






In this post, we will cover AI from a critical perspective, some may say one that is cynical or pessimistic. We are going to look at when AI makes mistakes, and examine some research where experts have gone out of their way to fool complex image recognition systems.
This blog post compliments a talk, “Resisting the AI Apocalypse”, presented at Brighton SEO in Summer 2021. The following additional resources are also available:
- The Slides for the talk
- Jupyter notebooks demonstrating a step by step journey towards tricking an AI and an example of only tricking an AI
- A GitHub repo containing the above notebooks and their associated resources
When AI goes wrong
Computers are playing a larger and larger role in our lives. The software algorithms that power Search Engines, social media platforms and even HR systems are becoming ever more sophisticated, but, as yet are not perfect, and hence are capable of error.
@MinutelyHipster highlights two search results ( or rather featured snippet within search results ) One is for the search world record Rubik’s cube 1×1, the other search asks “who invented running”. Both questions trigger interesting responses.
- The world record apparently was completed in an impressive 8 minutes and 59 seconds.
- It was suggested that Thomas Running invented running when he tried to walk twice at the same time.
These are just two light-hearted examples of things going wrong. I thought they were quite funny, but when AI goes wrong, it isn’t always just a humorous example. Sometimes it can have serious effects on the way our lives work. Sometimes AI has been used in recruitment and hiring processes, allowing an algorithm to influence who should be the successful candidate.
While AI doesn’t quite have a mind of it’s own, sometimes it acts like it does.
Decisions made by AI systems haven’t always reflected the values individuals and organisations may want. This subtle consequence of delegating decisions to machines is not limited to the recruitment example above. Even something as seemingly straightforward as deciding how to crop a photo can be too much for AI to achieve compassionately.
It does have to be said, AI in some cases can perform rather impressively, so much so, that it can be easy to fall into a trap of confirmation bias and assume it does a great many things just as well as showcased examples. However, as we have seen, AI has imperfections. AI is prone to Errors.
In the next part, we will look at a case study that demonstrates quite how well AI can be tricked in situations where a human mind may not.
Can AI beat humans at Image Recognition? A case study in breaking “better than human” AI.
While AI has many applications, this case study will focus on Image Recognition. Extensive research has been performed on the Inception-V3 Image Recognition Algorithm from Google. Inception-V3 was one of the first algorithms that achieved a “better than human” error rate in the ImageNet image recognition challenge.
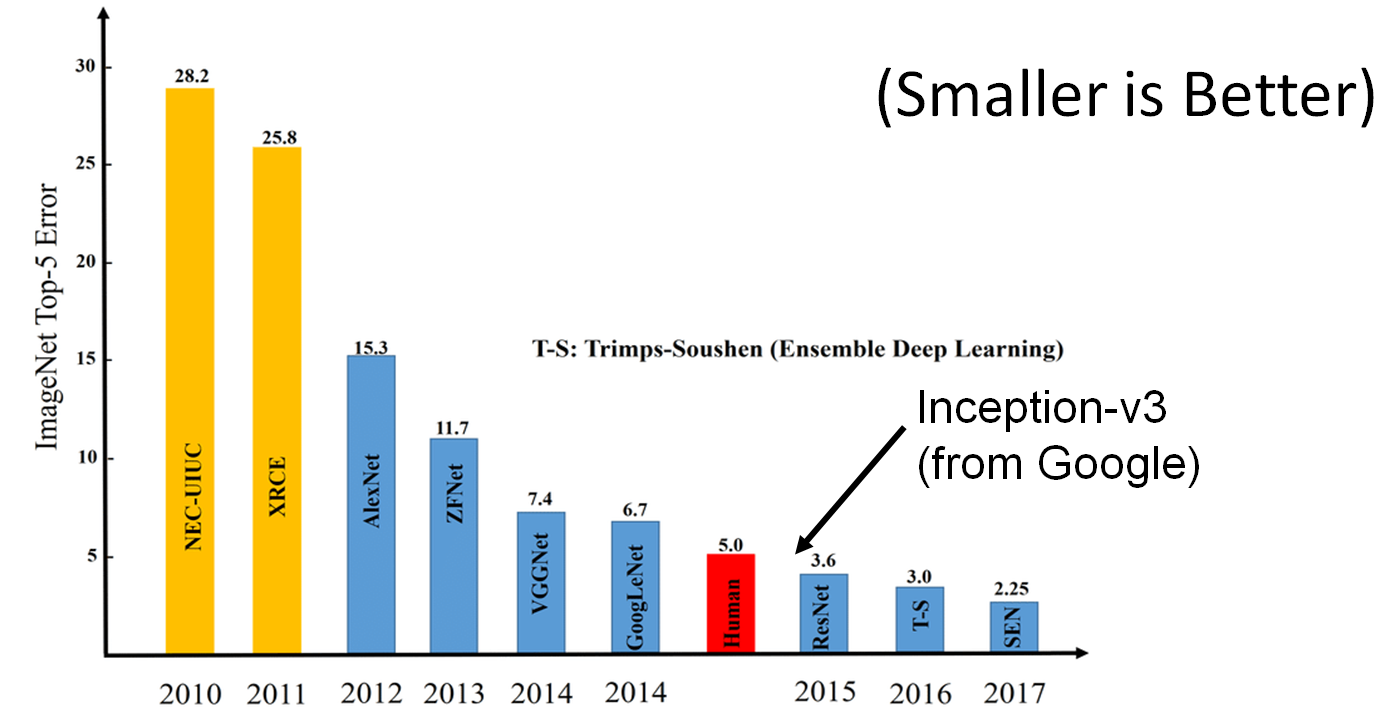
AI researchers have made huge progress in the field of Image Recognition in recent years. The bar chart above attempts to capture this progress. The chart shows the quantity of errors different “state of the art” AI image recognition algorithms made in a recognised image recognition competition. The rate of progress is shocking, The graph starts in 2010, with a substantial error rate, especially when compared to the human rate of error (shown in this graph as a red bar). Within the graph, we can clearly see 2012 represents a huge leap forward in the performance of image recognition AI, amd afterwards performance consistently improving until 2014 when the AI error rate begins to become comparable to the error rate of humans.
In 2015, we see an incredible milestone for the field of artificial intelligence. In 2015, ResNet and Google’s Inception-v3 AI outperform humans in this image recognition competition. A huge achievement and landmark in software development. (ResNet narrowly beat Inception in 2015, hence them taking the “podium position” on the graph for 2015).
Does this mean that in 2015 AI “beats” humans in terms of image recognition? Not necessarily. While AI has a demonstrably lower error rate, we’ve already seen that AI makes different sorts of mistakes to humans, and as we shall see, those mistakes can be encouraged…
First, let’s be clear what we mean by an Image Recognition AI. Image recognition is an old practice in AI. In fact, in 1966 some academic institutions viewed building an Image Recognition AI as a suitable summer project for their students to work on. Modern Image Recognition has of course come a long way since then, and is far smarter, with far greater abilities. The ImageNet test focuses on Classification – that is, passing an Image Classifier AI an image of something, and then comparing the output of the AI with the name of the entity in the image, as shown on the example below:


Licence: https://creativecommons.org/licenses/by-sa/3.0/deed.en
“This is Guacamole”
At this point the test may feel simple in terms of human perception – Guacamole and Cat are such different things that no-one, including AI algorithms could get confused between them. Or could they?
This seems a good point to introduce some research from a team at MIT who managed to trick the Google Inception-V3 algorithm into thinking that an image of a cat.. was actually an image of Guacamole!
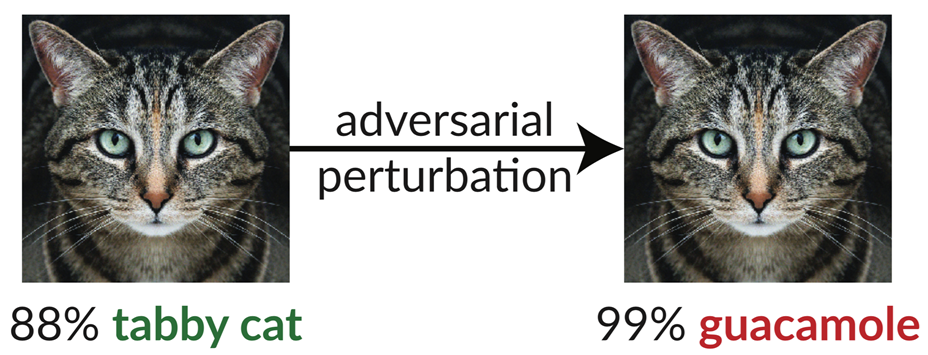
How? They took an image of a cat, like the one seen on the left, which Inception V3 could successfully recognize as a tabby cat. Then, they applied a process called “adversarial perturbation” to convert it into the image on the right. To humans, the image still looks pretty much the same as the one on the left, however, to the AI, this cat is allegedly 99% guacamole. The term “adversarial perturbation” is a bit of a mouthful. In reality all it really means is they took the original image and edited the pixels in the most minute ways possible, so the changes were not perceptible to the human eye, but in ways that were going to trick the AI into making a mistake.
Before we go into more details as to how they tricked the AI, it’s first necessary to gain an awareness of how AI works.
A quick introduction on how AI works
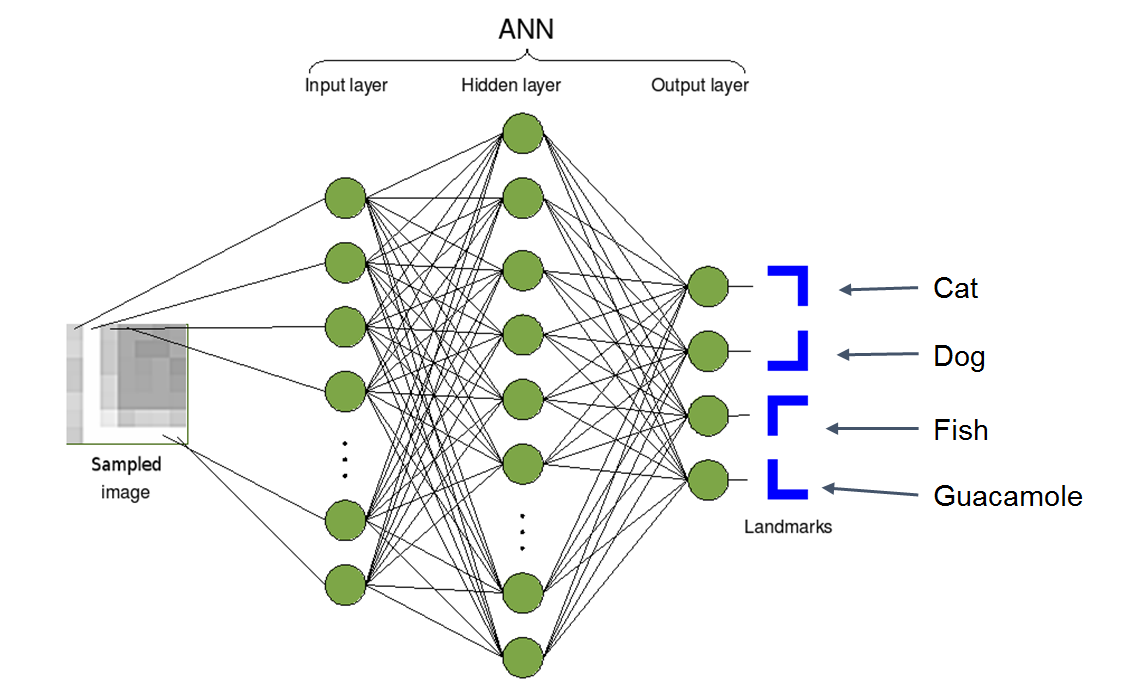
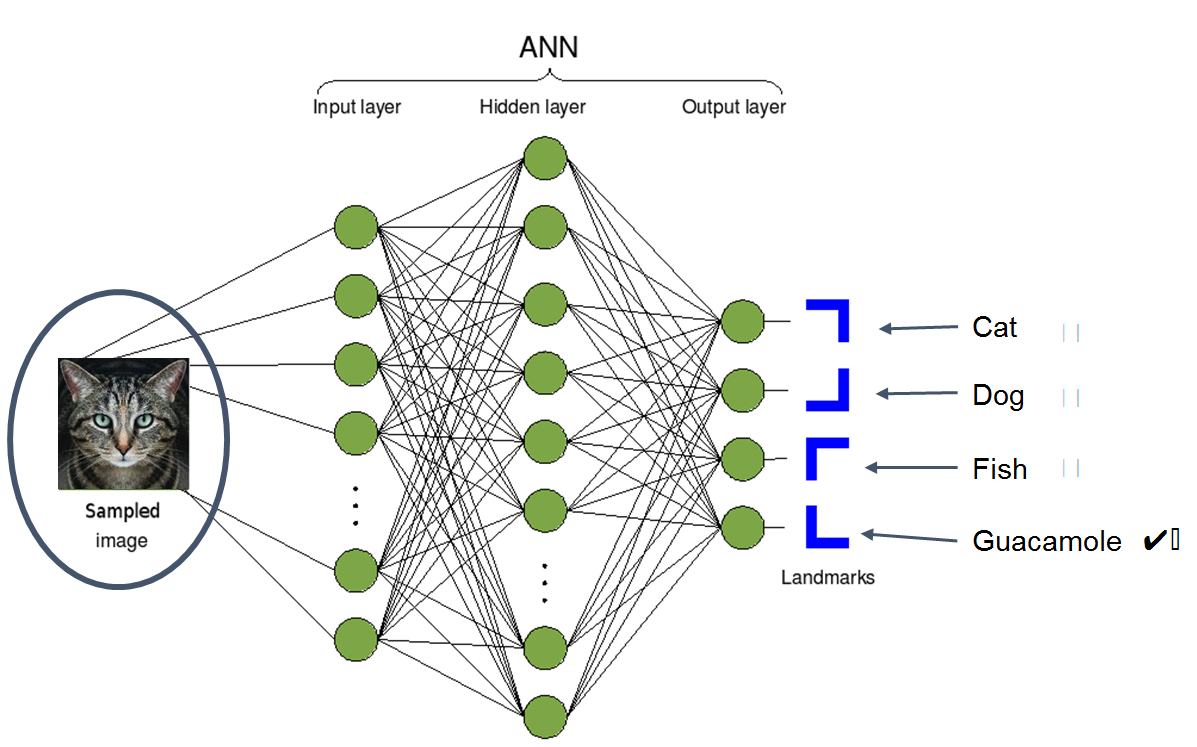
The diagram below shows a high level overview of how an Image Recognition Algorithm might work. On the left, the AI is taking in a sampled image. In the middle, it’s doing a bit of math on the image that’s being provided. And on the right, it is going to try and draw a conclusion as to what that image is. It could decide the image is of a cat, a dog, a fish, or a guacamole in this case.
<https://creativecommons.org/licenses/by-sa/3.0>,
via Wikimedia Commons
So image goes in, math happens, a classification comes out. The image above represents a neural network, which is essentially a term computer scientists and mathematicians use to describe a big mesh of simple formulas. However, this simple diagram lacks is the explanation of how something so simple gets to be smart. The answer is that each of the simple formulas in the mesh needs to be tuned so that it can serve it’s purpose for the greater good.
This process of taking a pretty useless, untuned AI, and tuning it to become useful is called Training. In order to make an AI suitable for purpose, it takes a lot of training. In practice, the training is performed using some lovely mathematics. However, we are going to take a maths free approach and describe training at a conceptual, rather than mathematical level.
A key input into training an AI training is example data, a great deal of example data. During training, maths is applied to the AI to do what is known as “minimising the error function”.

The error function could be thought of as a measure of the “wrongness” of the AI. Training involves using lots of inputs and lots of maths to “Minimise” the “Error Function”, or in other words, to reduce the wrongness of the AI. The goal of training and improving an AI is to make the error as little as possible. In this case, getting your AI to the bottom of the graph.
By looking at this graph, the problem may seem easy, because we can see where the bottom of the error function is, and think, “Aha, right, yes. Move the dot to that position where the arrow is”. Unfortunately, when tuning an AI, the error function is often far more complex than our visualisation and linked to the training of the AI. Unfortunately, one cannot just simply provide a computer a graph of their AI’s error functiona and instruct it find the bottom. What you actually need to do is slowly change the settings of your AI to reduce the error bit by bit.
The training process does know where it is on the curve, and also which direction down is. So in this case, what might have happened is you might have an AI with a certain amount of error, and we would train it and ask it to improve itself.
If an AI could describe it’s journey of Error minimisation, it might say “Hm, I’m here. And if I move left, that’s the way to move downwards on the curve, so I’m going to do that.”. This step results in the AI getting a little better. Its error is slightly reduced. However, more work can be done to improve the AI. The process continues, step by step, the AI moving down the curve. That is how AIs are trained. The reason they are thought of as “Intelligent” is because training an AI results in a process of self-tuning that makes the algorithm less prone to error. At most stages in this process, the AI will have a certain amount of error will very, very slowly, bit by bit, try to reduce that error by changing their settings to make more accurate calculations or classifications.
The maths form of this process is known as “Gradient Descent”, and works, more or less along the lines above, only with more complex calculations. Now we’ve seen how AI’s can learn, let’s move onto how they can be fooled.
From Training to Confusing an AI.
Having seen how we can train an AI to get better, let’s now look at how we can create an image which causes an AI to make a mistake.
A trap here is to think we can simply do the opposite to the training process – however, that’s not really fair, as simply detuning an AI is somewhat equivalent to smashing it with a hammer. The operation may disturb the operation of an AI, but it’s not confusing or tricking it.
While we can’t break the AI, we can still aim to increase the rate of error by maximising, rather than minimising the error function.
As smashing the AI is outside of scope, we are left with the input.
You may recall that to make an AI smarter, the functions in the neural net were tuned by minimising the error function. We can apply a similar technique to maximise the error function by gradually adjusting the input image, slowly, step by step, attempting to increase the rate of error with each step. Put another way, we take an image that and AI classifies correctly, and subtly mess with said image until the AI becomes confused.
In this case, we’re not manipulating an AI, but rather we’re manipulating an image. As we start with an image that has successfully classified by an AI, it stands to reason that when it gets sent through the AI, it’s not going to have a lot of error in its classification.
The key to minimising the changes a human perceives, but maximising the changes an AI detects, is to manipulate the pixels of an image succinctly, very carefully, in a way which is going to maximize the error of its classification.
At this point, we can break out our Python Notebook ( these examples were coded in Jupyter ), and try to find some images to use with Inception V3.
Some may decide to use a Google Image Search – our images come from unsplash. For our chosen images, these seven candles are classified correctly by Inception-v3.







If you are interested in the code for following along with this, the python notebook becomes a really useful companion. If Python isn’t your thing, just read on – we will try to keep this post a maths and Python free zone!
We now have seven valid images that classify correctly. This means we can to try use the error rate maximisation process described above to confuse the AI. The Images produced by this process are shown below.
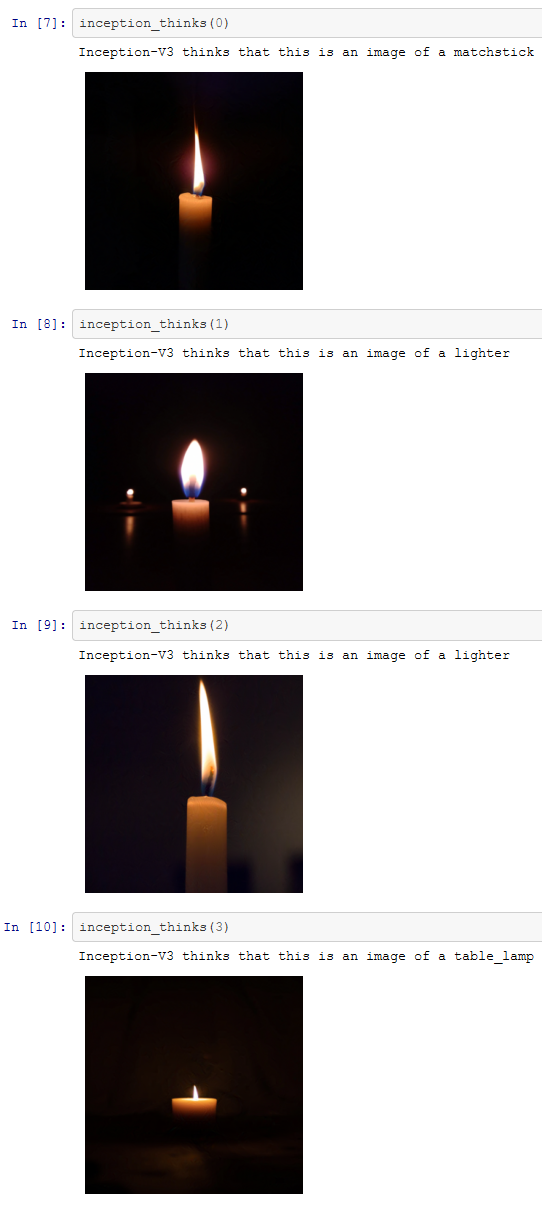
While the misclassification is not especially extreme, we have succeeded. Inception seems to have managed to identify the altered images as objects that are sort of similar to candles. However, as we progress it will become apparent we can force Inception to make far more serious errors.
None the less, we have successfully managed to confuse the AI!
However, this still falls short of what the researchers managed to achieve. While we have “Messed up” the Image recognition by confusing the AI, we haven’t really deceived it. Let’s move onto that now.
From AI confusion to AI deception.
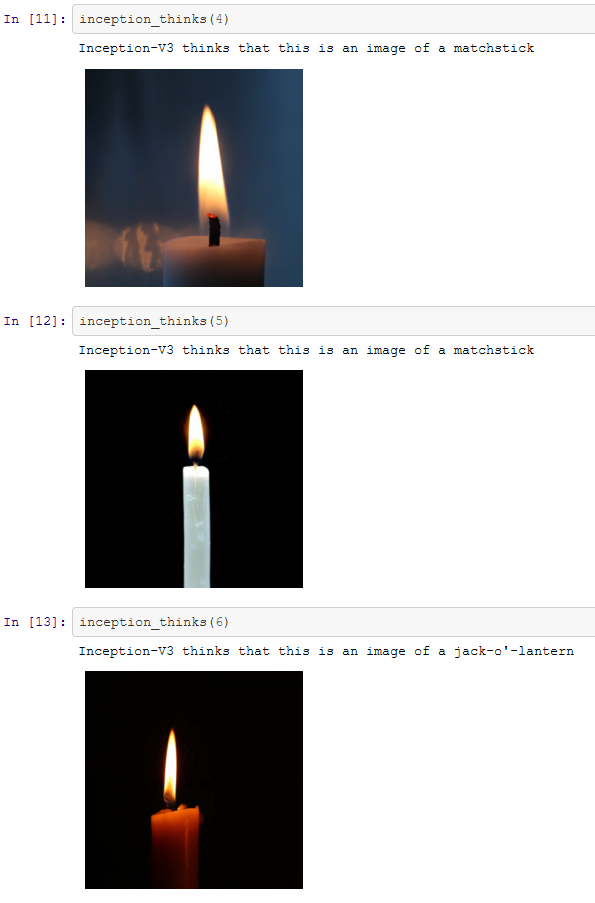
While “Confusing” an AI was entertaining, we haven’t as yet succeeded in tricking the AI into misclassifying an image as an object of our choice. As we saw earlier with the cat-guacamole example, the researchers didn’t just confuse an AI into getting a classification wrong, they actually tricked an AI into classifying an image as a very specific thing. The example we highlighted was taking an image of a cat and making the AI misclassify this as guacamole.
The technical term for tricking an AI into misclassifying an image as one of your choice is called “creating a targeted adversary”. To emphasise, this is creating something to cause the AI to make a mistake, but you want the mistake to be a very specific mistake.
The process for creating a targeted adversary is similar to the process of confusing the AI described above. Once again, the input image is manipulated, however, instead of just making the AI wrong by maximising the error function a slightly different approach is taken. Instead of just maximising the error function, we need to minimize the error function for the wrong classification.
https://creativecommons.org/licenses/by-sa/3.0,
via Wikimedia Commons
In this case, it we are minimising the error function again, but the amount of error for the cat picture not looking like guacamole, in the eyes of the AI at least
Once again, the journey is performed by taking lots of tiny steps. The journey can be thought of as an ongoing conversation between our manipulated image and the AI.
We start with our picture of a cat, pass it into the AI, and tell it “That’s not a cat, that’s a guacamole”.
The AI responds “No, I’m certain that’s a cat.”.
We say, “No, you’re wrong. It’s a guacamole.”.
The AI responds “I’m 97% sure that’s not Guacomole”
We think “AHA – lets tweak the image and ask the AI again”…
We do this, repeat, the AI responds “I’m 94% sure that’s not Guacomole”
And the process continues…
In a similar process to last time, we edit the pixels making up the image. This results in the AI interpreting the image as being slightly more like guacamole. The process repeats, and after many iterations and edits to the image, as far as the AI is concerned… We have successfully converted the cat into guacamole, just like the researchers did.
The code for AI Cat Guacamolification can be found in this Jupyter notebook, the results of which are shown below:


The process isn’t limited to tricking AI into thinking cats are Guacamole. With a few lines of python, we could, for example, take the pictures of candles used in the above section and tweak them. Perhaps we could train the AI to think the candles were mittens?
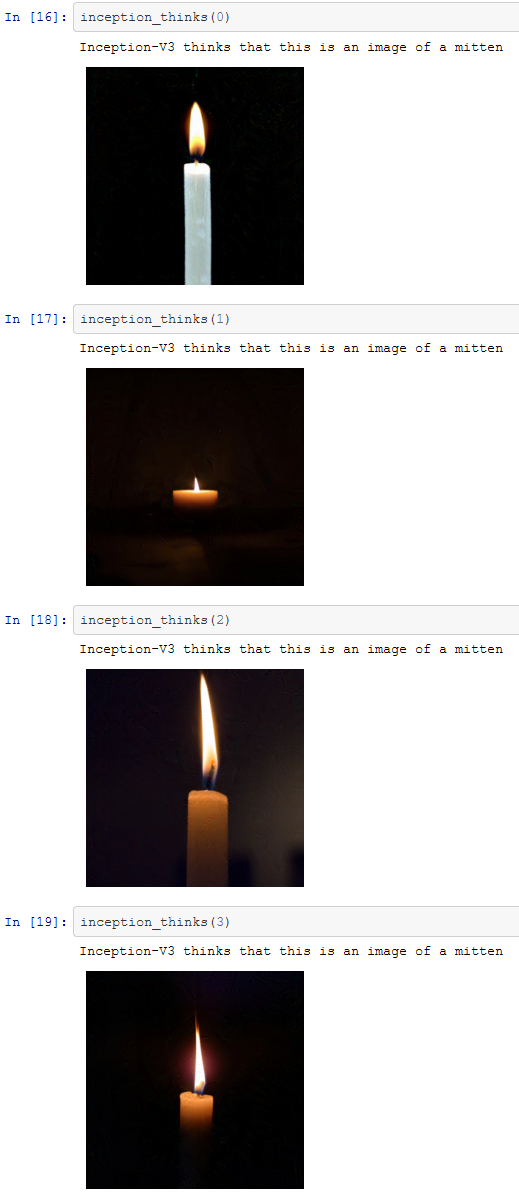
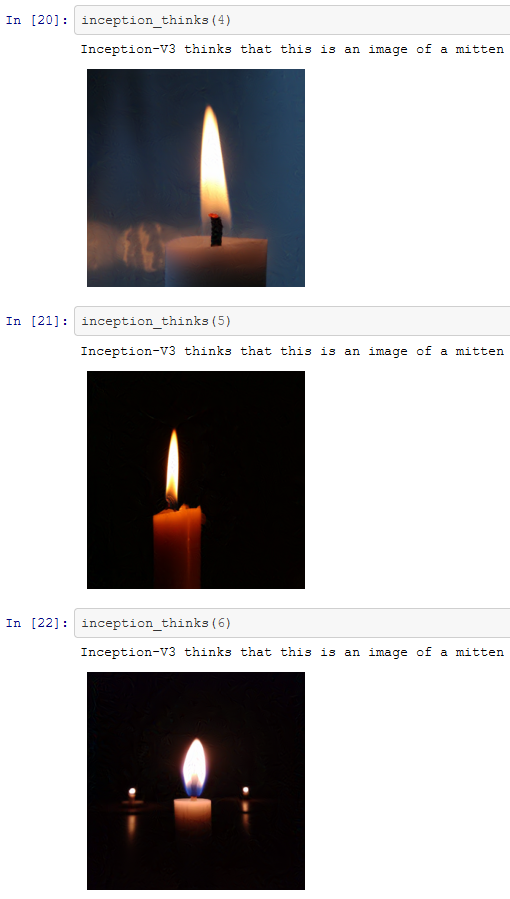
Here’s the thing. With just a few lines of code, we can easily make images that AI cannot classify. You don’t need to have a supercomputer or be a bleeding edge expert in the field to do this. The work for this blog post was performed by copying some images onto a laptop, and running some code. The result – images, produced on a laptop that confused Inception-v3 AI, and some that tricked the AI into making mistakes in a targeted way.
In doing so, we have demonstrated that not only is artificial intelligence fallible, but it can be tricked. Let’s return to the graph highlighted above which compares AI error rates to humans.
One interpretation of this graph could be that “2015 was the year that AI became better than humans at recognizing images”. This conclusion would miss an important subtly. If we look at the examples of how we have been able to confuse, and trick AI, is it fair to suggest that AI is better than humans at classifying images?
To suggest this would be to overlook an important subtly in the graph. The graph isn’t intended to encompass or benchmark human image recognition. Instead, the graph demonstrates that AI became better than humans at a specific measure used by this specific competition run by ImageNet.
The progress in AI and image recognition to date has been truly awesome. However, there are still many flaws these AIs have that humans do not fall prey to. 2015 was a fantastic year of achievement for the field of computer science and AI research, but the moment when AI becomes better than humans at image recognition? We aren’t there just yet.
Taking deceiving AI one step further
Since the paper this blog is based on was released, researchers have a taken this concept further – and applied it to real world objects. What you can see here is researchers have actually 3D printed a turtle, which is a targeted adversarial attack to the Inception-v3 AI.

So in this case, you actually have what appears to be a turtle. You have an AI trying to recognise it, and failing. The AI is classifying that what seems to the human eye to be a turtle as a rifle. In two cases, the AI is not managing to classify it at all. You can watch a video of this working in practice here.
So it’s not just images anymore. We can make 3D objects in the real world, which are going to confuse AI into drawing the wrong conclusions about what they are.
Conclusion
The case study above focuses on just one form of AI. We shouldn’t assume that all forms of AI suffer from the same vulnerability.
Working with AI and machine learning is actually really fun. However, fun though it is, we need to consider the ethical impacts of our actions. AI probably won’t ruin our lives – at least in the sense of an apocalyptic meltdown where machines take over the earth, but programmers might.
Most people do not have control over how AI works, but AI does have control over important parts of our lives. AI can control things like who deserves to get a job, who deserves to get a mortgage, or even who deserves to enter a country. And if AI is capable of making mistakes, or being tricked, to what degree can we trust their implementation for these purposes?
Maybe it stands to reason that we need to be a little more critical of AI, especially if we are going to be using it for so many important applications.

Aaron graduated from Aston University in the field of Computer Science and Mathematics. Aaron has a passion for ongoing professional development. He and can often be found engaged in or contributing to tech organisations and tech initiatives in the region.
- Hackers Guide to Resisting the AI Apocalypse - July 20, 2021
Thanks Aaron, really great article.
July 23, 2021 at 9:39 amDetective Del Spooner : Human beings have dreams. Even dogs have dreams, but not you, you are just a machine. An imitation of life. Can a robot write a symphony? Can a robot turn a… canvas into a beautiful masterpiece?
Sonny : Can you?
I, Robot (2004)
Can humans be fooled with an image in the same way? Illusions like old lady – young lady show that carefully crafted images can do so. "Carefully crafted" is the key point here and it is not related to AI or human incapability to distinguish images. It seems like a flaw of an image recognition problem or even an entire classification problem.
In real world scenarios the number of attempts to trick a system is usually very limited. This reduces the probability of successful attacks. Be it AI or human systems.
A cup of awful coffee, a cold, a lack of sleep might be the reasons why HR didn’t like you and you didn’t get your dream job. AI don’t sleep, drink or get sick. Every system that is built with a lack of sense might lead to a disaster and should be trusted accordingly.
July 26, 2021 at 9:09 amHi Alex,
Thanks for the thoughts. They don’t seem too far from the point of the article. AI is one of many tools for solving problems. Like all tools, it has it’s strengths and weaknesses. One thing to consider in your recruitment example – human beings have had many years to develop systems of checks and balances that limit the damage to an organisation that an awful cup of coffee can do. How many key decision makers understand the strengths and weaknesses of AI to the same level?
Steve
July 26, 2021 at 10:30 am