






Back in May, we launched OpenRobotsTXT, a project to archive and analyse the world’s robots.txt files. We’re excited to announce a new update to the site. You can now search the archive for individual websites’ robots.txt files and look up specific bot names.
If you’re interested in the project background for OpenRobotsTXT, there’s lots of details over on the About OpenRobotsTXT page.
Search for a site’s robots.txt file
With Site Search, you can now lookup robots.txt files for individual websites. This is great for making sure your server setup delivers the robots.txt file as you intend.
It’s straightforward to get started. Click on the Site Search link at the top of the page, and enter the domain you’d like to check.
If you’re not sure where to start, we’ve added a starter list of sites we found useful while building these new functions.
As an example for this blog post, here’s the result of a search for Flickr. When we find a robots.txt file, we show the most recent one, loaded and parsed, with each bot converted to a clickable link.
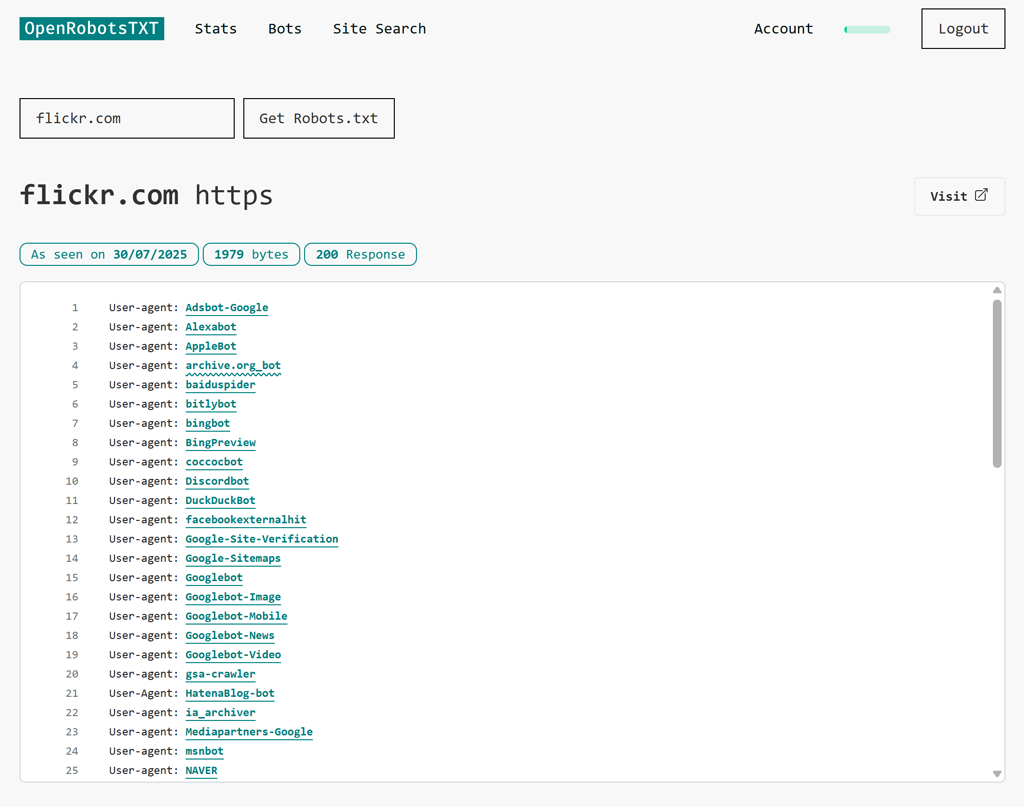
As well as the interpreted robots.txt file, you’ll see the date we last fetched the file, the size of the robots.txt file, and the most recent crawl response.
Find out if we couldn’t retrieve a robots.txt file
If we weren’t able to fetch a robots.txt file, you’ll typically see a “404 Response”.
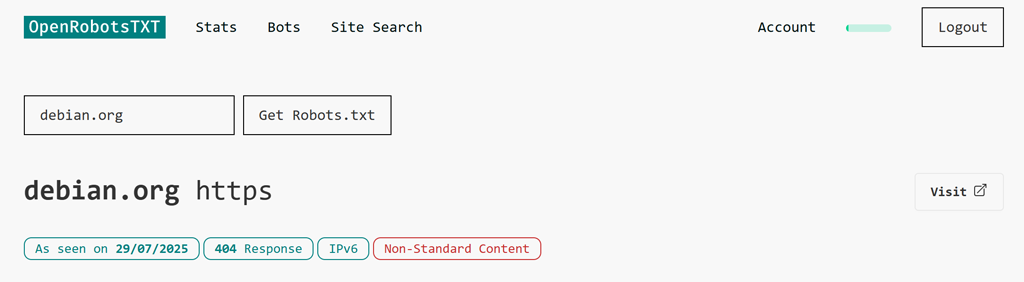
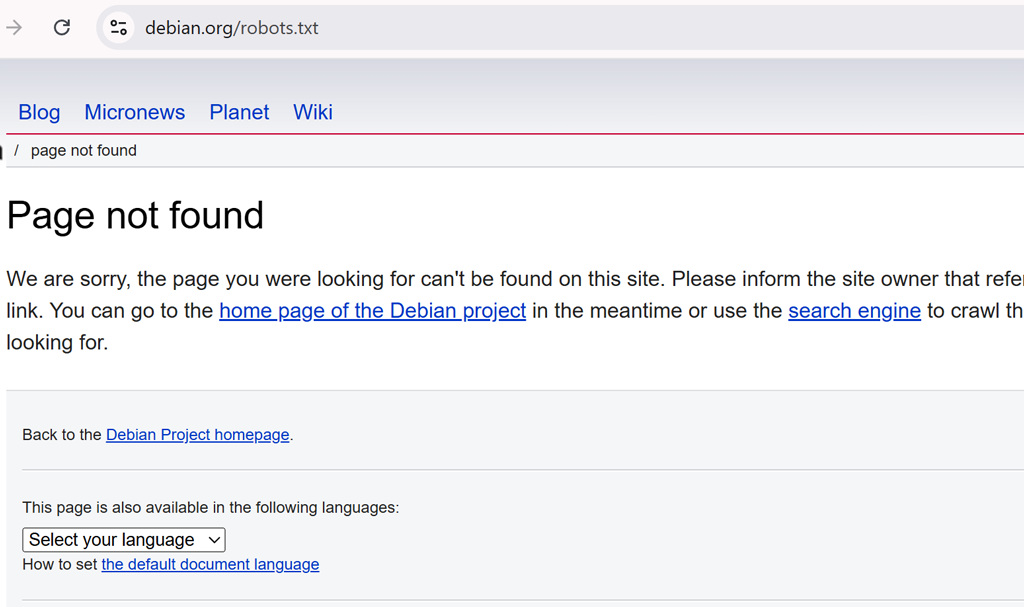
For this search for debian.org, there is an additional note that the file had, “Non-Standard Content.” This flag is typical when the robots.txt request receives a 404 error, as sites tend to forward all 404s to a standard HTML page.
Some websites do present different data to crawlers than to regular visitors, so if you receive a response that you weren’t expecting, you can press the “Visit” button on the right hand side to check the robots.txt for yourself. In the case of Debian, clicking through confirms that there is no robots.txt file available at the usual URL.
Bot names in Robots.txt files
Of course, the main reason that most people search robots.txt files is to see which specific bots are included. And that’s where things start to get a little bit interesting.
You see, robots.txt files are very, very rarely validated. So many files have malformed directives, incorrect user-agent names, or outdated rules.
For example, did you know that the RFC 9309: Robots Exclusion Protocol specifies that crawler names MUST ONLY have uppercase and lowercase letters (“a-z” and “A-Z”), underscores (“_”), and hyphens (“-“)?
To help identify crawler names that don’t conform to this standard, we’ve added a wavy underline to the user-agent line.
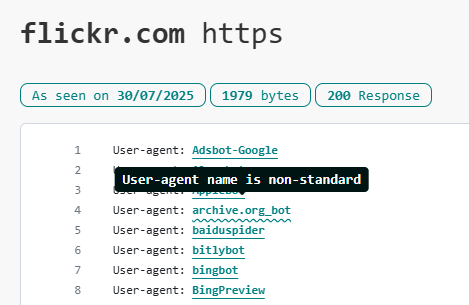
You should note that this type of wavy line on its own does not mean the robots.txt file is incorrect.
For example, if a bot name has a number in it, then you should continue to use its given name, even though the name they chose for themselves doesn’t match the RFC 93009 standard. There are many crawlers whose name pre-dates the standard (eg MJ12Bot!), or whose owners didn’t realise that the standard exists. While the wavy line is a handy guide, if you don’t use the exact name the bot is expecting to see, the bot will not find its instructions.
Where the wavy line DOES become useful is spotting malformed entries in the robots.txt file. Take this next site, for example.
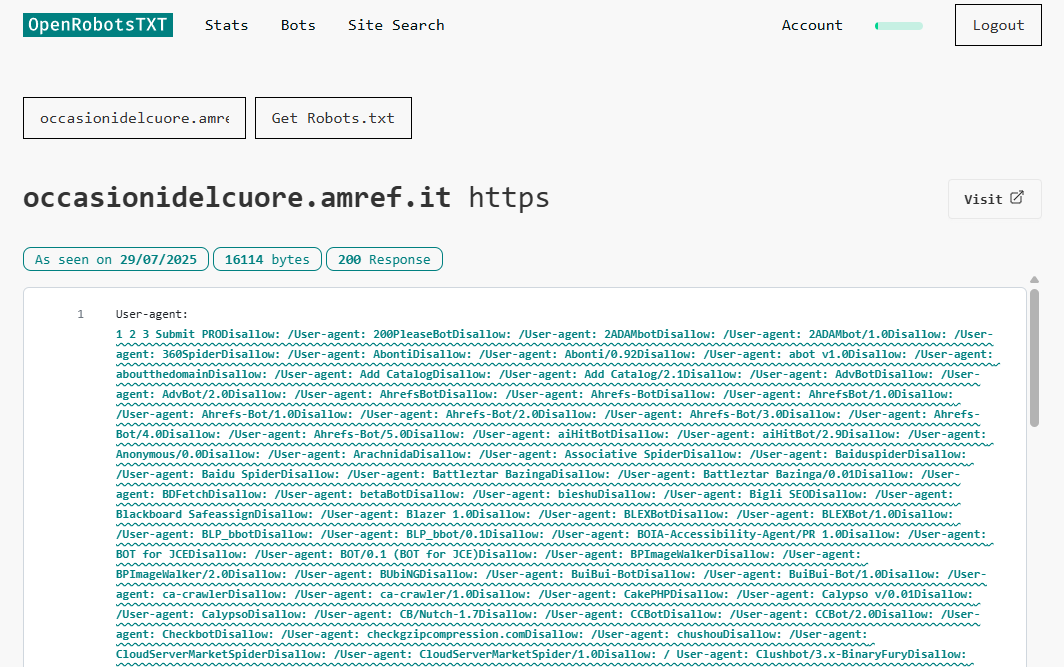
There are so many crawlers listed it’s probably safe to assume that this robots.txt is programmatically compiled, rather than hand-made. However, the output does not include line break characters.
As a result, the user-agent declarations all merge into each other. While a human reader can see what the site author was trying to do, a crawler could decide to interpret that as one huge bot name and may not realise that a small part of this huge string applies to them.
We have found some site searches to be incredibly interesting. Let us know if you find anything unusual or exciting!
Search for Individual Bots
There’s two ways to search for a bot.
- You can click on any user-agent name in a robots.txt file to perform a search for that individual bot.
- Jump straight to a bot without having to do a site lookup first.
If you prefer #2, you’re in luck. As well as adding Site Search, we have also opened up bot searching. You can now use the “Bots” link at the top of the page to lookup high-level stats for interesting bots.
Here’s an example where we searched for AdsBot-Google.
These are the stats for that particular bot.
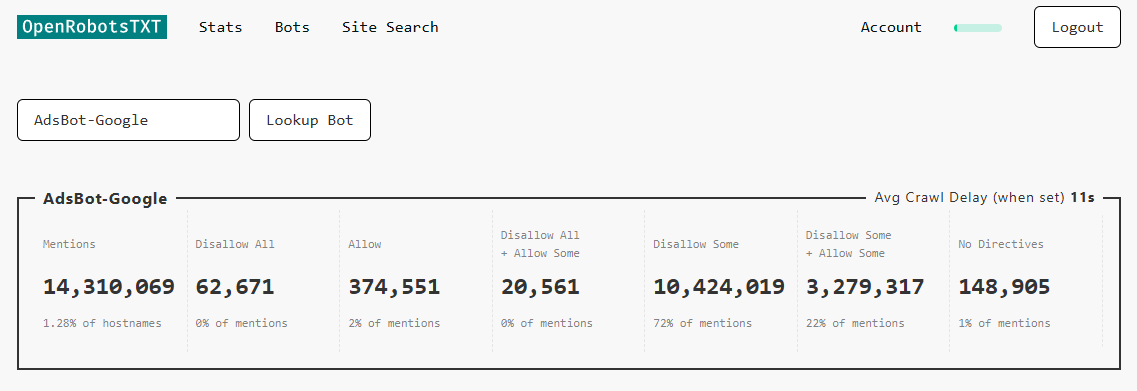
Bear in mind that some bot names are a consolidated total of many user-agent entries that have near-identical similar names.
Here is one example, where a version number has been added to the user-agent name.
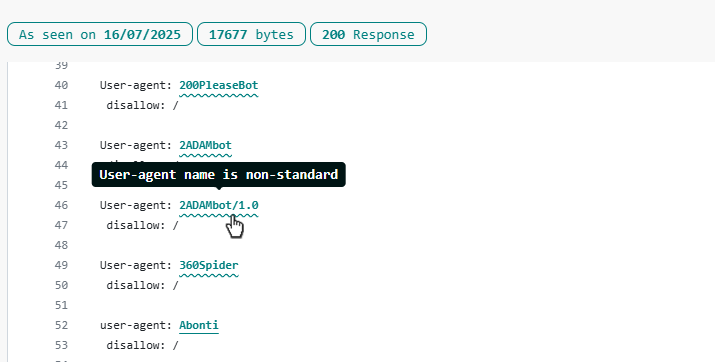
If you click through to see that bot, you will see this screen, containing an indication that this bot string has been rolled into a parent bot name that does not include version numbers.
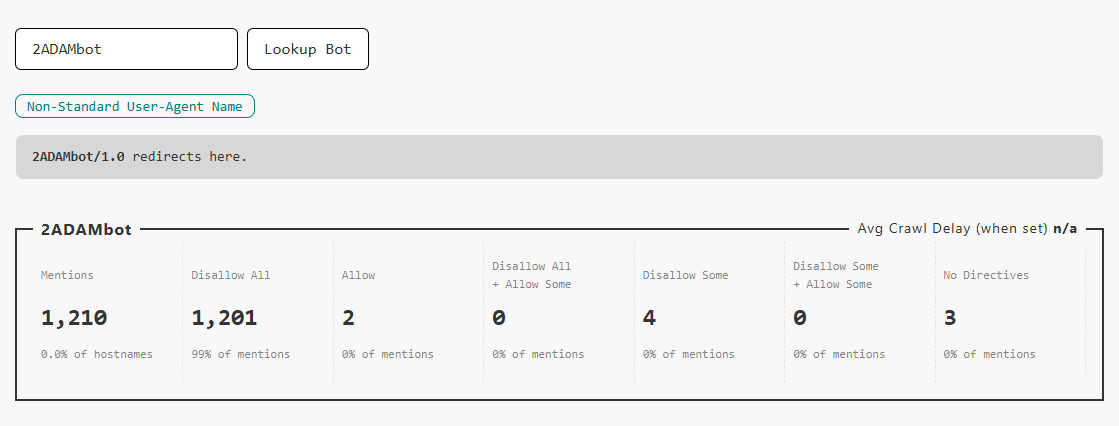
It’s worth noting that while OpenRobotsTXT recognises these as the same bot, an individual crawler may ignore directives where it does not realise that this type of name variant applies to itself.
Now you’ve seen how you can look for crawler names, you can jump in and start to search for bots here. Anyone can search bots, there is no account needed.
Note: If you’re looking for lots of bot data, you don’t have to write a script to crawl every page. The Stats page contains a CSV containing all of the high-level stats for each bot.
Have a go
Hopefully if you’ve got to the bottom of this post, you’re keen to give new OpenRobotsTXT searching a try.
We do have one request. If you’d like to search through site robots.txt files, we kindly ask that you sign up for a free account. This really helps us prevent excessive or automated requests, ensuring reliable service for everyone.
Thank you for your interest in OpenRobotsTXT. We are still working on ideas to enhance the service, and hope that it will continue to deliver a great insight into the world of robots.txt. Please let us know if you have any great ideas, or would like to be involved.
- TLD Checker – New for 2026 - February 26, 2026
- Welcome Hub – Improving the final step of your login journey - September 9, 2025
- Site Explorer – Advanced Query Filters BETA - August 28, 2025