






Une enquête récente d’Incapsula sur l’activité des robots a aidé l’auteur à récolter une compilation de pensées sur l’intérêt de crawler plus intelligemment plutôt que vite.
Incapsula conduit un rapport depuis plusieurs années maintenant. Les novices et quelques experts devraient être conscients que seulement la moitié de votre trafic provient de personnes réelles.
Cet article se concentre sur certaines des conséquences d’une course au crawl, son impact sur la qualité de l’Index et sur certaines tentatives spam pour frustrer les robots. Oui, je vais donc présenter une technique de réseau de lien. Une technique vraiment stupide pour envoyer un drapeau rouge.
Les bons robots et les mauvais robots

Tim Berners Lee et le Protocole…
Incapsula a identifié que la plupart du trafic mondial provient de 35 “bons” crawlers (en incluant Majestic) et d’un tas de mauvais robots pour lesquels nous ne porterons pas trop d’attention aujourd’hui.
Aussi, il est bon de noter que quelques parefeux particulièrement mauvais bloquent certains robots avec des user agents sans donner de sortie à leurs clients. C’est mal avisé. Voici l’impact relatif de chaque robot sur la bande passante globale de l’Internet.
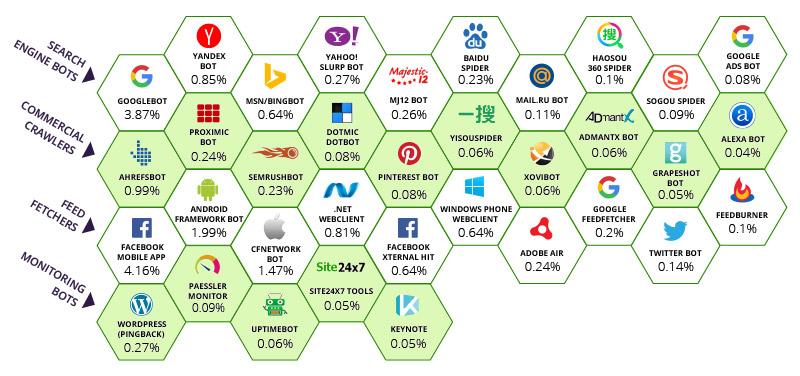
Source: Incapsula.com
Les nombres ci-dessous pour chaque robot représentent le pourcentage de visites vers les pages suivies attribuées à chaque robot. Tout en haut, l’application mobile de Facebook détient 4.16% de la bande passante. Google contrôle 3,87% de la bande passante mondiale. Et même plus lorsque vous regardez les autres robots détenus par Google. C’est assez juste. Google et Facebook ont été déterminant pour garder un système intégré, connecté et navigable autrement chaotique. Il est clair que la première rangée de moteurs de recherche partagent ce point commun, bien que Majestic soit reconnaissant envers Incapsula pour avoir catégorisé Majestic comme moteur de recherche et en haut de liste. Nous apprécions le fait d’avoir plusieurs pairs sur le rang deux et cela n’aurait pas été hors de propos d’y voir Majestic.
En tant que crawler du top 10, basé sur le tableau au dessus, Majestic a une responsabilité de savoir quand arrêter de crawler tout comme quand le faire. Il existe une clameur au sein de la communauté SEO pour recevoir “TOUS” les liens. Ou du moins autant que possible. Cela crée un paradox. Quand faut-il s’arrêter de crawler tout le web ?
L’infini du web
Les amusements récents impliquant Majestic et la station spatiale internationale n’étaient pas que publicitaires. C’est en partie pour mettre en avant la nature infinie de l’Internet. Cette infinité a de profondes répercussions sur les outils de lien. Quelques mois auparavant, Majestic a supprimé des milliards de pages web de son crawl. Ces pages étaient des sous-domaines générés automatiquement. Cela a causé un certain scandale au moment où quelques fournisseurs de domaines utilisaient le Trust Flow de la version www d’un domaine (ce qui est techniquement une variante de sous-domaine) pour évaluer les sites web et vendre le nom de domaine sur des marchés secondaires. La pyramide Lego aide à visualiser ce dilemme :
Imaginez que cette pyramide représente tous les sous-domaines de l’Internet. Ceux en haut de la pyramide ont un Trust Flow de 90-100 et ceux en bas de 0. Dans les faits, Majestic a trouvé que les sous-domaines en bas étaient au delà du zéro. Ils n’ont aucun liens entrants autre qu’issus du même domaine et ils sont si nombreux qu’ils ne sont même pas pris en compte pour le dernier échelon mais celui d’après. L’algorithme de TF de Majestic maintient quelque chose ressemblant à la forme pyramidale avec le moins bon en bas et les Trust Flow les plus hauts ou même toute chose mieux que du spam en haut. Parce que ce problème est sans fin, un crawler ne peut pas le résoudre en le crawlant simplement plus. Le seul résultat serait de paraître meilleur qu’ils ne le devraient et nous n’aurions toujours pas “tous” les liens car n’importe quoi divisé par l’infini ne représente toujours pas un pourcentage important.
Majestic pourrait avoir un serveur de la taille d’un terrain de foot et n’être toujours pas capable de résoudre le problème. Alors à la place, Majestic a décidé d’éliminer les deux derniers échelons. Dans la représentation lego au dessus, cela compte pour plus de la moitié des données ! (36 briques sur 70 = 55%). Chacunes d’entres elles étant une page qu’aucun être humain ne voit et qu’aucun moteur de recherche respectable ne crawlera jamais. L’effet a été de redimensionner la pyramide. Soudain, des sites qui étaient sur le troisième échelon d’une échelle de 0 à 100 sont passés au dernier échelon. Vous pouvez imaginer la panique générée dans la communauté des fournisseurs de domaines et vous pouvez presque le voir dans les commentaires de cette discussion.
Ce n’est pas la seule manière par laquelle l’infinie du web est créée. Majestic.com lui même (et n’importe quel moteur de recherche) crée des boucles potentiellement infinies simplement de part son but premier. Vous pouvez entrer n’importe quel ensemble de caractères dans Majestic.com et le système s’efforcera d’interpréter les résultats.
Cela crée en retour des SERPs (pages de résultats des moteurs de recherche) qui créent en retour des liens. Ces liens devraient maintenant lier à des pages qui existent déjà. C’est donc une boucle fermée mais l’url de recherche en elle-même peut être infinie par nature. Majestic (et Google) aide les autres moteurs de recherche à le détecter et ils font tous les deux usage de leurs fichiers robots.txt pour dire aux autres de ne pas gaspiller leurs précieuses ressources à crawler des URLs infinies.
Les spammers décuplent le problème
Le début de cet article indiquait qu’il “mettrait en avant une technique de réseau de lien”. Ce n’est pas quelque chose que je fais normalement mais ce réseau était particulièrement stupide et pernicieux envers le MJ12Bot. J’ai démarré l’article en montrant que les user agents sont optionnels. Majestic a choisi de s’auto-identifier. Si vous souhaitez que Majestic ne crawle pas votre site, utilisez alors le robots.txt pour donner ces instructions. Ne cherchez pas, comme l’a fait ce réseau de lien, à rediriger en 301 le robot de Majestic vers sa propre page d’accueil. Résultat, j’ai reçu un email d’alerte très intéressant dans ma boîte mail, me montrant un afflux massif de liens vers Majestic.com :
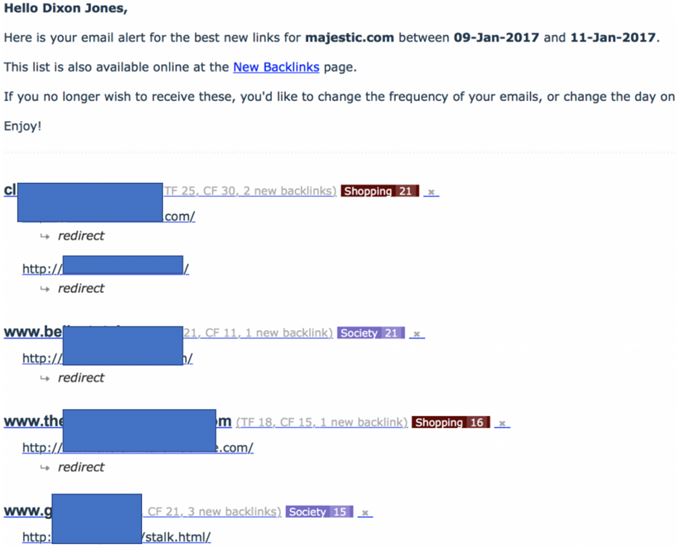
Notez que tous ces nouveaux liens trouvés vers Majestic.com étaient apparament redirigés depuis ces sites web. Ils ont fait office de drapeau rouge car lorsque j’ai regardé ces sites, j’ai clairement eu affaire à des fermes de liens mais qui ne liaient pas vers Majestic. Cela signifie qu’ils ont dû dissimuler le MJ12Bot (en cachant le contenu de notre robot). J’ai été particulièrement amusé lorsque le réseau a commencé à utiliser des noms de fichiers comme “stalk.html”! En regardant ces pages sur un navigateur normal, elles ressemblent toutes à cela.
Les User Agents sont optimaux
La dernière étape pour déterminer ce qu’il se passait a été d’utiliser un outil tierce pour vérifier que le réseau faisait une redirection 301 basée sur l’user agent. Si vous consultez le “http header checker”, vous pouvez le faire vous même mais il est particulièrement utile d’utiliser le Header Checker de SEOBook ou Screaming Frog car ils vous permettent tout deux de changer l’user agent. Pour faire simple, ces sites étaient dissimulés par des user agents. Si le Googlebot ou un humain arrive, ils verront alors les pages ci-dessus. Si le MJ12Bot arrive, il verra le propre site de Majestic via une redirection 301.
Un retour vers les crawlers responsables
Le réseau souligne un challenge. Il pousse un crawler à regarder deux nombres IP et non seulement un. Ce n’est peut-être pas significatif dans le cas présent où un seul site est spam et l’autre est celui de Majestic mais cela montre que les redirections 301 ne sont pas parfaites. Elles ont un poid en augmentation sur Internet. Une façon plus intelligente de rediriger serait d’utiliser un nom de domaine alias mais cela cause d’autres problèmes pour les moteurs de recherche car le domaine canonique (le préféré) ne peut être identifié depuis les tableaux dns seuls.
Avec les webs infinis et potentiellement des redirections porteuses et avec toutes les autres manières de retenir l’efficacité d’un crawler, il devient illogique de continuer d’essayer de crawler le spam… même s’il s’agit juste d’éliminer les liens spam. Une approche bien plus pratique serait de rassembler assez de données à propos d’un site pour voir certains liens de chaque domaine et ainsi avancer. L’astuce étant de ne pas redécouper les déchets mais s’ils sont au niveau de page avec des pages infinies ou à un niveau de sous-domaine avec des sous-domaines infinis ou au niveau de page avec des duplications similaires infinies, des résultats de recherche et des redirections.
Pour ce faire, les crawlers pouvant crawler de façon plus intelligente sont capables de mettre moins de poid sur le web que ceux qui crawlent très vite. Crawler intelligemment fonctionne si un crawler est capable de comprendre n’importe lequel des facteurs suivants :
- Est-ce une page importante ?
- Est-ce mis à jour ou statique ?
- Est-ce auto généré ?
- Est-ce du spam ?
Majestic est en particulier bon pour les premières et dernières observations. Les Flow metrics donnent à Majestic un avantage par rapport aux autres robots et en particulier comparé au BingBot. Je crois que le BingBot est plus aggressif que Majestic mais je ne suis pas si sûr qu’il devrait l’être. Peut-être que Bing n’a pas un nombre si pure comme le Trust Flow ou le PageRank (oui ils les utilisent toujours) pour aider le processus de crawl. Mais je ne crois pas qu’ils découvrent significativement plus de pages s’ils crawlent 250% plus rapidement que le MJ12Bot. La même chose prévaut pour nos paires du deuxième niveau du graphique Incapsula.
La meilleure approche, pour Majestic du moins, est de crawler assez pour être capable de trouver tous les domaines racines référents pour lier vers un site et ainsi montrer assez de backlinks d’un site pour que nos utilisateurs soient capables de facilement identifier la nature du schéma de lien. C’est une façon très simple pour les utilisateurs de le voir dans l’onglet de domaines référents. Rentrez votre domaine et triez par nombre de backlinks, descendez et vous verrez le nombre de lien par domaine. Vous serez capable de recevoir des informations immédiates. Voici le propre site de Majestic.com :
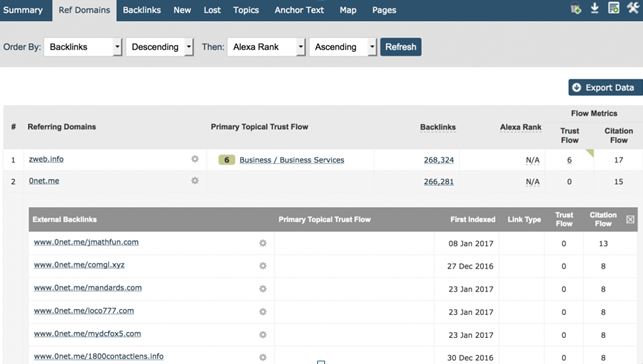
Je pense que nous sommes tous d’accord pour dire que 266 281 liens en provenance de www.Onet.me ne nous disent pas grand chose de plus que 100 000 liens de www.Onet.me !
L’onglet domaine est parfait pour identifier rapidement certains des pires liens spam de votre site. Il est aussi utile dans cet article pour identifier des zones où un robot pourrait devenir encore plus intelligent et efficace pour son crawl.
Des hébergeurs peu chers sont une menace

Un autre problème que les robots agressifs peuvent causer est lorsque qu’il a de trop nombreux sites web sur un même serveur. Malheureusement, les hébergeurs de mauvaise qualité pensent que les robots sont un problème plus important que les hébergeurs robustes. C’est parce que les hébergeurs premier prix ont tendance à mettre des centaines, voir des milliers, de petits sites web sur le même serveur web physique. (Vous pouvez utiliser le Neighbourhood checker de Majestic pour voir combien de sites sont sur votre serveur).
Majestic obéit à un délai de crawl dans le robots.txt mais il devient également plus intelligent à propos des types de sites sur ces serveurs. Cela vous importe également si vous vous souciez de Google. Le Googlebot n’obéit pas à un délai de crawl ! À la place, ils utilisent une limite globale par serveur pour déterminer le taux de crawl maximum pour cette machine afin de ne pas causer de stress non nécessaire sur le serveur. Si votre site a 1000 autres sites, certains avec des milliers de pages en plus que le vôtre, sur le même serveur, vous devez vous demander quelle portion du crawl du Googlebot sur votre serveur regardera réellement les pages sur votre site ?
L’arbre de décision pour un crawler plus intelligent
Nous avons maintenant un nombre d’éléments suffisant pouvant aider un crawler à mieux gérer ses propres ressources et ainsi réduire l’impact sur Internet. C’est une quête qui crée une situation gagnante gagnante. De meilleures données. Un Internet plus rapide.
Décision 1 : Découverte vs Intégrité
Afin de maintenir un index web de la taille de Majestic, le temps détruit naturellement l’intégrité. Toutes les secondes qui passent, un nouveau contenu est créé mais du contenu déjà existant est également détruit ou modifié. Imaginez cela en une demi seconde…Majestic a le choix de ce ce qu’il va crawler en suivant… une URL qu’il n’a jamais crawlé auparavant ou une qu’il a crawlé la veille ? Que choisit-il ? La nouvelle ? Super ! Quel comportement avec le choix suivant ? ou celui d’après ? Nous avons déjà identifié le concept de web infini, cette logique est donc imparfaite si vous ne vérifiez jamais qu’une page a changé ou chuté. Majestic a réglé le problème en 2010 et l’a ainsi résolu de plein des manières.
Si les robots de Majestic passent outre le côté existant de la découverte, en opposition au pendant de l’intégrité, il existe alors une sécurité-défaut dans le Fresh Index car après 90 jours une page qui n’a pas été recrawlée serait complètement écartée de l’index. Cela veut dire que le Fresh index n’aura jamais de données plus vieilles que de 3 mois. Malheureusement, cela arrive rarement…du moins pas avec les pages dont les visiteurs se soucient vraiment…car nos flow metrics nous aident à prioriser de façon plus nuancée afin que les pages importantes puissent être revisitées plus souvent que des pages moins influentes. Si Majestic se reposait seulement sur le nombre de liens pour prendre ces décisions, la bande passante nécessaire augmenterait de façon significative.
Décision 2 : Profondeur de crawl
Combien de pages sont assez ? Un annuaire spam a plus de pages web que la BBC ! Mais il est certain que la BCC a besoin que toutes les pages soient crawlées fréquemment non ? Et bien pas nécessairement. La BBC produit des actualités qui, par nature, deviennent obsolètes. Elles ne sont même plus d’actualités du tout à un certain moment et même la BBC abandonne la page. Avant cela, la BBC a tendance à rendre orpheline la page afin que vous ne la trouviez que via les moteurs de recherche ou un lien tierce. Le problème devient encore plus compliqué sur des sites comme eBay et Mashable où le contenu est créé par les utilisateurs et où une ligne grise se dessine entre qualité et quantité. Ici, les flow metrics aident grandement. D’autres outils dans le secteur SEO sont capables d’employer d’autres tactiques pour prendre cette décision. En particulier, ils peuvent employer un proxy pour la “qualité” en scrappant les SERPs de Google à l’échelle et ensuite en utilisant un score de visibilité pour aider à prendre cette décision. Je n’ai aucune connaissance interne sur comment ils procèdent mais en prenant en compte ce qu’ils regardent sur les données de SERPs, cela ferait sens s’ils comptaient cela comme un signal.
Mais finalement, nous avons encore une fois besoin de protéger nos crawlers du problème de l’Internet infini. Nous devons également éviter de crawler le même site (ou serveur) si souvent que cela affecte la latence pour les vrais utilisateurs.
Décision 3 : Quoi jeter
J’allais proposer ce titre : “Combien de disque durs acheter” mais finalement ce n’est pas une décision théorique qui doit être prise. En ayant compris que le problème de crawl est infini, la question doit plutôt être du genre “Quoi jeter”. Quelles données dans le crawl sont si inutiles qu’elles n’auraient pas dû être crawlées la première fois, excepté peut-être dans une tentative d’éradiquer d’autres contenus de mauvaise qualité, avec l’envie de supprimer le cancer des données.
C’est ce que Majestic a abordé avec brio ces derniers mois et les effets ont été impressionnants pour le moins que l’on puisse dire. Dès que cela devient un facteur, alors la quête pour un crawl plus rapide devient irrationnelle.
- Nouvelle fonctionnalité : Liens sortants et mise à jour des langues - October 26, 2017
- Nouveau : Métriques de lien sortant avec titres et plus encore - October 16, 2017
- Majestic et SEMRush unissent leurs forces - October 11, 2017