteren Rand des Graphen zu bringen.
Wenn man sich diesen Graphen ansieht, scheint das Problem einfach zu sein, weil man sieht, wo der untere Rand der Fehlerfunktion liegt, und denkt: “Aha, richtig, ja. Bewegen Sie den Punkt an die Stelle, wo der Pfeil ist”. Leider ist die Fehlerfunktion beim Tuning einer KI oft viel komplexer als unsere Visualisierung und hängt mit dem Training der KI zusammen. Leider kann man einem Computer nicht einfach einen Graphen der Fehlerfunktion seiner KI vorlegen und ihn anweisen, den Boden zu finden. Was man tatsächlich tun muss, ist, die Einstellungen der KI langsam zu verändern, um den Fehler Stück für Stück zu reduzieren.
Der Trainingsprozess weiß, wo er sich auf der Kurve befindet, und auch, welche Richtung nach unten geht. In diesem Fall könnte es also sein, dass Sie eine KI mit einer bestimmten Fehlerquote haben, und wir würden sie trainieren und sie bitten, sich selbst zu verbessern.
Wenn eine KI ihren Weg der Fehlerminimierung beschreiben könnte, würde sie vielleicht sagen: “Hm, ich bin hier. Und wenn ich mich nach links bewege, ist das der Weg, um auf der Kurve nach unten zu kommen, also werde ich das tun.”. Dieser Schritt führt dazu, dass die KI ein wenig besser wird. Ihr Fehler wird leicht reduziert. Es kann jedoch noch mehr getan werden, um die KI zu verbessern. Der Prozess geht weiter, Schritt für Schritt, die KI bewegt sich die Kurve hinunter. Auf diese Weise werden KIs trainiert. Der Grund, warum sie als “intelligent” bezeichnet werden, ist, dass das Training einer KI zu einem Prozess der Selbstoptimierung führt, der den Algorithmus weniger fehleranfällig macht. In den meisten Phasen dieses Prozesses wird die KI eine gewisse Fehlerquote haben und sehr, sehr langsam, Stück für Stück, versuchen, diesen Fehler zu reduzieren, indem sie ihre Einstellungen ändert, um genauere Berechnungen oder Klassifizierungen durchzuführen.
Die mathematische Form dieses Prozesses ist als “Gradient Descent” bekannt und funktioniert mehr oder weniger nach dem oben beschriebenen Muster, nur mit komplexeren Berechnungen. Nachdem wir nun gesehen haben, wie eine KI lernen kann, wollen wir uns nun damit beschäftigen, wie sie getäuscht werden kann.
Vom Training zur Verwirrung einer KI.
Nachdem wir gesehen haben, wie wir eine KI trainieren können, um besser zu werden, wollen wir uns nun ansehen, wie wir ein Bild erzeugen können, das eine KI dazu bringt, einen Fehler zu machen.
Eine Falle ist hier zu denken, dass wir einfach das Gegenteil des Trainingsprozesses tun können – das ist jedoch nicht wirklich fair, denn eine KI einfach umzustimmen ist in etwa gleichbedeutend damit, sie mit einem Hammer zu erschlagen. Der Vorgang mag die Funktionsweise einer KI stören, aber er verwirrt oder überlistet sie nicht.
Wir können die KI zwar nicht zerstören, aber wir können trotzdem versuchen, die Fehlerrate zu erhöhen, indem wir die Fehlerfunktion maximieren, anstatt sie zu minimieren.
Da es nicht möglich ist, die KI zu zerstören, bleibt uns nur die Eingabe.
Sie erinnern sich vielleicht daran, dass die Funktionen im neuronalen Netz durch Minimierung der Fehlerfunktion abgestimmt wurden, um eine KI intelligenter zu machen. Wir können eine ähnliche Technik anwenden, um die Fehlerfunktion zu maximieren, indem wir das Eingabebild langsam, Schritt für Schritt, anpassen und versuchen, die Fehlerrate mit jedem Schritt zu erhöhen. Anders ausgedrückt: Wir nehmen ein Bild, das die KI korrekt klassifiziert, und verändern es so lange, bis die KI verwirrt ist.
In diesem Fall manipulieren wir nicht eine KI, sondern ein Bild. Da wir mit einem Bild beginnen, das von einer KI erfolgreich klassifiziert wurde, ist es naheliegend, dass es, wenn es durch die KI geschickt wird, nicht viele Fehler in seiner Klassifizierung haben wird.
Der Schlüssel zur Minimierung der Änderungen, die ein Mensch wahrnimmt, aber zur Maximierung der Änderungen, die eine KI erkennt, liegt darin, die Pixel eines Bildes prägnant und sehr sorgfältig so zu manipulieren, dass der Fehler der Klassifizierung maximiert wird.
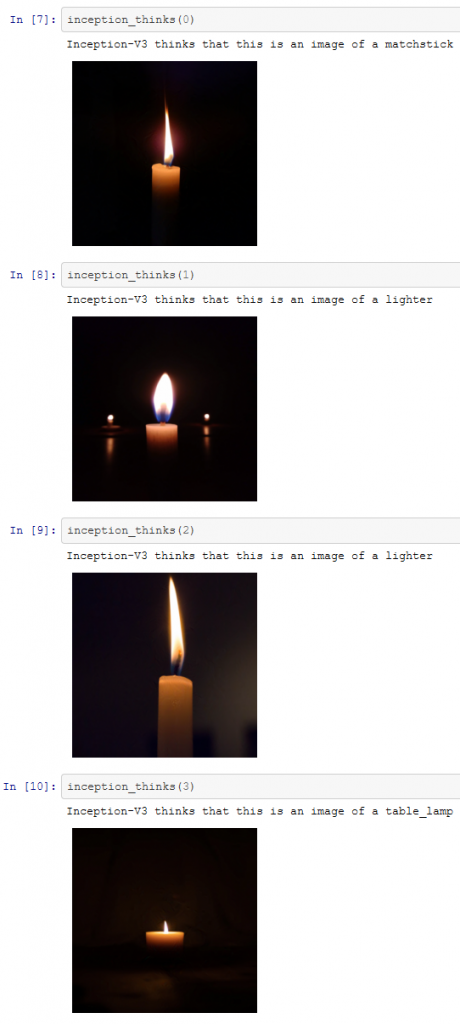
An diesem Punkt können wir unser Python-Notebook herausholen (diese Beispiele wurden in Jupyter programmiert) und versuchen, einige Bilder zu finden, die mit Inception V3 verwendet werden können.
Einige entscheiden sich vielleicht für eine Google-Bildersuche – unsere Bilder stammen von unsplash. Für unsere ausgewählten Bilder werden diese sieben Kerzen von Inception-v3 korrekt klassifiziert.







Wenn Sie sich für den Code zum Nachvollziehen interessieren, wird das Python-Notebook ein wirklich nützlicher Begleiter. Wenn Python nicht Ihr Ding ist, lesen Sie einfach weiter – wir werden versuchen, diesen Beitrag eine Mathe- und Pythonfreie Zone zu halten!
Wir haben nun sieben gültige Bilder, die korrekt klassifiziert wurden. Das bedeutet, dass wir versuchen können, den oben beschriebenen Prozess zur Maximierung der Fehlerrate zu verwenden, um die KI zu verwirren. Die durch diesen Prozess erzeugten Bilder sind unten dargestellt.
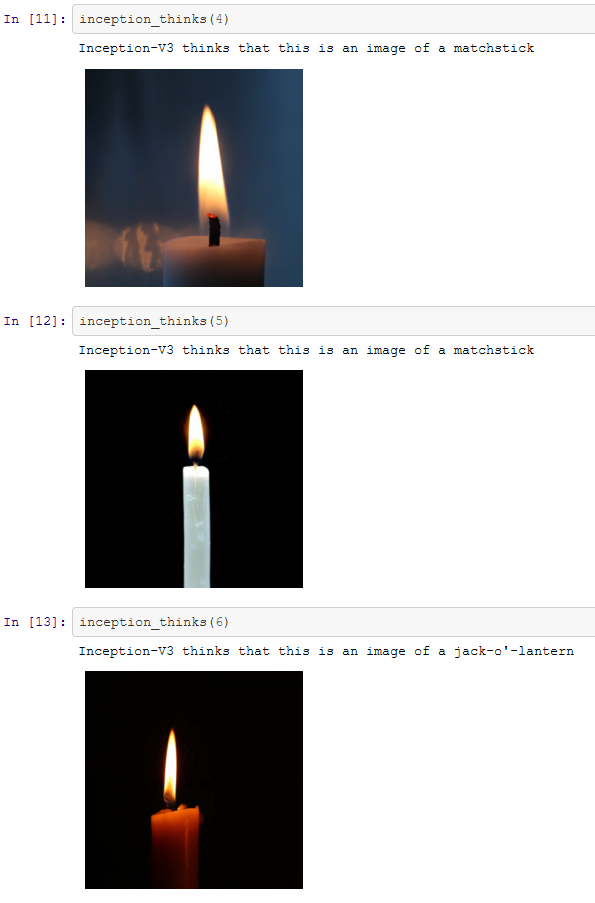
Obwohl die Fehlklassifizierung nicht besonders extrem ist, haben wir es geschafft. Inception scheint es geschafft zu haben, die veränderten Bilder als Objekte zu identifizieren, die den Kerzen irgendwie ähnlich sind. Im weiteren Verlauf wird sich jedoch zeigen, dass wir Inception zu weitaus schwerwiegenderen Fehlern zwingen können.
Nichtsdestotrotz haben wir es erfolgreich geschafft, die KI zu verwirren!
Das ist aber immer noch nicht das, was die Forscher erreicht haben. Wir haben zwar die Bilderkennung “verpfuscht”, indem wir die KI verwirrt haben, aber wir haben sie nicht wirklich getäuscht. Lassen Sie uns jetzt dazu übergehen.
Von der KI-Verwirrung zur KI-Täuschung.
Während das “Verwirren” der KI unterhaltsam war, haben wir es noch nicht geschafft, die KI auszutricksen, damit sie ein Bild als ein Objekt unserer Wahl falsch klassifiziert. Wie wir bereits beim Katzen-Guacamole-Beispiel gesehen haben, haben die Forscher eine KI nicht nur verwirrt, damit sie eine Klassifizierung falsch vornimmt, sondern sie haben eine KI tatsächlich dazu gebracht, ein Bild als eine ganz bestimmte Sache zu klassifizieren. Das Beispiel, das wir hervorgehoben haben, bestand darin, ein Bild einer Katze zu nehmen und die KI dazu zu bringen, dieses Bild fälschlicherweise als Guacamole zu klassifizieren.
Der Fachausdruck dafür, eine KI so auszutricksen, dass sie ein Bild fälschlicherweise als ein Bild Ihrer Wahl klassifiziert, heißt “Erzeugen eines gezielten Gegners”. Um es noch einmal zu betonen: Es geht darum, etwas zu erzeugen, das die KI zu einem Fehler veranlasst, aber Sie wollen, dass der Fehler ein ganz bestimmter Fehler ist.
Das Verfahren zum Erstellen eines gezielten Gegners ist ähnlich wie das oben beschriebene Verfahren zum Verwirren der KI. Auch hier wird das Eingabebild manipuliert, aber anstatt die KI einfach durch Maximierung der Fehlerfunktion zu einem Fehler zu veranlassen, wird ein etwas anderer Ansatz gewählt. Anstatt nur die Fehlerfunktion zu maximieren, müssen wir die Fehlerfunktion für die falsche Klassifizierung minimieren.
https://creativecommons.org/licenses/by-sa/3.0,
via Wikimedia Commons
In diesem Fall minimieren wir wieder die Fehlerfunktion, aber der Fehlerbetrag dafür, dass das Katzenbild nicht wie Guacamole aussieht, zumindest in den Augen der KI
Auch hier wird die Reise in vielen kleinen Schritten durchgeführt. Die Reise kann man sich als eine fortlaufende Unterhaltung zwischen unserem manipulierten Bild und der KI vorstellen.
Wir beginnen mit unserem Bild einer Katze, geben es an die KI weiter und sagen ihr: “Das ist keine Katze, das ist eine Guacamole”.
Die KI antwortet: “Nein, ich bin mir sicher, dass das eine Katze ist.”.
Wir sagen: “Nein, du liegst falsch. Es ist eine Guacamole.”.
Die KI antwortet: “Ich bin mir zu 97% sicher, dass das keine Guacomole ist.”
Wir denken “AHA – lass uns das Bild bearbeiten und die KI erneut fragen”…
Wir tun dies, wiederholen es, die KI antwortet “Ich bin mir zu 94% sicher, dass das keine Guacomole ist”.
Und der Prozess geht weiter…
In einem ähnlichen Prozess wie beim letzten Mal bearbeiten wir die Pixel, aus denen das Bild besteht. Dies führt dazu, dass die KI das Bild als etwas mehr wie Guacamole interpretiert. Der Prozess wiederholt sich, und nach vielen Iterationen und Bearbeitungen des Bildes haben wir, soweit es die KI betrifft, die Katze erfolgreich in Guacamole umgewandelt, genau wie es die Forscher getan haben.
Der Code für die KI-Katzen-Guacamolifikation ist in diesem Jupyter-Notebook zu finden, dessen Ergebnisse unten gezeigt werden:


Der Prozess ist nicht darauf beschränkt, der KI vorzugaukeln, dass Katzen Guacamole sind. Mit ein paar Zeilen Python könnten wir z. B. die Bilder von Kerzen, die im obigen Abschnitt verwendet wurden, nehmen und sie verändern. Vielleicht könnten wir die KI so trainieren, dass sie denkt, die Kerzen seien Fäustlinge?
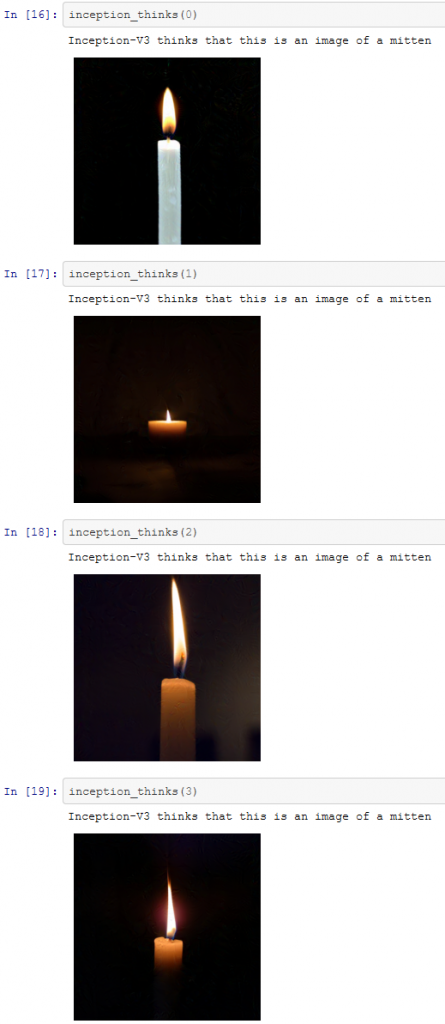
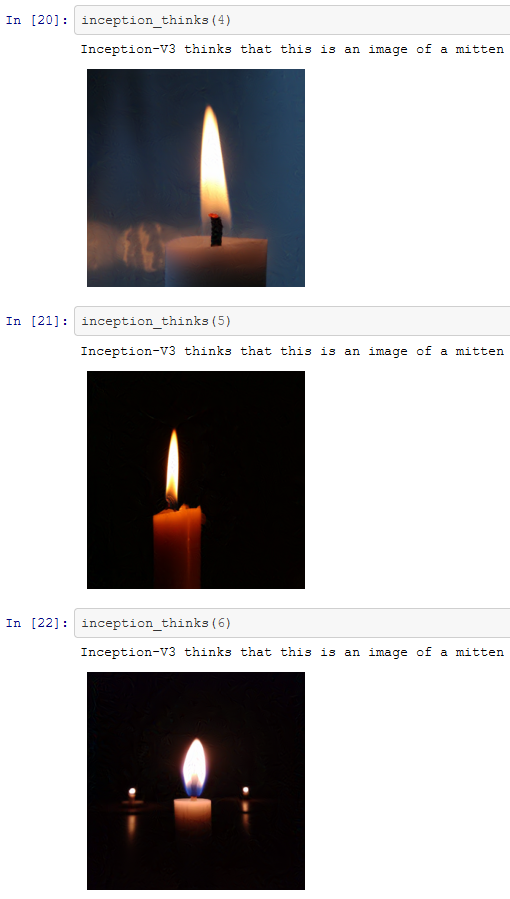
So sieht’s aus. Mit nur ein paar Zeilen Code können wir ganz einfach Bilder erstellen, die die KI nicht klassifizieren kann. Sie müssen keinen Supercomputer haben oder ein Experte auf diesem Gebiet sein, um dies zu tun. Die Arbeit für diesen Blog-Beitrag wurde durchgeführt, indem einige Bilder auf einen Laptop kopiert wurden und etwas Code ausgeführt wurde. Das Ergebnis – Bilder, die auf einem Laptop produziert wurden, die die Inception-v3-KI verwirrten, und einige, die die KI gezielt zu Fehlern verleiteten.
Damit haben wir gezeigt, dass künstliche Intelligenz nicht nur fehlbar ist, sondern auch überlistet werden kann. Kehren wir zu der oben hervorgehobenen Grafik zurück, die die Fehlerraten der KI mit denen des Menschen vergleicht.
Eine Interpretation dieser Grafik könnte lauten: “2015 war das Jahr, in dem KI bei der Bilderkennung besser wurde als der Mensch”. Diese Schlussfolgerung würde eine wichtige Nuance übersehen. Wenn wir uns die Beispiele ansehen, wie wir die KI verwirren und austricksen konnten, ist es dann fair, zu behaupten, dass die KI bei der Klassifizierung von Bildern besser ist als der Mensch?
Dies zu behaupten hieße, eine wichtige Nuance im Graphen zu übersehen. Die Grafik ist nicht dazu gedacht, die menschliche Bilderkennung zu erfassen oder zu vergleichen. Stattdessen zeigt die Grafik, dass KI bei einem bestimmten Maß, das bei diesem speziellen Wettbewerb von ImageNet verwendet wurde, besser wurde als der Mensch.
Die bisherigen Fortschritte in der KI und Bilderkennung sind wirklich beeindruckend. Es gibt jedoch immer noch viele Schwachstellen, die diese KI hat und denen Menschen nicht zum Opfer fallen. 2015 war ein fantastisches Jahr der Errungenschaften für die Informatik und die KI-Forschung, aber der Moment, in dem die KI besser als der Mensch in der Bilderkennung wird? So weit sind wir noch nicht.
Die Täuschung der KI einen Schritt weiter bringen
Seit der Veröffentlichung des Artikels, auf dem dieser Blog basiert, haben Forscher dieses Konzept weiterentwickelt – und auf reale Objekte angewendet. Was Sie hier sehen können, ist, dass die Forscher tatsächlich eine Schildkröte in 3D gedruckt haben, die einen gezielten Angriff auf die Inception-v3-KI darstellt.

In diesem Fall haben Sie also tatsächlich etwas, das eine Schildkröte zu sein scheint. Sie haben eine KI, die versucht, sie zu erkennen, und scheitert. Die KI klassifiziert das, was für das menschliche Auge eine Schildkröte zu sein scheint, als ein Gewehr. In zwei Fällen gelingt es der KI überhaupt nicht, sie zu klassifizieren. Ein Video, wie das in der Praxis funktioniert, können Sie hier sehen.
Es geht also nicht mehr nur um Bilder. Wir können 3D-Objekte in der realen Welt erzeugen, die die KI dazu verleiten, falsche Schlüsse darüber zu ziehen, was sie sind.
Fazit
Die obige Fallstudie konzentriert sich nur auf eine Form der KI. Wir sollten nicht davon ausgehen, dass alle Formen der KI an der gleichen Schwachstelle leiden.
Die Arbeit mit KI und maschinellem Lernen macht eigentlich sehr viel Spaß. Doch so viel Spaß es auch macht, wir müssen die ethischen Auswirkungen unseres Handelns bedenken. KI wird wahrscheinlich nicht unser Leben ruinieren – zumindest nicht im Sinne einer apokalyptischen Kernschmelze, bei der Maschinen die Erde übernehmen, aber Programmierer könnten es.
Die meisten Menschen haben keine Kontrolle darüber, wie KI funktioniert, aber KI hat die Kontrolle über wichtige Teile unseres Lebens. KI kann Dinge kontrollieren, wie zum Beispiel, wer es verdient, einen Job zu bekommen, wer es verdient, eine Hypothek zu bekommen, oder sogar, wer es verdient, in ein Land einzureisen. Und wenn KI in der Lage ist, Fehler zu machen oder ausgetrickst zu werden, inwieweit können wir ihrer Umsetzung für diese Zwecke vertrauen?
Vielleicht liegt es auf der Hand, dass wir KI ein wenig kritischer gegenüberstehen müssen, vor allem, wenn wir sie für so viele wichtige Anwendungen einsetzen werden.

- Hacker-Leitfaden zum Widerstand gegen die KI-Apokalypse - August 5, 2021