






Temat wewnętrznego linkowania jest jednym z najgorętszych tematów w SEO. W ostatnim artykule, jaki napisałem dla loga Majestic, skupiłem się na temacie ustalania priorytetów adresów URL przed i po migracji (można go przeczytać tutaj). W tym artykule jednak skupimy się na stronach sierocych – czym są, jak je znaleźć i dlaczego to ważne.
Czym są strony sieroce?
Techniczny termin „strony sieroce” oznacza adresy URL lub podstrony, których nie można znaleźć poprzez wewnętrzne linkowanie, ponieważ w ogóle nie są podlinkowane. Takie adresy URL, które nie są wewnętrznie linkowane, „dryfują” w zestawie domeny URL i nie można ich znaleźć w ustandaryzowanym wyszukiwaniu internetowym. Oznacza to, że nie może ich też znaleźć zwykły bot Google. A zatem, inaczej mówiąc, ten adres URL (ta strona), jest spisany na straty.
Jak mogę znaleźć strony sieroce?
Strony sieroce można znaleźć tylko po połączeniu różnych źródeł danych. Dlatego też do odkrycia stron sierocych może prowadzić analiza luk, ale trzeba tu uważać; stron sierocych nie należy mylić ze stronami „dead end” („ślepymi uliczkami”), które z kolei mają linki do nich prowadzące, ale nie mają żadnych linków wychodzących; dlatego strony te są „ślepą uliczką”, co, prawdę mówiąc, może też stanowić problem dla wewnętrznego linkowania, ale nie ma zasadniczego znaczenia dla stron sierocych i nie będziemy tego omawiać w tym artykule.
Jak mogę znaleźć strony sieroce przy użyciu danych z backlinków?
Najbardziej oczywista rzecz, jaką można zrobić to przeprowadzić analizę luk z danymi z backlinków domeny.
Połączenie danych z wyszukiwania internetowego i backlinków to pierwszy, prosty krok do odkrycia stron sierocych. Dokładna metoda i sposób jej przeprowadzania prawdopodobnie będzie zależeć od Twoich preferencji i dostępnego zestawu narzędzi. Jeśli masz pod ręką zarówno przeszukiwarkę, jak i dane Majestic, możesz porównać adresy URL z wyszukiwania internetowego z docelowym linkiem adresów URL linków zewnętrznych. Porównanie adresów URL, np. przy pomocy prostej komendy „SVERWEIS” lub „LOOKUP” w Excelu, może okazać się wystarczające dla wykrycia wszelkich istniejących stron sierocych.

Jeśli potrzebujesz czegoś bardziej praktycznego i masz do czynienia z dużo większymi ilościami danych, możesz rozwiązać ten problem np. przy użyciu narzędzia w rodzaju Deepcrawl. Oprócz standardowych danych z wyszukiwania internetowego, możesz też dodać dane Majestic z backlinków przy tworzeniu wyszukiwania, zaledwie jednym kliknięciem. Ta funkcja jest bezpłatna dla użytkownika, ponieważ dane Majestic są dodawane za pośrednictwem standardowego interfejsu API.
Możesz też jednak dodać ręcznie do wyszukiwania do 100 MB danych z linków. W rezultacie otrzymujemy przegląd odzwierciedlający analizę luk, niezależnie od tego czy narzędzie dotarło do adresów URL z wyszukiwania internetowego, czy z danych z backlinków.
W najlepszym razie, raport będzie wyglądał w taki oto sposób, ponieważ nie znaleziono tutaj żadnych stron sierocych z danymi z backlinków:

Możliwe jest również, że w raporcie pojawi się określona liczba adresów URL, odzwierciedlająca szukane strony sieroce. Te adresy URL należy poddać dalszej analizie. Należy ocenić czy strony te:
a) Dają realną korzyść
b) Jakie jest dokładne pochodzenie tych stron
c) Czy należy przejrzeć i zaktualizować te strony, ponieważ stanowią wartość dodaną dla użytkownika lub
d) Czy ostatecznie należy je całkowicie wyeliminować.

Ponieważ teraz już wiemy jak możemy odkryć strony sieroce przy pomocy danych z backlinków, chcemy przejść do dalszych źródeł danych, co również może przyczynić się do ich odkrycie (mała uwaga: użyto w tym celu również Deepcrawl).
Znajdź strony sieroce poprzez mapy stron
Tak naprawdę łatwo tą drogą sprawdzić występowanie stron sierocych, a mimo to rzadko korzysta się z tej metody. W większości przypadków sprawdzasz czy Twoja mapa strony zawiera wszystkie adresy URL, które chcesz tam mieć. Rzadko sprawdza się czy zawiera adresy URL, których nie można znaleźć poprzez wyszukiwanie internetowe.
Zwykle ma to miejsce, kiedy tworzona jest nowa strona, która automatycznie generuje mapę strony, ale zapomina podlinkować stronę wewnętrznie. Kolejnym powodem jest sytuacja, w której strony są usuwane z linku wewnętrznego tylko dlatego, że nie są już uznawane za ważne, ale mapa strony nie jest automatycznie dostosowywana. Na szczęście, różne narzędzie pomagają to kontrolować. Nie zawsze musi to oznaczać odnalezienie dużej liczby adresów URL; czasem wystarczy od 1 do 10, jak widać na tym zrzucie ekranu.
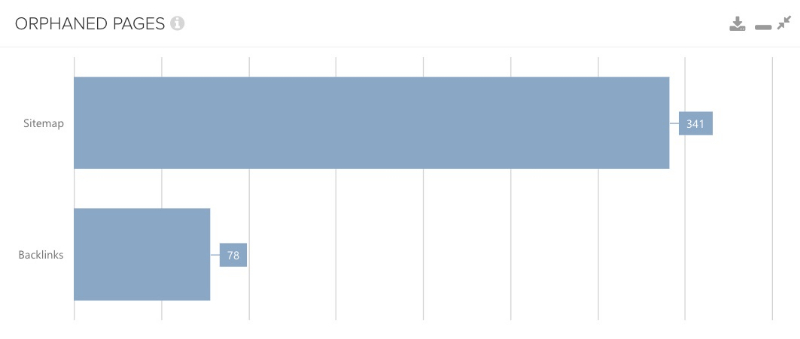
Ponieważ mamy już za sobą odnajdywanie stron sierocych poprzez dane z mapy strony, możemy przejść do kolejnego ekscytującego i równie ważnego zestawu danych
Znajdź strony sieroce poprzez dane z Google Search i Analytics.
To porównanie jest prawdopodobnie najciekawsze, ponieważ obecnie otwarcie korzysta się z danych Google. Dlatego jeśli znajdziemy strony sieroce poprzez skojarzenie ich z danymi z Google Search i Analytics, znaczenie tego odkrycia może być odrobinę większe niż, np. wtedy gdy dzieje się to poprzez mapę strony.
W tym przypadku możemy być pewni, że Google zna te adresy URL z dowolnego źródła – i że nie podlinkowaliśmy ich już wewnętrznie. Oczywiście, nie zakładamy, że jest to różnica w adresie URL (co mogło być spowodowane sterowaniem przeszukiwarki), a ponadto, zawsze zakładamy, że można indeksować unikalne adresy URL (w szczególności strony bez parametrów lub strony sortowania).
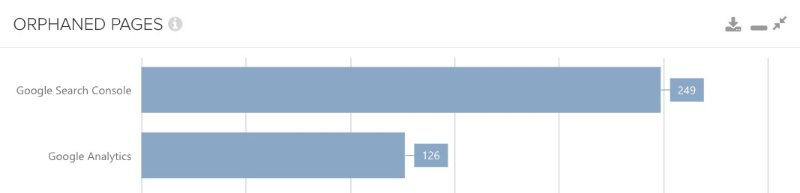
Jeśli interesują Cię inne pomysły, możesz użyć kolejnych źródeł danych, aby odnaleźć strony sieroce.
Znajdowanie stron sierocych poprzez pliki dziennika
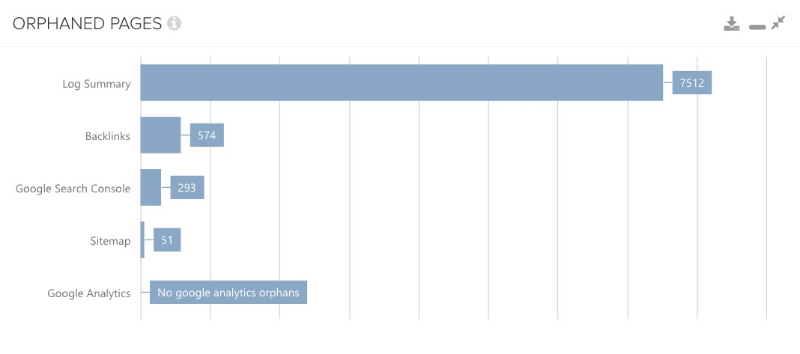
Wspomniałem, że porównanie z Google Search Console i Analytics jest ekscytujące, ale powinienem również wspomnieć, że porównanie z plikami dziennika jest tak naprawdę jeszcze lepsze, a powód jest bardzo prosty: pliki dziennika to dane po stronie serwera, które odznaczają się dokładnością. Dane po stronie klienta, takie jak Google Analytics albo dane z GSC, których pochodzenia zasadniczo nie znamy, są tu czymś w rodzaju „czarnej skrzynki”.
Jeśli więc masz pod ręką dzienniki serwera, możesz ich użyć, żeby przeprowadzić porównanie, z nadzieją, że rezultat nie będzie wyglądał jak na załączonym obrazku. To raczej niepokojąca sytuacja.

Jeśli nadal nie masz dosyć pomysłów na odnalezienie stron sierocych, możesz też wyeksportować wszystkie utworzone i aktywne strony ze swojego systemu, a następnie porównać je z zestawem adresów URL z wyszukiwania internetowego. Można się zdziwić jak często pojawiają się wyniki i jak często są to strony sieroce. Powodów jest wiele, co każe nam przejść do kolejnej części.
Przyczyny powstawania stron sierocych
Omówiliśmy już sobie wiele sposobów odnajdywania stron sierocych, ale nie wspomnieliśmy jeszcze o przyczynach ich powstawania, a tych może być wiele. Oto kilka możliwości (lista ta nie jest wyczerpująca).
- Strony, które zostały całkowicie lub sukcesywnie usunięte z linku wewnętrznego, ale nie zostały ostatecznie wyłączone.
- „Strony testowe” z systemu sklepowego, np. w celu przeprowadzenia testów A/B. Osoba, która kierowała projektem w pewnym momencie odchodzi z firmy i nikt już nie zna tych adresów URL.
- Adresy URL ze starego, poprzedniego systemu CRM, nigdy nie zostały całkowicie dezaktywowane.
- Strony docelowe dla modnych/sezonowych tematów nigdy nie zostały wyłączone.
- Nieprawidłowe użycie CMS, skutkujące wygenerowaniem stron.
- Kategorie przeniesione do trybu offline nie zostały przekazane dalej.
- Strony zostały po prostu „zapomniane” podczas migracji.
Problem ze stronami sierocymi
Czasem istnieją naprawdę dziwaczne powody, które, choć brzmią śmiesznie, odwracają uwagę od znaczenia tego tematu. Jednym z głównych powodów, dla których strony sieroce mogą być niekorzystne, nie licząc kwestii higieny indeksu, jest to, że powodują problemy w targetowaniu domeny według słów kluczowych. Na przykład, oprócz adresów URL dla głównych słów kluczowych strony sieroce, o których nikt nie wie, ale które są dopasowane do tego samego słowa kluczowego lub jego wariantów (np. „lodówka vs. chłodziarka” itp.), mogą zaszkodzić powodzeniu danej domeny w rankingu.
Byłoby to również niekorzystne, gdyby nieprawidłowy adres URL, choć (już) niepodlinkowany wewnętrznie, znalazł się w rankingu, ponieważ starsza wersja jest być może lepiej podlinkowana zewnętrznie niż nowsza i bardziej zoptymalizowana strona; (tak; czasem strony również nie są przekazywane dalej!). Pewną rolę w powstawaniu stron sierocych może również odgrywać utrata siły linku.
Oczywiście, zawsze należy sprawdzać ruch na tych stronach – nie bez powodu są porównywane przy użyciu Google Analytics. Trzeba jednak również wziąć pod uwagę, że strony sieroce mogą zakłócić strukturę linków domeny, np. jeśli znajdują się – pod względem hierarchicznym – pośrodku. Oznacza to, że strona sieroca zawiera wyłącznie linki do innych stron, które przez to całkowicie wypadają ze struktury adresy URL, ponieważ są podlinkowane wyłącznie ze strony sierocej.
W końcu, ci, którzy nie analizowali jeszcze swojej domeny pod kątem stron sierocych, wiedzą już co to jest, dlaczego jest to ważne i jak można w związku z tym postępować. Miejmy nadzieję, że nigdy nie znajdziecie się w takiej sytuacji:
Dlaczego strony sieroce są ważne?
Z perspektywy SEO strony sieroce oznaczają, że możesz posiadać mocne i wartościowe treści, które nie są podlinkowane. Oznacza to, że wskaźnik Trust Flow lub wiarygodności online nie przechodzi przez te strony, co mogłoby wpłynąć na widoczność Twojego profilu w internecie. Co więcej, Twoi czytelnicy i użytkownicy, przeszukując Twoją witrynę, mogą przegapić naprawdę wartościowe treści z tych stron.
A zatem po prostu to zrób – zacznij szukać stron sierocych już dziś!
- Strony sieroce: Jak je rozpoznać i na czym polega problem - August 20, 2018
- Migracje domeny: zwróć uwagę na linki (wewnętrzne)! - May 21, 2018
- Czy uwzględniłeś te 7 czynników w swojej analizie profilu linków? - March 5, 2018