






Un recente studio di Incapsula sull’attività dei Bot ha aiutato il sottoscritto a farsi una idea e capire perché un’indicizzazione intelligente sia molto meglio di un’indicizzazione rapida. Incapsula ha lavorato su uno studio che aggiorna ogni anno per molti anni ormai. Novizi e SEO esperti potrebbero essere preoccupati nello scoprire che solo la metà del traffico internet in arrivo nel web è di persone fisiche.
Questo post esamina alcune delle possibili conseguenze di una corsa all’indicizzazione, il suo impatto sulla qualità dell’indice e a tentativi di alcuni spammer di ostacolare i bot. Infine oggi vi svelerò una tecnica di link building davvero stupida che abbiamo scoperto con estrema facilità.
Bot Buoni e Bot Cattivi

Incapsula ha documentato che la maggior parte del traffico mondiale di bot arriva da 35 spider “buoni” (incluso Majestic) ed una serie di bot maligni di cui oggi non parleremo. Tuttavia si può notare che alcuni firewall poco evoluti bloccano le attività dei bot filtrandoli utilizando gli user-agents, lasciando i loro clienti senza alternative. Questo è poco raccomandato. Ecco l’impatto relativo di ogni bot sulla banda totale di Internet.
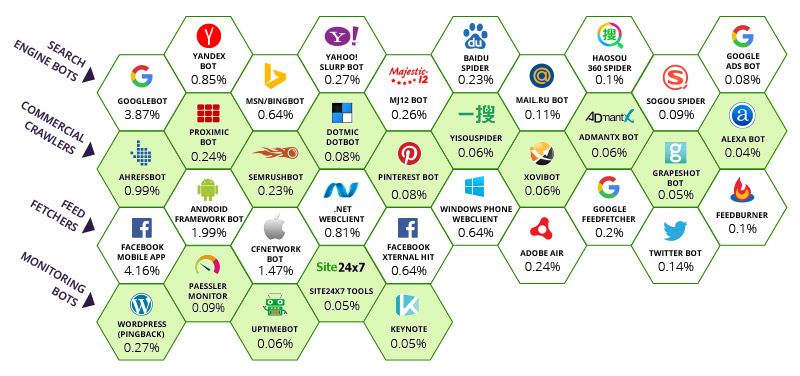
I numeri al di sotto di ogni bot rappresentano la percentuale di visite attribuite, per tutte le pagina tracciate, ad ogni tipo di bot. L’app mobile di Facebook è il leader con il 4.16% di banda totale consumata. Google assorbe il 3.87% della banda totale. Il numero complessivo è molto più grande se sommiamo la banda occupata da tutti gli altri bot sotto il controllo diretto di Google: tutto sommato questo è un numero accettabile visto che Google con Facebook sono fondamentali nella gestione di un ordine precostituito senza il quale il web non sarebbe navigabile, diventando un sistema frammentato e caotico. Questo è comune a tutta la prima riga superiore inerente ai motori di ricerca e sebbene Majestic è grato a Incapsula per essere stata inserita nella prima riga come motore di ricerca, allo stesso tempo notiamo la presenza di alcuni nostri pari sulla seconda riga dove Majestic avrebbe trovato una naturale collocazione.
Essendo uno dei 10 top crawlers, secondo la tabella di cui sopra, Majestic ha la responsabilità di sapere quando deve SMETTERE di indicizzare e quando riprendere l’attività di spidering. Il dibattito nel mondo SEO sull’opportunità di censire “TUTTI” i link, o perlopiù, quanti più possibili. Ma questo approccio pone un quesito al limite del paradosso: quale deve essere il limite quando si indicizza un web infinito?
L’infinità del Web
Le recenti vicissitudini tra Majestic e la Stazione Spaziale Internazionale non sono state solo una trovata pubblicitaria. È stato fatto anche per mettere in risalto la natura infinita di Internet. Questa infinità ha serie ripercussioni sui software SEO ed il loro uso. Un paio di mesi fa Majestic ha rimosso miliardi pagine web dal proprio indice, creando molto scalpore al tempo per alcuni che utilizzavano la versione “www” di un dominio (che, tecnicamente, è una variazione a livello di sottodominio). Queste pagine erano, appunto, tutte pagine di sottodomini create in tempo reale (automaticamente). La piramide di Lego vi può aiutare a visualizzare meglio il dilemma:

Ora, immaginate che questa piramide rappresenti tutti i sottodomini presenti in Internet, dove quelli in cima hanno un Trust Flow di 90-100 e quelli alla base un TF di 0 e anzi, Majestic stava trovando che il Trust Flow dei sottodomini alla base era molto meno di 0. Non avevano altri link in entrata se non dal loro dominio principale. Gli algoritmi di Trust Flow di Majestic riproducono una struttura simile ad una piramide. Pertanto, più larga è la base formata da spam, più alto sarà il Trust Flow di qualsiasi cosa migliore, anche di poco, dello spam; e poiché questo è un problema infinito, un crawler non può risolverlo solo indicizzando di più, ma questo farebbe apparire il gradino sopra migliore del precedente inferiore, più di quanto esso sia in realtà, e comunque non avremmo nulla che si avvicini a “tutti” i link perché qualsiasi numero diviso per infinito non darà mai una percentuale significativa. Majestic potrebbe avere server farm enormi quanto un campo di calcio ma non risolverebbe il problema. Invece, Majestic ha deciso di eliminare le ultime due righe della piramide, che nella rappresentazione superiore sono più della metà dei dati presenti! (36 blocchi su 70 = 55%). Questi 36 blocchi rappresentano perlopiù pagine che nessun essere umano ha mai visto e che nessun motore di ricerca con un minimo di dignità indicizzerà mai.
L’effetto voluto era quello di ristrutturare la piramide. Da un giorno all’altro siti che si trovavano sul terzo scalino con una scala da 1 a 100 si sono ritrovati all’ultima riga. Potete immaginare il panico che ne seguì nelle comunità dei domini e lo potete scorgere tra i commenti di questo thread.
Questo non è l’unico modo per creare un web infinito. Majestic.com stesso (e qualsiasi motore di ricerca) crea loop potenzialmente infiniti partendo dal suo funzionamento di base. Potete scrivere qualsiasi set di caratteri in Majestic.com e il sistema cercherà di interpretare i risultati. Di conseguenza questo crea SERP (Search Engine Result Pages) che a loro volta creano link. Questi link si collegano, attraverso link, a pagine che già esistono creando così un loop chiuso, ma la URL di ricerca in sé può essere infinita per natura. Majestic (e Google) aiutano altri motori di ricerca ad individuare questi loop ed entrambi ricorrono all’utilizzo dei loro file Robots.txt per comunicare che è meglio non sprecare risorse preziose per indicizzare URL infinite.
E gli spammer duplicano il problema…
L’inizio di questo post prometteva la denuncia di un network di link building. Solitamente non faccio queste cose, ma questa tecnica all’inizio era molto perniciosa verso gli MJ12Bot. Ho iniziato il post scrivendo che gli user-agents sono facoltativi. Majestic sceglie di identificarsi. Se NON vuoi che Majestic indicizzi il tuo sito, utilizza Robots.txt, fornendo istruzioni precise. NON tentare — come ha fatto questa tecnica — di re-indirizzare (con un 301) il bot di Majestic verso la sua home page. L’effetto è un interessante allert via email, che mi ha riportato un enorme afflusso di link verso Majestic.com:
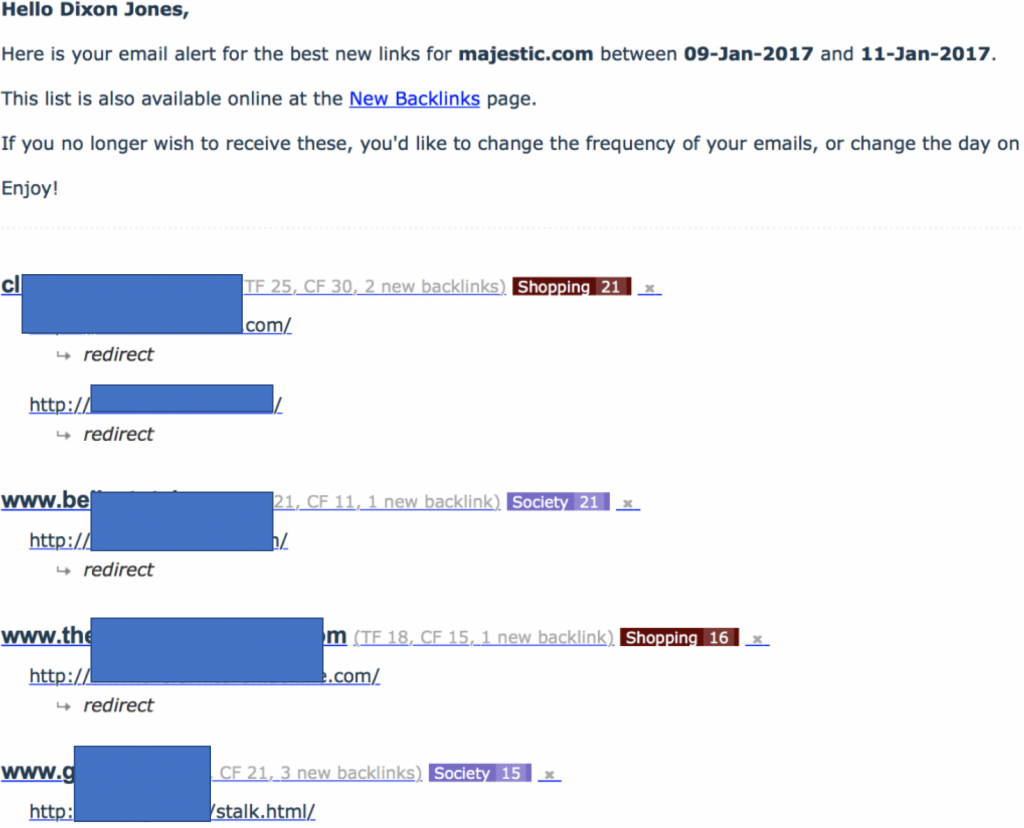
Da notare come tutti i link nuovi verso Majestic.com erano, a quanto pare, re-indirizzamenti da questi siti. Questo è stato da subito un allarme rosso. L’analisi di questi siti ha evidenziato la natura dei siti e ci siamo resi conto che erano delle link farm che però NON stavano linkando verso Majestic. Questo significava che molto probabilmente stavano cercando di fare cloaking nei confronti del nostro MJ12Bot (ovvero cercavano di nascondere contenuti dal nostro bot). Ero molto divertito dal fatto che così facendo il nuovo network aveva iniziato ad usare filename come “stalk.html!. Guardando queste pagine con un browser normale si vedevano più o meno così:
User-Agents sono facoltativi
L’ultima cosa rimasta da fare per tentare di capire cosa stesse succedendo era utilizzare strumenti SEO di terze parti per verificare che questo network stesse effettuando re-indirizzamenti 301 basati sullo user-agent. Se cercate “HTTP Header Checker” potete farlo voi stessi. Ancora più utile è il SEOBook’s Header Checker o anche il tool di Screaming Frog, entrambi vi permettono di cambiare user-agent con un menù a tendina. Detto in parole povere — questi siti utilizzavano tecniche di cloaking. Dovesse arrivare un GoogleBot, o anche una persona fisica, vedrebbe quello vedete sopra. Un MJ12Bot vedrebbe il sito di Majestic attraverso un 301 redirect.
Il Ritorno alla Responsabilità dei Crawler
Questo network presenta una grande sfida in quanto costringe il crawler a verificare due indirizzi IP invece di uno solo. In questo caso potrebbe essere poco rilevante visto che un sito è spam e l’altro è Majestic, ma mette in risalto il fatto che i redirect 301 siano approssimativi. Comportano un carico non indifferente di attività in Internet. Un modo più efficiente di re-indirizzare sarebbe usare alias dei domini. Ma questo causerebbe altri problemi per i motori di ricerca, visto che il dominio canonico (quello preferito) non può essere identificato con la sola tabella dns.
Pertanto con web infiniti e potenziali carichi causati da re-indirizzamenti, uniti ad una serie smisurata di procedure messe in campo per ostacolare l’operato dei crawler, diventa illogico e poco pratico continuare a indicizzare siti spam…anche se cercassimo di separare i link spam da quelli buoni. Un metodo molto più efficiente è raccogliere i dati di un sito per vedere da quali domini provengono i link e poi proseguire per la propria strada. Il trucco sta tutto nel NON ripescare lo spam e tutto quello che ne è affiliato, che si trovi ad un livello dove sono presenti un numero indefinito di pagine o a llivello di sottodominio con infiniti sottodomini oppure a livello di pagine di di risultati di ricerca, con infiniti risultati o re-indirizzamenti.
Per questo i crawler che possono indicizzare in modo intelligente sono capaci di ridurre di molto il livello di attività internet rispetto ai crawler che indicizzano rapidamente. Indicizzare intelligentemente funziona se un crawler è capace di comprendere uno qualunque o tutti questi segnali:
- È una pagina importante?
- Viene aggiornata oppure è statica?
- È generata automaticamente?
- È spam?
Majestic eccelle nel riconoscimento del primo e ultimo segnale dell’elenco precedente. Le metriche di flusso danno il vantaggio a Majestic sugli altri bot e mi riferisco in particolar modo a BingBot. Sono sicuro che BingBot sia più aggressivo di Majestic ma non sono sicuro che è realmente necessario esserlo. Magari Bing non ragiona utilizzando delle metriche pure come il Trust Flow o il PageRank (sì, lo usano ancora) per semplificare il processo di indicizzazione, ma non credo stiano scoprendo molte più pagine andando a circa il 250% della velocità di MJ12Bot. Lo stesso discorso vale per i nostri pari della seconda riga del grafico di Incapsula.
Il miglior approccio — almeno per Majestic — è indicizzare quanto serve per riuscire a trovare i domini principali che linkano ad un sito e poi mostrare abbastanza backlink provenienti da quel sito così che i nostri utenti possano facilmente identificare la natura del criterio di backlinking. Gli utenti possono vederlo in modo semplice e diretto nella barra dei referring domains. Inserite il vostro dominio e ordinate per backlink in ordine decrescente e potrete vedere il totale di backlink per dominio, con cui fare altre analisi dettagliate. Ecco rappresentato il sito di Majestic.com:
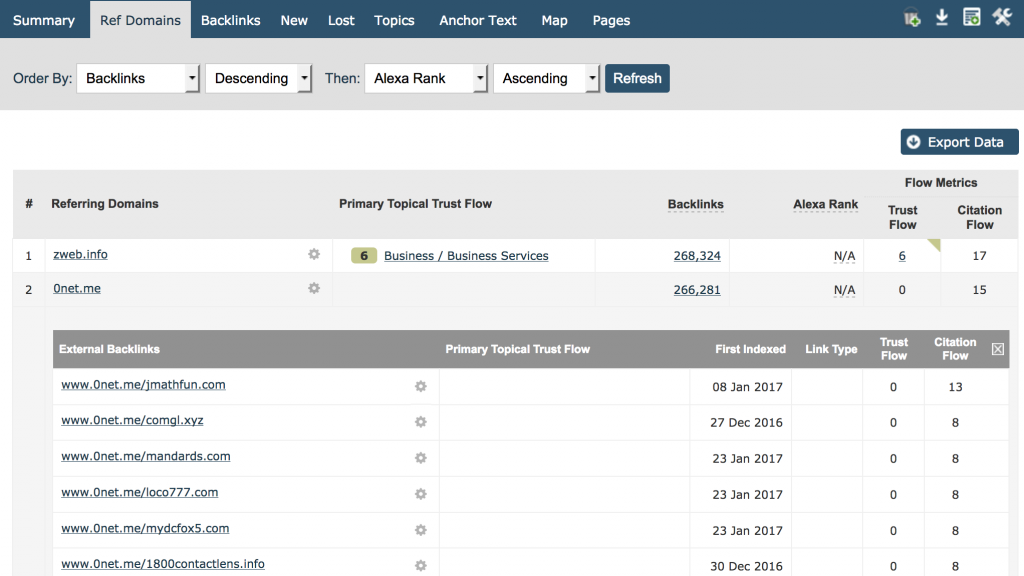
Penso che siamo tutti d’accordo che tutti e 266.281 link da www.0net.me non possono fornire più informazioni di quante ne forniscano 100’000 link da www.0net.me!
La sezione del dominio è ideale per identificare e scovare il peggio dello spam presente sul tuo sito. è anche utile, in questo post, per identificare aree in cui un bot potrebbe essere più intelligente ed efficiente nelle sue attività di crawling.
L’hosting economico può essere dannoso

Un altro problema che possono causare bot aggressivi può sorgere se ci sono troppi siti web su uno stesso server. Sfortunatamente host economici trattano i bot, più che come una risorsa, come un vero e proprio problema rispetto alle società di hosting che offrono servizi di qualità. Questo perché le società di hosting con offerte commerciali molto aggressive, tendono a mettere centinaia – se non migliaia – di piccoli siti sullo stesso web server fisico. (Potete utilizzare il Neighbourhood checker di Majestic per vedere quanti siti ci sono sul tuo server) Majestic rispetta le direttive di Crawl Delay nel Robots.txt e al contempo sta diventando sempre più intelligente nel trattare siti su questi server. Questo vi riguarda, specie se v’importa qualcosa di Google. Googlebot NON rispetta le direttive di Crawl Delay e usa invece un limite arbitrario per fissare un tetto di indicizzazione massima così da non causare inutile stress al server. Se il vostro server ha 1000 altri siti – alcuni con migliaia di pagine in più del vostro, sullo stesso server, dovreste chiedervi quanto del crawl di Googlebot sul server indicizzerà le pagine del vostro sito e quanto quello degli altri siti.
L’albero delle decisioni per un crawler più intelligente
Ora abbiamo un numero di elementi che possono migliorare un crawler nella gestione delle proprie risorse, riducendo di fatto il proprio impatto in internet. Tutto questo crea una situazione che gioverà a tutti. Dati più accurati. Internet più veloce.
Decisione 1: Scoperta vs Integrità
Per quanto riguarda il mantenere un indice web della dimensione di quello di Majestic, il tempo è una minaccia all’integrità di Internet. Ogni secondo che passa vengono creati nuovi contenuti ed i contenuti vecchi vengono distrutti o modificati. Ora immaginate quel preciso istante in cui Majestic deve scegliere cosa indicizzare. Una URL che non è stata mai indicizzata prima o una che ha indicizzato il giorno prima? Cosa scegliere? Quella nuova? Perfetto! Ma la prossima volta cosa sceglierà? E la volta dopo ancora? Abbiamo già esplorato il concetto dell’infinità del web, pertanto questa logica presenta un grave problema se non controlli MAI lo stato di una pagina, se è cambiata o se ha perso posizioni. Majestic è riuscito a risolvere questo problema nel 2010 . Per l’esattezza lo ha risolto in modi diversi. Se i bot di Majestic si concentrano troppo sulla scoperta dell’inedito a discapito dell’integrità, c’è un sistema di sicurezza integrato nell’indice recente. Questo perché dopo 90 giorni se una pagina non viene re-indicizzata, scompare dall’indice. Questo significa che l’indice recente non avrà mai dati che sono vecchi più di tre mesi. Fortunatamente, questo succede raramente…o almeno non succede a pagine che molte persone hanno a cuore poiché le nostre metriche indicano a chi dare maggiore priorità in modo bilanciato, cosicché pagine più importanti vengono visitate più frequentemente rispetto a pagine di minore influenza e importanza. Se Majestic dovesse iniziare a far riferimento solo ai conteggi di link, l’utilizzo di banda totale incrementerebbe drasticamente.
Decisione 2: Profondità del Crawl
Ma quante pagine sono abbastanza!? Una directory che ha le sembianze di essere spam ha più pagine della BBC! Ma sicuramente la BBC ha bisogno di avere tutte le sue pagine indicizzate costantemente giusto? Beh, non necessariamente. La BBC produce notizie che per loro natura diventano obsolete. Eventualmente una notizia cesserà di essere una notizia di attualità ed interessante, e la BBC cancellerà la pagina. Prima di cancellarla, si procede per gradi eliminando ogni link interno, rendendola disponibile solo dalle SERP dei motori di ricerca e da link di terze parti. Il problema diventa ancora più complicato su siti come eBay e Mashable dove i contenuti sono generati dagli utenti, creando di fatto una sottile linea grigia tra qualità e quantità. Qui le metriche di flusso aiutano tantissimo. Altri software SEO sono capaci di implementare strategie per effettuare questa scelta. In particolare possono scegliere un proxy per “qualità” facendo scraping delle SERP di Google su scala, utilizzando poi un indice di visibilità per semplificare il processo decisionale. Non ho notizie certe sull’effettivo utilizzo di queste pratiche, ma osservando i dati delle SERP su scala, verrebbe da dire che un tale approccio è sensato e da utilizzare come segnale.
In fondo però dobbiamo proteggere i nostri crawler dal problema dell’infinità di Internet. Dobbiamo altresì evitare di indicizzare lo stesso sito (o server) così tanto che vada poi ad influire sulla latenza degli utenti reali.
Decisione 3: Cosa scartare
Stavo per intitolare questa ultima sezione dell’articolo “Quanti hard disk da acquistare”, però pensandoci bene non è una domanda rilevante. Una volta compreso che il problema delle indicizzazioni è indefinito (infinito), la vera domanda diventa inevitabilmente “cosa scartare”. Quali dati dell’indicizzazione sono così inutili che, anzi, non si sarebbero dovuti indicizzare affatto – se non per scovare contenuti altrettanto inutili – con l’obiettivo di rimuovere tutto ciò che non è utile dai dati raccolti. Majestic, negli ultimi mesi, è riuscita nel fare proprio questo ed i risultati sono stati a dir poco impressionanti. Nel momento in cui ciò diventa un fattore determinante, la ricerca dell’indicizzazione rapida diventa una ricerca inutile.
- Quale sarà l’importanza dei backlink nel 2023 - February 20, 2023
- Autorevolezza e Link Building - September 25, 2022
- Trust e Link Building - August 17, 2022