





Questo articolo è tratto dai contenuti creati e presentati nell’ambito dell’evento Brighton SEO Estate 2021. Ulteriori contributi sono disponibili per approfondire l’argomento nell’elenco che segue:
- Copia della presentazione data al Brighton SEO
- Jupiter Notebook con una procedura passo-passo per ingannare l’Intelligenza Artificiale (I.A.)
- Link ad un repo GitHub contenente i notebook citati e tutte le risorse ad essi associati.
Questo articolo vuole illustrare l’Intelligenza artificiale con uno spirito critico. Alcuni potrebbero obiettare che si tratta di un punto di vista cinico o da pessimista. Affronteremo il tema dell’I.A. prendendo in esame quei casi in cui l’I.A. sbaglia commettendo degli errori. Esamineremo alcuni casi in cui esperti si sono dedicati a sviluppare situazioni tali da ingannare sistemi complessi per il riconoscimento delle immagini.
Quando l’I.A. “si sbaglia”…
L’I.A. ha una diffusione capillare, anche se non ce ne accorgiamo. Il software che alimenta motori di ricerca, piattaforme di social media nonché sistemi per la gestione delle risorse umane, utilizzano algoritmi di valutazione molto complessi ma non perfetti e quindi possono commettere degli errori.
Questi sono gli algoritmi che governano la nostra vita
Kran (@MinutelyHipster) February 7, 2021
@MinutelyHipster propone due risultati di ricerca (o meglio uno snippet preso dai risultati di ricerca). Il primo è relativo alla ricerca per record mondiale del cubo di Rubrik 1×1, mentre l’altro è la domanda “chi ha inventato la corsa”. Il motore di ricerca propone risposte interessanti.
- Stando a quanto riportato, il record del mondo è stato stabilito con un tempo impressionante di 8 minuti e 59 secondi.
- Il motore di ricerca ci suggerisce che Thomas Running ha inventato la corsa nel tentativo di “camminare due volte allo stesso tempo” (…when he tried to Walk twice at the same time).
Questi sono due tra i molti esempi che mostrano quando l’I.A. commette degli errori. Purtroppo gli errori che sistemi sofisticati come questi possono commettere non sempre suscitano ilarità e possono avere delle conseguenze molto serie con ricadute sulla nostra vita. Ad esempio c’è stato questo episodio recente dove è stato permesso ad un algoritmo di stabilire quale fosse il candidato ideale per ricoprire un ruolo in azienda.
Pur non avendo una coscienza o una mente, l’I.A. può assumere degli “atteggiamenti” che possono emulare un comportamento simile a quello di una persona.
Le decisioni a cui giunge un sistema di I.A. non sempre riflette i valori che individui e organizzazioni vorrebbero per se o per le loro aziende. Delegare decisioni ad una macchina può creare problemi in ambiti molto diversi da quello della selezione del personale. Ad esempio, l’applicazione di queste tecnologie tra la scienza esatta della matematica e dell’informatica possono riservare delle brutte sorprese anche per una banale operazione di scontornatura di una immagine.
Allo stesso tempo casi di successo nel campo dell’I.A. sono numerose e con risultati eccellenti. Sono proprio questi casi di successo che inducono a pensare che l’applicazione diffusa dell’I.A. possa garantire lo stesso livello di affidabilità in ogni settore. La realtà dei fatti ci dice che ci sono molte opportunità per commettere errori applicando questa tecnologia.
A questo proposito affrontiamo un caso dove dimostriamo come si può trarre in inganno un sistema di I.A. in situazioni in cui una persona non sbaglierebbe.
L’intelligenza Artificiale può battere una persona nel riconoscimento delle immagini?
Questo è un caso di studio in cui si dimostra come un sistema di I.A. che sulla carta è “superiore all’uomo” è stato messo in crisi. Il caso in esame è relativo al riconoscimento delle immagini. C’è stata molta ricerca sull’algoritmo Inception-V3 Image Recognition prodotto da Google. Inception-V3 è stato uno dei primi algoritmi a battere l’uomo nel riconoscimento delle immagini nella sfida ImageNet.
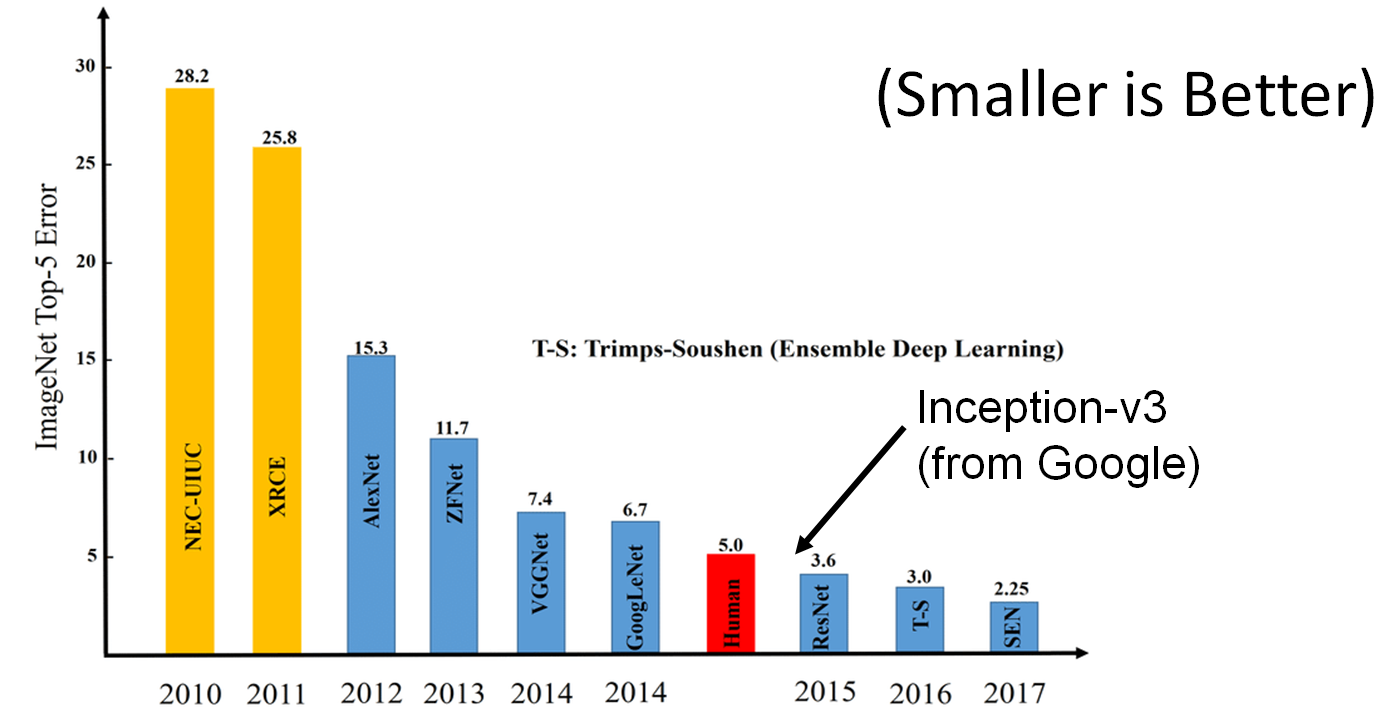
La ricerca nel campo del riconoscimento delle immagini ha fatto passi da gigante negli ultimi anni. L’immagine precedente illustra il perfezionamento della tecnologia. L’evoluzione degli algoritmi è impressionante. Partendo dal 2010 si vede il divario tra l’errore degli algoritmi rispetto all’errore tipico di una persona. Già nel 2012 la distanza si è notevolmente accorciata con un costante miglioramento di performance negli anni successivi. Si arriva così al 2014 ad un errore delle macchine che è comparabile a quello di una persona.
Nel 2015 c’è il sorpasso dell’I.A. sull’uomo con ResNet e Google’s Inception-V3 che ci battono nella competizione. È un traguardo importantissimo nella storia dello sviluppo software (ResNet ha avuto la meglio su Inception nel 2015 aggiudicandosi il titolo di miglior performance).
La domanda sorge spontanea:
L’Intelligenza Artificiale batte l’uomo nel riconoscimento delle immagini?
Non necessariamente.
Pur garantendo un minor tasso di errore, gli algoritmi commettono altri tipi di errori. Infatti ne abbiamo elencati alcuni tra i più clamorosi per sottolineare il concetto che gli algoritmi non sono infallibili. Non solo si verificano gli errori – questi errori possono essere indotti.
La definizione di I.A. per il riconoscimento di immagini
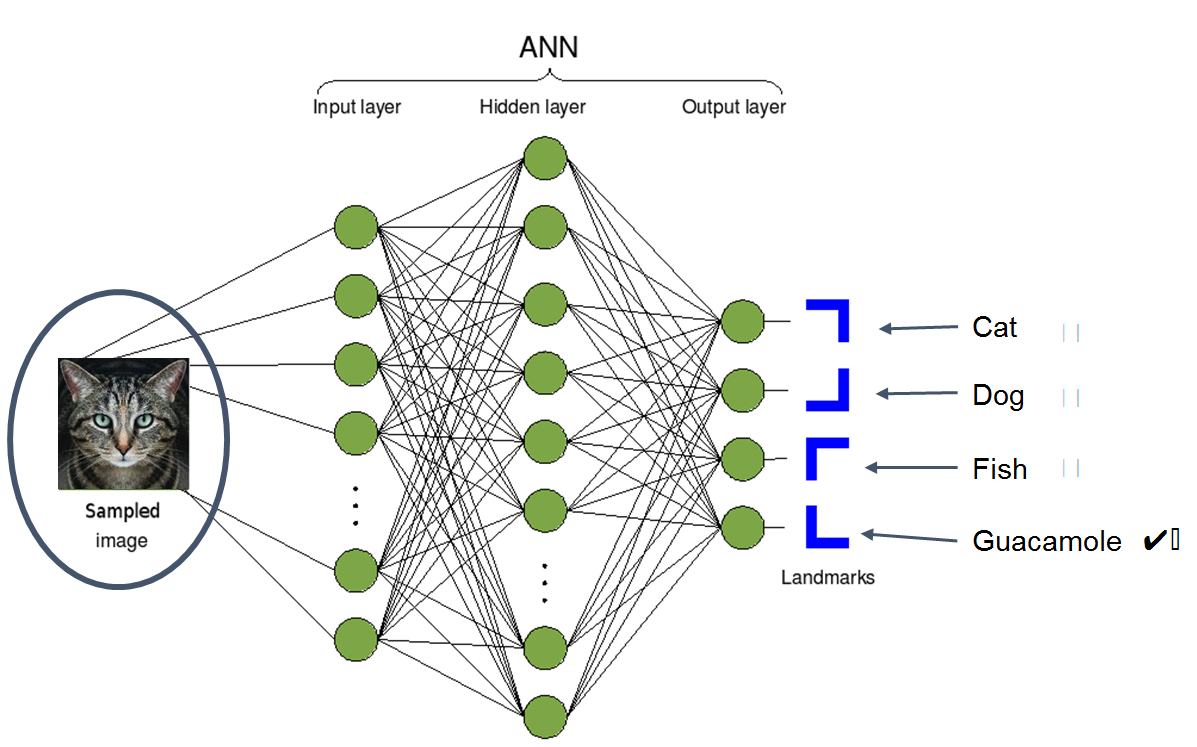
Prima di andare avanti è opportuno chiarire il significato di riconoscimento di immagini. Si tratta di una tecnologia matura che ha origini nel 1966 quando alcune istituzioni accademiche decisero di assegnare un progetto estivo agli studenti. Oggi il riconoscimento delle immagini concentra l’analisi nella classificazione. La procedura assegna ad un classificatore di immagini che si basa sull’I.A. un’immagine di qualcosa per poi confrontare l’output dell’I.A. con il nome dell’entità dell’immagine così come si può vedere nell’immagine che segue:


Licence: https://creativecommons.org/licenses/by-sa/3.0/deed.en
“Questo è Guacamole”
Abbiamo due immagini di cose completamente diverse tra loro. Sicuramente il nostro algoritmo non avrà alcuna difficoltà a distinguere i due soggetti… o forse si?
A questo punto è opportuno introdurre l’analisi sviluppata da una squadra di ricercatori dell’MIT che sono riusciti a trarre in inganno l’algoritmo Google Inception-V3 facendogli credere che l’immagine di un gatto fosse Guacamole!
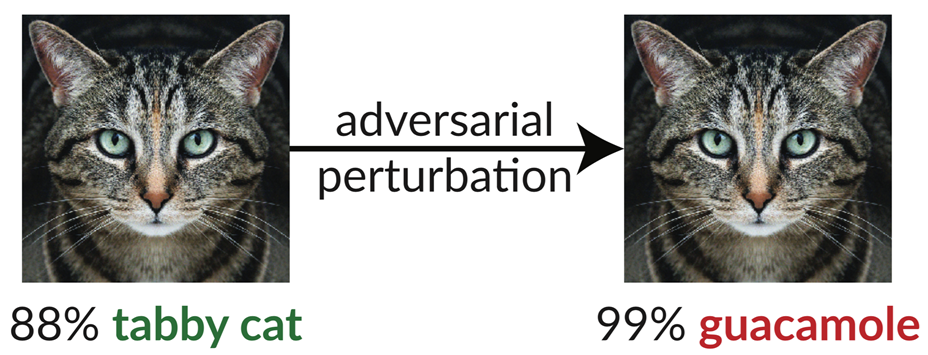
Ma com’è possibile che un algoritmo così avanzato possa cadere in una trappola come questa e fare un errore di valutazione così clamoroso? I ricercatori hanno preso un’immagine che Inception V3 riconosce come un gatto Tabby. Hanno quindi applicato un processo chiamato “adverserial perturbation” per trasformarla nell’immagine sulla destra. A noi sembrano identiche, ma per l’algoritmo l’immagine sulla destra è, con un grado di affidabilità pari al 99%, guacamole. Il termine adverserial perturbation è un modo di dire piuttosto pomposo che significa manipolazione dell’immagine. I ricercatori hanno abilmente modificato i pixel facendo credere all’algoritmo che l’immagine è sicuramente un piatto da degustare e non un gatto. Si tratta di cambiamenti talmente sottili che sfuggono all’occhio umano ma non all’algoritmo che per questo viene tratto in inganno.
Prima di spiegare come i ricercatori sono riusciti a trarre in inganno l’algoritmo, dobbiamo spiegare come funziona l’I.A. che c’è dietro.
Una breve introduzione sulla I.A. e il suo funzionamento
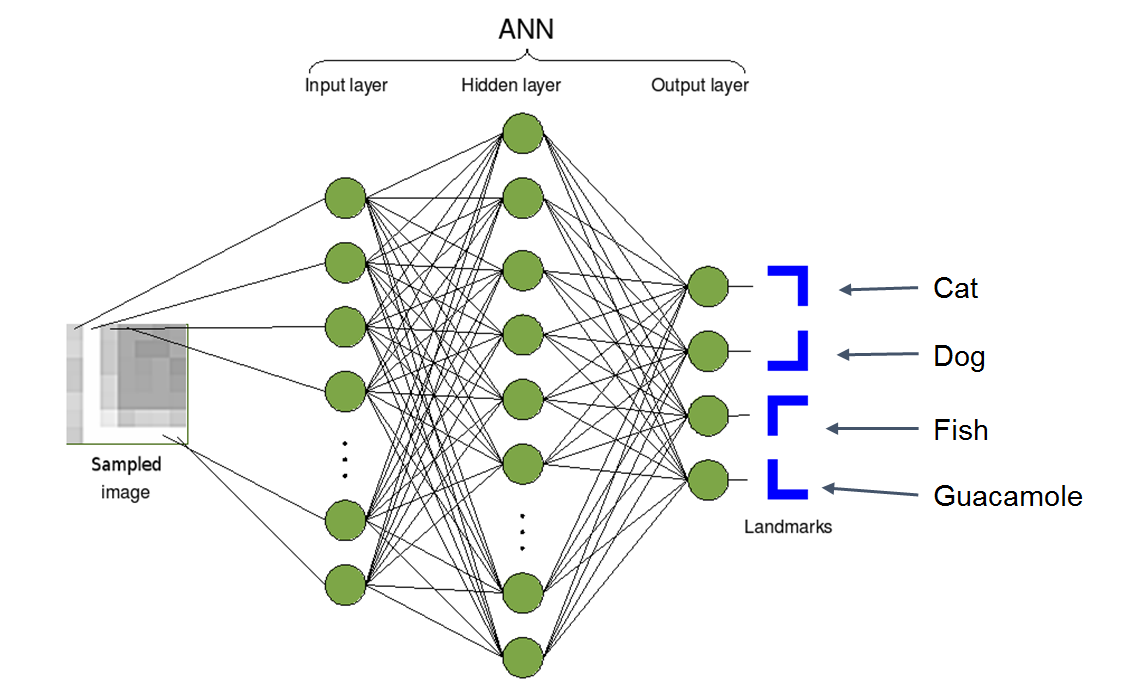
Il diagramma che segue illustra la logica di funzionamento di un algoritmo per il riconoscimento delle immagini. Sulla sinistra l’algoritmo acquisisce l’immagine da processare. Al centro del diagramma di flusso ci sono una serie di attività – soprattutto calcoli matematici per determinare la natura dell’immagine. Infine sulla destra l’immagine viene classificata. L’algoritmo decide se si tratta di un cane o un gatto, di un pesce o di guaiamole.
<https://creativecommons.org/licenses/by-sa/3.0>,
via Wikimedia Commons
Quindi l’algoritmo acquisisce l’immagine che viene processata e poi la classifica. Lo schema precedente rappresenta una rete neurale. Una rete neurale è definita così da matematici e informatici per descrivere una serie di formule semplici che costituiscono un algoritmo di calcolo. Questo diagramma non spiega come un insieme di procedure semplici possa esprimere una intelligenza (oppure, se vogliamo, diventare intelligente). La risposta è che gli elementi che costituiscono l’algoritmo devono essere opportunamente tarati per lavorare con le altre formule per risolvere un problema complesso.
Il processo appena descritto è quello tipico di un’attività di I.A.
A pensarci bene, abbiamo creato un sistema generico e lo abbiamo applicato ad un caso particolare: Il riconoscimento delle immagini per distinguere un gatto dal guacamole o altro animale o cosa. Attraverso verifiche di performance ne valutiamo l’accuratezza, effettuando al tempo stesso delle calibrazioni. In Data Science questo processo di calibrazione si chiama Training. Rendere un modello come questo “intelligente” richiede molta matematica e dati sperimentali con cui lavorare. Descrivere in dettaglio la parte concettuale va ben oltre lo scopo di questo articolo e richiederebbe molto tempo. Facciamo un ragionamento qualitativo per spiegare il funzionamento.
Il modello deve “imparare”
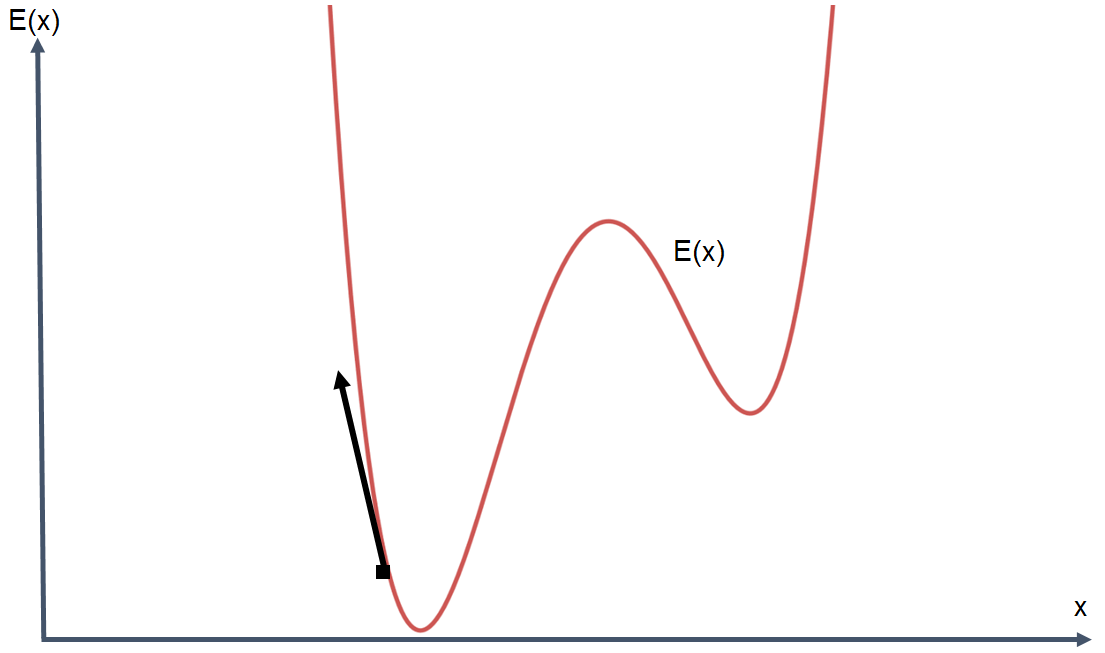
I modelli di I.A. devono imparare. E per imparare hanno bisogno di molti dati sperimentali. Il processo di apprendimento consiste nella valutazione degli errori commessi dal modello e successive azioni correttive di taratura. Il modello diventa tanto più “intelligente” quanto meno sbaglia. Sbagliare meno significa meno errori e quindi rendere minima la funzione degli errori di cui riportiamo un esempio nell’immagine seguente:

Utilizzando i dati sperimentali a nostra disposizione, dobbiamo modificare i parametri del modello in modo tale da ottenere dei risultati con un errore tipico che sia il più possibile vicino alla zona della curva indicata dalla freccia nell’immagine precedente, ovvero dove l’errore risulta minimo.
Qualcuno di voi potrebbe pensare che si tratta di un’operazione semplice: fornire al computer il modello generico, i dati sperimentali e la curva degli errori per far fare tutto al computer. Purtroppo non è così. Il computer esegue istruzioni che gli vengono imposte da noi. Noi dobbiamo dire al computer come fare per minimizzare l’errore. Il processo di addestramento dell’algoritmo è lento e richiede competenze particolari nonché ottima conoscenza del processo che si sta analizzando.
Se l’algoritmo potesse parlare e descrivere il suo viaggio alla ricerca del valor minimo dell’errore ci direbbe: “Ehi allora mi trovo qui sulla curva degli errori, per ridurre ancora l’errore ci dobbiamo spostare verso sinistra ancora un po ed è quello che sto per fare.”
In effetti, uno spostamento a sinistra porterebbe una ulteriore riduzione dell’errore. L’algoritmo farebbe una nuova verifica, scoprendo che spostandosi ancora un po a sinistra sulla curva degli errori, l’errore continua a scendere, e così via in un processo iterativo che porterebbe ad individuare il punto della curva in cui l’errore è minimo.
In matematica questo procedimento è noto come “metodo del gradiente” (Gradient Descent). Fin qui abbiamo visto il funzionamento, seppur qualitativo e con molta approssimazione, di un sistema di Intelligenza Artificiale.
Adesso vediamo come si può trarre in inganno.
Dalla formazione alla confusione
Adesso che conosciamo il procedimento con cui un modello viene creato e addestrato, vediamo quali possono essere le cause che inducono il modello in errore.
Ovviamente, il sistema va in errore se lo manipoliamo, alterandone la calibrazione. Sarebbe un atto di sabotaggio e non è questo il nostro intento. Ciò che possiamo fare è sviluppare delle azioni di perturbazione che aumentano il grado di incertezza e quindi la percentuale di errore.
Fin qui ci siamo adoperati per minimizzare gli errori del sistema. Possiamo applicare la stessa procedura per massimizzare la funzione degli errori apportando delle modifiche all’immagine da analizzare. In altre parole, prendiamo un’immagine che il sistema ha classificato correttamente ed apportiamo delle modifiche subdole in modo da mandarlo in confusione.
Questo risultato si ottiene alterando l’immagine. Vengono implementate delle modifiche che una persona non percepisce ma che sono rilevati dall’algoritmo e che inducono ad un errore di classificazione.
Alcuni esempi pratici con Inception-V3
A questo punto possiamo esaminare alcuni esempi di analisi con Inception-V3 di Google. Il codice è stato sviluppato utilizzando il linguaggio di programmazione Python. Le immagini analizzate nell’esempio che segue sono state prese da Unsplash. Si tratta di sette immagini di candele che sono state classificate correttamente da Inception-v3.







Puoi seguire lo sviluppo dell’esercizio utilizzando il codice Python che abbiamo reso disponibile per il download su GitHub. Se Python e matematica non sono il tuo forte, non ti preoccupare, da qui in avanti questo articolo è libero da Python e formule matematiche!
Adesso abbiamo a disposizione sette immagini che sono tutte classificate correttamente. Quindi possiamo provare a confondere l’algoritmo utilizzando la tecnica descritta. Le immagini prodotte sono state modificate seguendo questa tecnica e si può vedere come l’algoritmo le ha classificate.
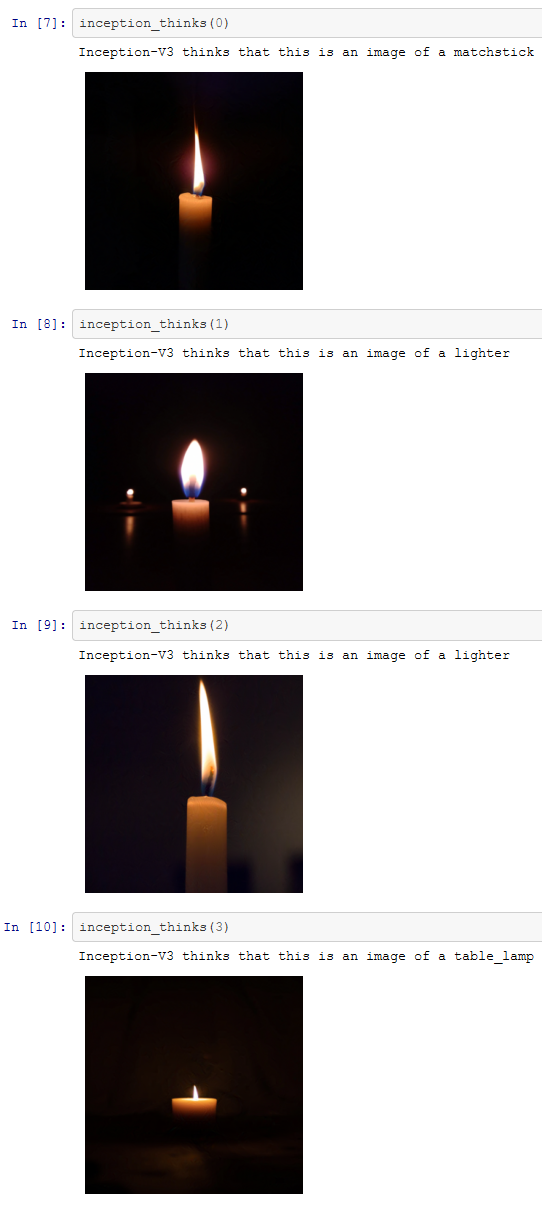
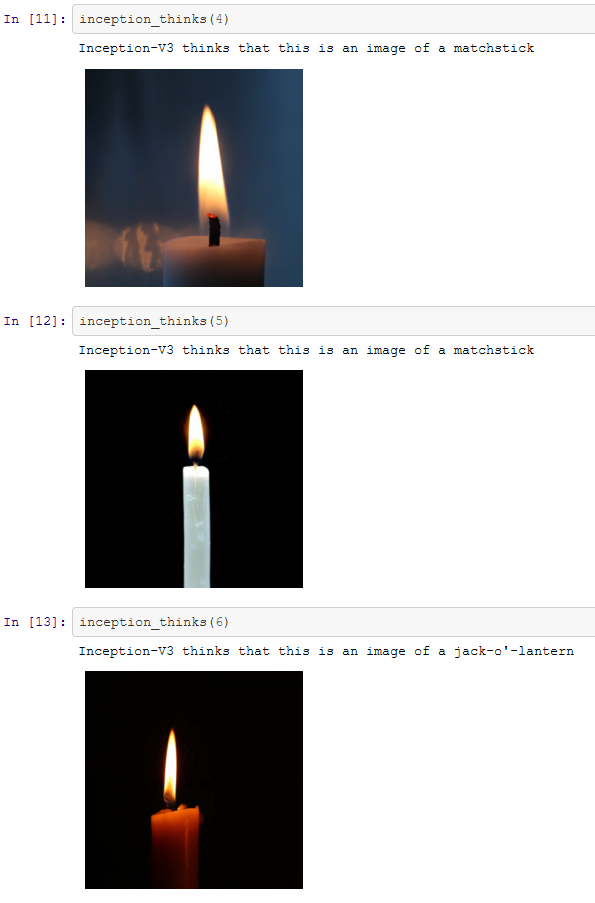
Pur non essendo estrema la differenza di classificazione, il sistema ha scambiato le candele per vari altri oggetti che hanno delle vaghe somiglianze con le immagini di partenza.
In buona sostanza, siamo riusciti nel nostro intento di confondere il sistema di I.A.
Tuttavia, il nostro tentativo è limitato rispetto ai risultati ottenuti dai ricercatori dell’MIT. Con questo esercizio siamo riusciti a confondere l’algoritmo, non ad ingannarlo. Adesso vediamo quest’altro aspetto.
Dalla confusione all’inganno
Nel paragrafo precedente siamo riusciti a confondere il sistema. Infatti gli errori di classificazione indotti non sono pilotati, ovvero non siamo riusciti a forzare la classificazione. Siamo partiti dall’immagine del gatto che è stata scambiata per guacamole.
Il termine tecnico che definisce un’azione manipolativa come questa è “creating a targeted adversary”. Azioni come queste sono sviluppate per ingannare l’algoritmo, prevedendo l’errore di classificazione dell’algoritmo.
Il processo seguito è simile a quello già descritto. In questo caso, la differenza sostanziale è che vogliamo minimizzare l’errore per ottenere una particolare classificazione dell’immagine.
https://creativecommons.org/licenses/by-sa/3.0,
via Wikimedia Commons
In questo caso l’obiettivo è minimizzare la funzione degli errori e fare in modo che, l’algoritmo classifichi il gatto come guacamole
Data la complessità dell’argomento, val la pena soffermarci qualitativamente sui vari passi che si affrontano per arrivare a questo risultato.
Si comincia con la foto del gatto, suggerendo che non si tratta di un gatto ma di guacamole.
L’I.A. risponde: “no, si tratta di un gatto.
Noi rispondiamo: “ma no guarda bene, questa è l’immagine di guacamole.
E l’algoritmo di I.A. ci risponde: “I miei calcoli mi dicono che con una probabilità del 97% si tratta di guacamole.”
Noi proseguiamo manipolando ancora l’immagine, iterando il processo di validazione. Sottoponendo di nuovo l’immagine per una nuova analisi da parte del nostro sistema di I.A. la risposta diventa: “I miei calcoli mi dicono che con una probabilità del 94% si tratta di guacamole.”
E il processo continua… fino a quando si arriva ad un punto in cui le modifiche all’immagine di partenza sono tali per cui il nostro sistema di I.A. si convince che si tratta di guacamole.
Il codice software per la trasformazione del gatto in guacamole è disponibile a questo Notebook Jupyter . I risultati dell’analisi e della classificazione di alcuni gatti sono riportati nelle immagini che seguono:


Si capisce che il procedimento seguito fin qui non è finalizzato alla trasformazione di gatti in guacamole, ma può essere impiegato per snaturare le determinazioni di analisi di qualsiasi genere. As esempio, le immagini che seguono mostrano com’è possibile far classificare una candela come un guanto (“mitten”)
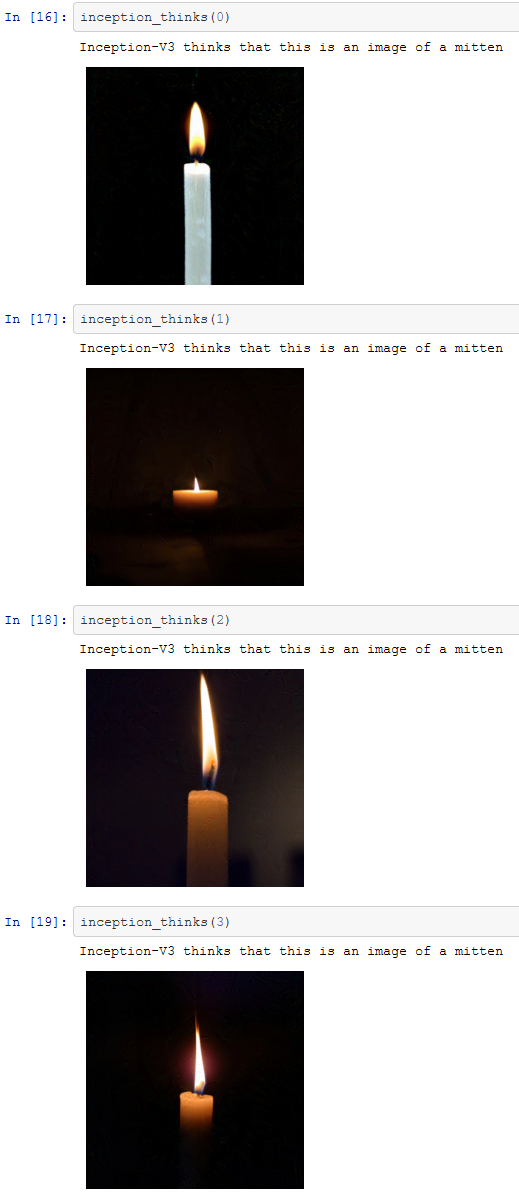
Il punto è questo: con poche righe di codice Python si possono creare delle immagini che l’I.A. non riesce a classificare correttamente. Non c’è bisogno di un supercomputer o di essere un esperto programmatore né tantomeno un data scientist. Il lavoro svolto per questo articolo è stato sviluppato su un normale laptop.
Si capisce quindi che un algoritmo di Intelligenza artificiale è imperfetto, può commettere degli errori e può essere tratto in inganno facilmente. Torniamo al grafico che abbiamo visto all’inizio del post dove l’errore umano è messo a confronto con l’errore degli algoritmi.
Una interpretazione di questo grafico potrebbe essere che il 2015 segna l’anno di svolta in cui il computer è divenuto più bravo dell’uomo nel riconoscimento delle immagini”. Una tale affermazione sarebbe superficiale se non si tenesse in considerazione quanto esposto fin qui in questo articolo. Dobbiamo spiegare i limiti della tecnologia. I dati dimostrano che non siamo ancora arrivati ad un livello di perfezione tale da poter essere paragonato con le capacità umane (almeno in questo campo).
Ulteriori esempi di manipolazione
Dalla pubblicazione dei dati da cui abbiamo tratto spunto per scrivere questo articolo, ci sono stati altri esprimenti simili come nel caso delle immagini di queste tartarughe realizzate con una stampante 3D, che sono un targeted adversarial attack all’I.A. di Inception-V3.

In questo esempio, relativo al gruppo di tartarughe dell’immagine precedente, abbiamo un altro caso di algoritmo I.A. che scambia la tartaruga per un fucile ed in alcuni casi non riesce proprio a distinguere l’immagine. Per ulteriori approfondimenti puoi veder questo video.
Non si limita al trattamento di immagini. Possiamo creare degli oggetti tridimensionali con l’obiettivo di confondere, o peggio ingannare algoritmi come questo.
Conclusioni
In questo articolo abbiamo esaminato il caso specifico di manipolazione dell’I.A. con l’obiettivo di modificare la classificazione di una immagine. S’è visto che non solo la manipolazione delle immagini può confondere l’I.A. ma lo può anche modificare. Per correttezza e completezza d’informazione, dobbiamo aggiungere che non tutte le applicazioni di I.A. sono vulnerabili alla stessa maniera.
Il mondo dell’I.A. è affascinante e l’I.A. sta modificando il nostro modo di vivere. Sarebbe sbagliato pensare che l’intelligenza artificiale dei computer provocherà un’apocalisse. Allo stesso tempo dobbiamo preoccuparci delle azioni di programmatori come quelle esaminate in questo articolo.
Ci sono implicazioni morali ed etiche di primo piano che vanno affrontate e regolamentate a garanzia della tutela della collettività e nell’interesse di tutti.

- L’Intelligenza Artificiale e Riconoscimento delle Immagini - July 26, 2021