






Eine kürzlich von Incapsula veröffentlichte Studie zum Thema Bot-Aktivität hat den Autor dieses Artikels dazu gebracht, ein paar Gedanken zusammenzufassen, wieso smartes Crawlen wichtiger ist als schnelles Crawlen. Incapsula veröffentlicht die Studie bereits seit mehreren Jahren. Anfänger und Pseudo-Experten sind an dieser Stelle vielleicht alarmiert, wenn sie hören, dass nur die Hälfte allen Traffics von echten Menschen stammt.
Dieser Blog Post befasst sich mit den Konsequenzen des Crawl-Rennens, seinen Einfluss auf die Index-Qualität und Versuche von Spammern, Bots langfristig zu frustrieren. Ja, ich werde an dieser Stelle eine Linknetzwerk-Technik outen. Eine ziemlich Dumme, welche ganz von alleine zu meiner vollen Aufmerksamkeit geschafft hat.
Gute Bots und schlechte Bots

Incapsula hat herausgefunden, dass der Großteil des weltweiten Traffics von 35 guten Crawlern (inkl. Majestic) und ein paar wenigen schlechten stammen. Auf die schlechten gehen wir heute aber nicht viel tiefer ein. Obwohl es erwähnenswert ist, dass einige wenige naive Firewall-Systeme ein paar Bots mit ihrem User Agent blocken, ohne die Möglichkeit zu bieten eine andere Entscheidung zu treffen. Diese Systeme sind wirklich schlecht beraten. Hier sehen Sie den relativen Einfluss jeden Bots auf die komplette Bandbreite des Internets.
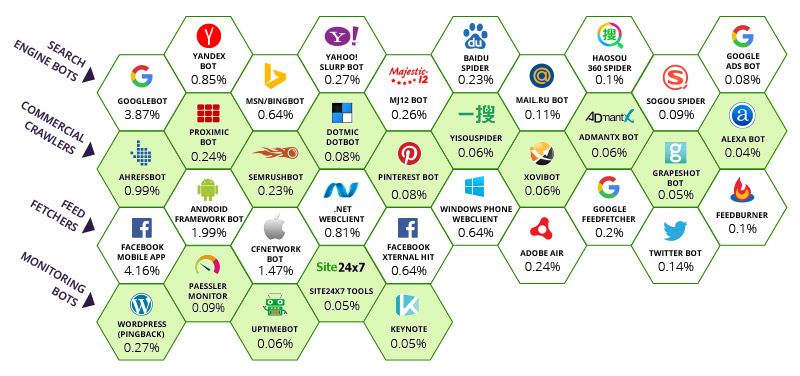
Die Zahlen unter jedem Bot repräsentiert den Prozentsatz der Besuche der getrackten Seiten, die jedem Bot zugeschrieben wurden. An der Spitze steht Facebooks mobile App. Sie greift bei 4,16% der Bandbreite. Google befiehlt 3,87% der weltweiten Bandbreite. Eigentlich sogar mehr, wenn man auch die Bots betrachet, die zu Google gehören. Fairerweise muss man sagen, dass Google und Facebook dazu beitragen, dass ein sonst chaotisches System integriert, verbunden und navigierbar bleibt. Dies können sich aber alle Suchmaschinen der oberen Reihe auf die Fahnen schreiben. Majestic ist dankbar von Incapsula mit in diese Reihe aufgenommen worden zu sein. Als Top 10 Crawler hat Majestic eine Verantwortung zu wissen, wann man mit dem Crawlen aufhören muss. Es gibt immer den Ruf in der SEO-Community bloß auch “ALLE” Links zu bekommen. Oder zumindest so viele wie möglich. Dies schafft aber ein Paradoxon. An welcher Stelle sollte man aufhören das unendliche Netz zu crawlen?
Das unendliche Netz
Unser jüngstes Projekt, das Majestic und die Internationale Raumstation betraf, war nicht nur eine reine PR-Aktion. Die Aktion sollte einmal mehr verdeutlichen, dass das Internet von einer unendlichen Natur ist. Diese Unendlichkeit hat tiefgreifende Auswirkungen auf Link-Tools. Vor ein paar Monaten hat Majestic Milliarden von Webseiten aus dem Crawl entfernt. Dies waren alle Subdomain-Seiten, die automatisch generiert wurden. Dieses Vorgehen verursachte zu der Zeit ein ziemliches Furore für ein paar Domainer, die den Trust Flow der “www”-Version einer Domain (die technisch eine Subdomain-Variante ist) nutzten, um Websites für den Verkauf der Domain-Namen bewerten. Die Lego-Pyramide hilft, das Dilemma zu visualisieren:

Stellen Sie sich vor, dass diese Pyramide alle Subdomains im Internet darstellt. Die an der Spitze sind welche mit Trust Flow Werten zwischen 90-100 und die an der Unterseite haben einen TF=0. In der Tat fand Majestic, dass die Subdomains an der Unterseite viel weniger als Null wert waren. Sie hatten keine eingehenden Links von irgendwoher außer der Root Domain und wurden so zahlreich, dass sie nicht nur für die untere Ebene verantwortlich waren, sondern auch für die Ebene darüber. Der Majestic Trust Flow-Algorithmus enthält so etwas Ähnliches wie das Pyramidenmuster. Je mehr Müll am Boden, desto höher der Trust Flow von allem, was nur minimal besser ist als Spam. Weil dies ein unendliches Problem ist, kann ein Crawler es nicht lösen, indem er einfach mehr crawlt.
Alles, was damit erreicht werden würde, ist, dass die nächste Ebene besser dastehen würde als sie sollten, und wir hätten immer noch nicht “ALLE” Links, denn irgendetwas, dass durch Unendlich geteilt wird, ist immer noch kein großer Prozentsatz. Majestic könnte eine Serverfarm in der Größe eines Fußballplatzes betreiben, aber das Problem immer noch nicht lösen. Also haben wir uns entschlossen die unteren beiden Ebenen zu eliminieren. In Anlehnung an das Lego-Beispiel ist das mehr als die Hälfte der Daten! (36 von 70 Steinen = 55%). Jede einzelne von ihnen ist eine Seite, die kein Mensch jemals gesehen hat und keine Suchmaschine mit etwas Selbstrespekt jemals crawlen sollte. Der Effekt zeigte sich in Form einer verkleinerten Pyramide. Plötzlich waren Seiten, die auf der dritten Ebene einer 1-100 Skala waren, auf der unteren Ebene. Sie können sich die Panik vorstellen, die in der Domain-Community entstand, und Sie können diese fast in den Kommentaren in diesem Thread spüren.
Dies ist nicht der einzige Weg, in dem ein unendliches Web generiert wird. Majestic.com selbst (und jede Suchmaschine) schafft potenziell unendliche Loops einfach durch seinen Ursprungszweck. Sie können jeden beliebigen Satz von Zeichen in Majestic.com eingeben und das System wird sich bemühen, die Ergebnisse zu interpretieren. Dies wiederum schafft SERPs (Search Engine Results Pages), die wiederum Links kreieren.
Diese Links sollten nun auf bereits vorhandene Seiten verknüpfen, also ist dies eine geschlossene Schleife, aber die Such-URL selbst kann in ihrer Natur unendlich sein. Majestic (und Google) helfen anderen Suchmaschinen, dies zu erkennen und beide nutzen ihre Robots.txt-Dateien, um den anderen zu sagen, dass sie wahrscheinlich ihre kostbaren Ressourcen nicht beim Crawlen dieser unendlichen URL verschwenden sollten.
Spammer verdoppeln die Problematik
Der Anfnag dieses Artikels deutete bereits an, dass es ein “Outing einer Linknetzwerk-Technik” geben wird. Es ist nicht etwas, was ich normalerweise tun würde, aber dieses besondere Netzwerk war besonders dumm und besonders schädlich zu unserem MJ12Bot. Ich habe darauf hingewiesen, dass User Agents optional sind. Majestic hat sich entschieden sich immer zu identifizieren. Wenn Sie nicht möchten, dass Majestic Ihre Website crawlt, dann verwenden Sie Robots.txt, um diese Anweisungen zu geben. Leiten (301) Sie NICHT den Majestic Bot – wie dieses Linknetzwerk es tat – zu der Majestic Homepage um. Die Folge ist eine sehr interessante E-Mail-Benachrichtigung in meinem Posteingang und zeigte mir einen massiven Zustrom von Links zu Majestic.com:
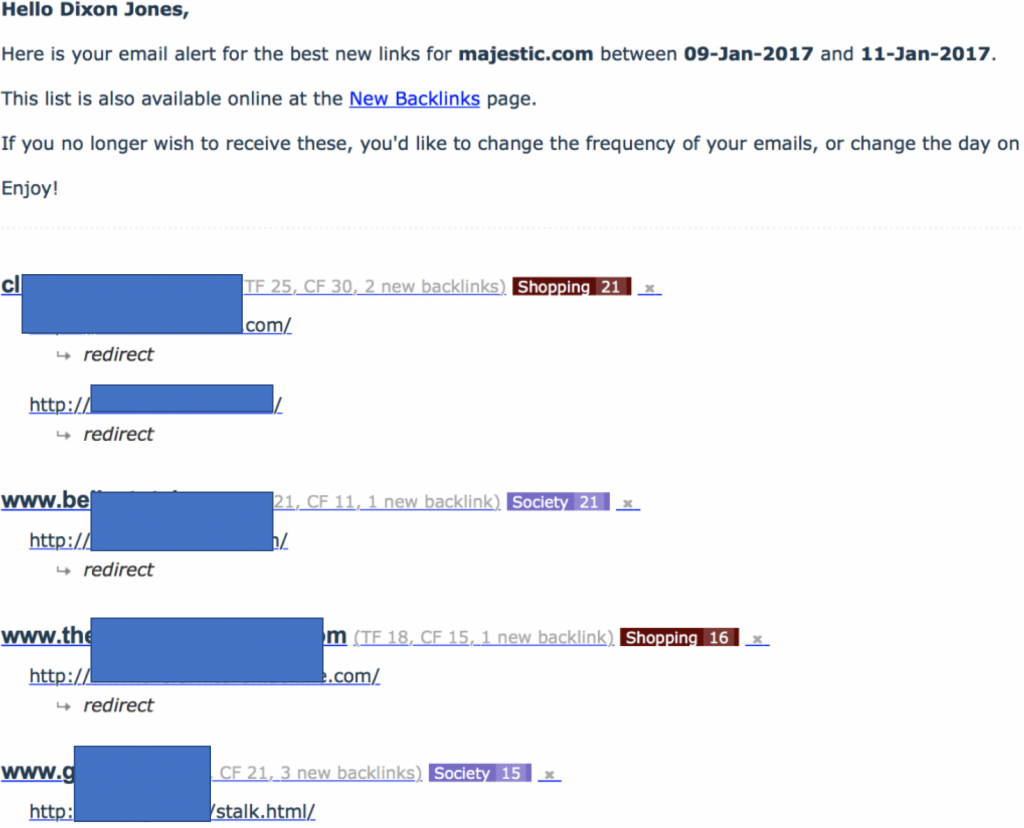
Beachten Sie, dass alle neu gefundenen Links zu Majestic.com anscheinend von diesen Webseiten umgeleitet wurden. Das war des Guten zu viel: Denn als ich die Seiten ansah, waren sie eindeutig Linkfarmen, aber sie haben auch gleichzeitig zu Majestic verlinkt. Das bedeutete, dass sie den MJ12Bot umhüllen mussten (versteckten also Inhalte von unserem Bot). Ich war besonders amüsiert, als das Netzwerk Dateinamen wie “stalk.html” nutzte! Wenn man diese Seiten auf einem normalen Browser betrachtet, sehen sie alle so aus:
User Agents sind optional
Der letzte Schritt bei der Spurensuche, um herauszufinden, was passierte, war ein Drittanbieter-Tool zu verwenden, um zu überprüfen, dass das Netzwerk eine 301-Umleitung auf der Grundlage des User-Agents durchführte. Wenn Sie bei “Http Header Checker” schauen, können Sie es selbst machen, aber es ist besonders hilfreich SEOBooks Header Checker zu benutzen oder verwenden Sie Screaming Frog , da Sie bei beiden Anbietern den User Agent in einem Dropdown-Feld ändern können. Einfach ausgedrückt – diese Seiten wurden von User Agents verdeckt. Wenn Googlebot oder ein realer Mensch die Seite ansteuert, dann sehen sie die Seite, die Sie oben sehen. Wenn ein MJ12Bot ankommt, sieht er Majestics eigene Seite durch eine 301-Umleitung.
Zurück zu der Verantwortung der Crawler
Das Netzwerk hebt eine Herausforderung besonders hervor. Dies führt dazu, dass ein Crawler zwei IP-Nummern betrachten muss und nicht nur eine. Dies muss nicht signifikant sein, da in diesem Fall die Seite ein Spammer ist und die andere Seite Majestic ist, aber es hebt hervor, dass 301-Umleitungen nicht perfekt sind. Sie machen einen immer größeren Teil des Internets aus. Eine effizientere Möglichkeit zur Umleitung wäre, Domainnamen-Aliase zu verwenden. Aber dies verursacht andere Probleme für Suchmaschinen, da die kanonische (bevorzugte) Domäne nicht alleine aus den dns-Tabellen identifiziert werden kann.
Mit einem unendlichen Netz und potenziell lastbringende Umleitungen und alle Arten von anderen Möglichkeiten, um die Effizienz eines Crawlers zu beeinträchtigen, wird es unlogisch, weiterhin versuchen, Spam zu crawlen … nur um diese dann als solchen zu identifizieren. Ein weitaus praktischer Ansatz ist es, genügend Daten über eine Website zu sammeln, um einige Links zu jeder Domain zu sichten und dann weiter zur nächsten Domain zu wechseln. Der Trick ist NICHT den Müll zu durchwühlen… Es ist egal, ob der Müll auf der Seiten-Ebene mit unendlich vielen Seiten oder auf der Subdomain-Ebene mit unendlich vielen Subdomains oder auf der Seiten-Ebene mit unendlich vielen Duplizierungen, Suchergebnissen oder Umleitungen liegt.
Um dies zu tun, müssen die Crawler, die schlauer crawlen wollen, in der Lage sein, erheblich weniger Arbeitslast auf das Netz zu setzen als diejenigen, die schneller crawlen. Crawling funktioniert intelligenter, wenn ein Crawler in der Lage ist, eines der folgenden Signale zu verstehen:
- Ist die Seite wichtig?
- Wird Sie aktualisiert oder bleibt sie statisch?
- Wird automatisch generiert?
- Ist es Spam?
Majestic ist besonders gut bei der oberen und unteren Beobachtung. Flow Metriken geben Majestic einen Blick auf andere Bots und vor allem blicke ich hier auf BingBot. Ich bin mir sicher, dass BingBot aggressiver ist als Majestic, aber ich bin mir nicht so sicher, dass es so sein muss. Vielleicht hat Bing nicht so eine reine Metrik wie den Trust Flow oder den PageRank (ja, sie nutzen ihn immer noch), um den Crawling-Prozess zu unterstützen, aber ich glaube nicht, dass sie deutlich mehr Seiten als der MJ12Bot entdecken, indem sie 250% schneller crawlen. Das gleiche gilt für unsere Kollegen in der zweiten Reihe des Incapsula-Charts.
Der bessere Ansatz – für Majestic zumindestens – ist es, genug zu crawlen, um alle verweisenden Root-Domains zu finden, die zu einer Website verlinken, um dann genug Backlinks dieser Seite für unsere Benutzer zu demonstrieren, die die Natur des Link-Musters aufzeigen. Eine sehr einfache Möglichkeit für Benutzer dies zu sehen, erhält man wenn über das Verw. Domain-Tab die Domain eingibt und nach Backlinks absteigend sortiert. Sie sehen dann die Linkzahl nach Domain und können auf dem Bildschirm und können dann bei Interesse tiefer in die Materie einsteigen. Hier sehen Sie Majestics eigene Seite:
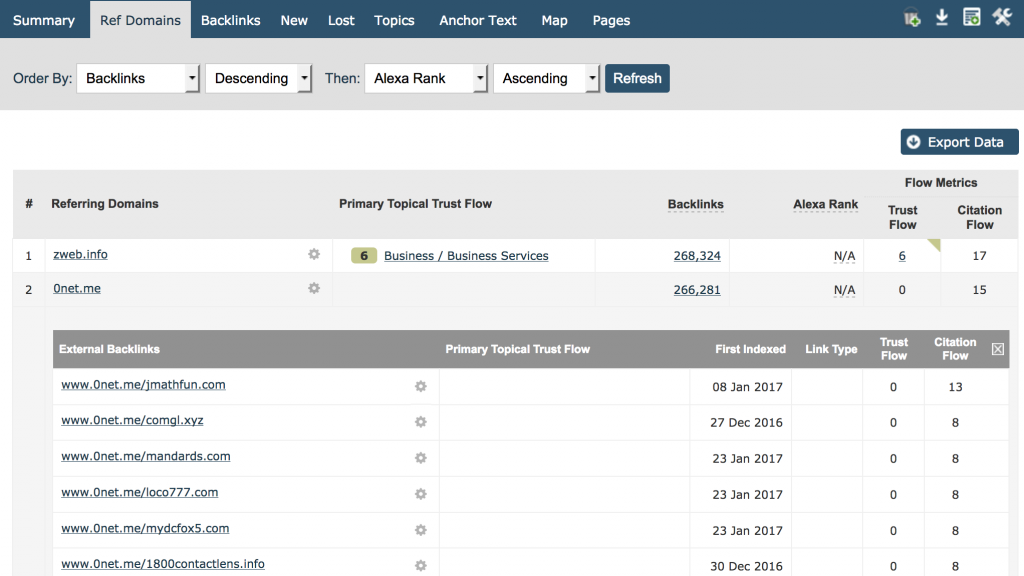
Ich denke, wir können uns alle darauf einigen, dass 266.281 Links von www.0net.me uns nicht viel mehr erzählen, als 100.000 Links von www.0net.me!
Das Domain-Tab ist perfekt für die schnelle Identifizierung einiger der schlechtesten Spam-Links zu Ihrer Website. Es ist auch nützlich in diesem Beitrag für die Identifizierung von Bereichen, wo ein Bot intelligenter und dadurch effizienter beim Crawlen sein könnte.
Günstiges Hosting schadet

Ein weiteres Problem, das aggressive Bots verursachen können, entsteht wenn zu viele Webseiten auf demselben Server sitzen. Leider sehen billige Hosts in Bot mehr ein Problem als robuste Hosting-Unternehmen. Dies liegt daran, dass billige Hosts dazu neigen Hunderte (wenn nicht sogar Tausende) von kleinen Websites auf dem gleichen physischen Webserver zu legen. (Sie können Majestic’s Nachbarschafts-Checker verwenden, um zu sehen, wie viele Websites auf Ihrem Server sind.)
Majestic befolgt Crawl Delay in Robots.txt, aber wird auch immer schlauer im Hinblick auf die Arten von Websites auf diesen Servern. Es ist auch für Sie wichtig, wenn Google Ihnen nicht ganz egal ist. Googlebot befolgt keine Crawling-Verzögerung! Stattdessen verwenden sie eine Gesamtgrenze pro Server, um die maximale Crawling-Rate für diese Maschine zu ermitteln, um keinen unzulässigen Stress auf dem Server zu verursachen. Wenn deine Seite 1000 andere Seiten hat – einige davon mit 1000 mehr Seiten als deine Seite – und diese auf dem gleichen Bediener liegen, musst du dich fragen, welchen Anteil von Googlebots Crawl wird sich tatsächlich auch mit deinen Seiten befassen?
Der Entscheidungsbaum für einen smarten Crawler
Jetzt haben wir eine Reihe von Elementen, die einem Crawler helfen können, seine eigenen Ressourcen besser zu verwalten und damit die Auswirkungen auf das Internet zu reduzieren. Es ist ein Bestreben, das eine Win-Win-Situation schafft. Bessere Daten. Schnelleres Internet.
Entscheidung 1: Entdeckung vs. Integrität
Wenn man einen Web-Index der Größe Majestics betreibt, ist Zeit ist ein natürlicher Feind der eigenen Integrität. In jeder Sekunde, die vergeht, werden neue Inhalte erstellt, aber auch vorhandene Inhalte werden zerstört oder verändert. Stellen Sie sich das alles in einer Sekunde vor … Majestic hat immer die Wahl, was als nächstes zu crawlen ist … Eine URL, die man noch nie gecrawlt hat, oder eine, die erst gestern gecrawlt wurde. Welche Seite wird ausgewählt? Die neue? Großartig! Aber was ist mit der anderen Auswahlmöglichkeit? Oder die nächste? Wir haben das Konzept des unendlichen Netzes bereits identifiziert, also ist diese Logik fehlerhaft, wenn man sich nie wieder umschaut, um zu sehen, ob sich eine Seite geändert oder gelöscht wurde. Majestic knackte das Problem im Jahr 2010 und hat es in mehr als einer Weise gelöst. Wenn Majestics Bots auf der Entdeckungsseite aktiver sind, als auf der Integritätsseite, dann greift ein störungssicheres System im Fresh Index, denn nach 90 Tagen würde eine Seite, die nicht wieder gecrawlt wurde, aus dem Index herausfallen. Dies bedeutet, dass der aktualisierte Index niemals Daten beinhalten wird, die mehr als drei Monate alt sind. Glücklicherweise kommt das doch selten zu dieser Situation … zumindest nicht mit Seiten, die die Leute wirklich interessieren. … denn unsere Flow-Metriken helfen uns, unsere Crawls auf eine ausgewogenere Weise zu priorisieren, damit wichtige Seiten häufiger als weniger einflussreiche Seiten wieder und wieder gecrawlt werden . Wenn Majestic sich nur auf die Linkanzahl beziehen würde, um diese Entscheidungen zu treffen, dann würde die erforderliche Bandbreite deutlich zunehmen.
Entscheidung 2: Crawl Tiefe
Wie viele Seiten sind genug!? Ein verspammtes Verzeichnis hat mehr Webseiten als die BBC! Aber die BBC will alle Seiten regelmäßig gecrawlt wissen, richtig? Nun, nicht unbedingt. Die BBC produziert Nachrichten, die ihrer Natur nach alte Nachrichten werden. Irgendwann ist es keine Nachricht mehr und schließlich lässt sogar die BBC diese Seite fallen. Davor neigt die BBC dazu, die Seite verwaisen zulassen, damit man sie nur über eine Suchmaschine eines Drittanbieterlink findet. Das Problem wird noch komplizierter auf Websites wie eBay und Mashable, wo der Inhalt von Benutzer generiert wird und eine graue Linie zwischen Qualität und Quantität entsteht. Hier helfen Metriken immens. Andere Werkzeuge in der SEO-Industrie sind in der Lage, andere Taktiken anzuwenden, um diese Entscheidung zu treffen. Insbesondere können sie einen Proxy für “Qualität” durch das Ankratzen der Google SERPs in einem bestimmten Maßstab nutzen und dann mit einem Sichtbarkeits-Wert diese Entscheidung treffen. Ich habe keine Ahnung, ob sie das tun, aber angesichts der Tatsache, dass sie die SERPs-Daten im Maßstab betrachten, wäre es sinnvoll, wenn sie dies als Signal nehmen würden.
Aber letztlich müssen wir unsere Crawler vor allem vor dem unendlichen Internetproblem schützen. Wir müssen das Crawlen der gleichen Website (oder Server) so stark vermeiden, dass es die Wartezeit für echte Benutzer beeinflusst.
Entscheidung 3: Was ausrangieren?
Ich wollte diese Überschrift “Wie viele Festplatten muss ich kaufen” nennen, aber letztlich ist das nicht eine theoretische Entscheidung, die getroffen werden muss. Nachdem man verstanden hat, dass das Crawling-Problem unendlich ist, muss die Frage schließlich „Was kann ausrangiert werden” lauten. Welche Daten im Crawling-Prozess sind so nutzlos, dass sie von vorne herein nicht hätten gecrawlt werden sollen – außer vielleicht bei einem Versuch, andere schlechte Inhalte zu entdecken – mit dem Ziel, das Geschwulst aus den Daten zu entfernen. Das ist es, was Majestic in den letzten Monaten erfolgreich angegangen ist und die Effekte waren beeindruckend, um es gelinde auszudrücken.
- Wie wichtig werden Backlinks im Jahr 2023 sein? - February 23, 2023
- Was steckt eigentlich in einem Link? - October 31, 2022
- Ein Interview mit… Ash Nallawalla - September 13, 2022