





Majestic has done some Spring Cleaning this Autumn.
(It’s spring down under)
We’ve been doing some pretty cool back-end stuff to improve our systems. We didn’t think anyone would notice, but a few did. If you noticed, that might not be a good thing for you if you are tracking your own sites, but we thought it best to give you some of the background. I can’t give it all away though!
Majestic has found a way to improve its index quality – particularly at the Subdomain level. We have achieved this without removing any CRAWLED urls from our index, but we were able to identify some truly unbelievably spammy PBN (Private Backlink Networks) that went way beyond general link manipulation and into the realms of trying to flood a web index with stuff nobody would see or use.
…so we deleted them…
…and banned the sub-domains…
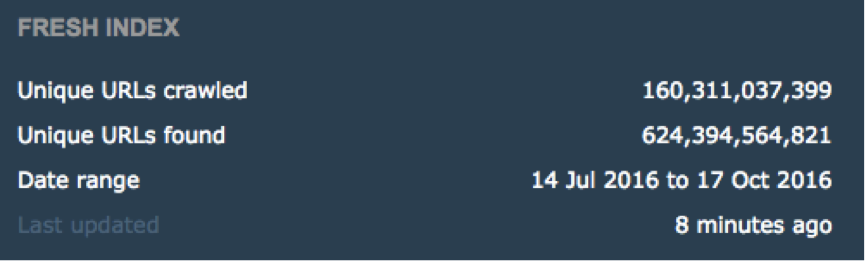
The long and short… our Fresh Index “URLs Found” table now has half the “Found URLs”, but the SAME number of “URLs crawled” as it had before.
HALF the (crawled) URLs were simply trying to send bots in circles!
How Much Data is That?
There was a spam network… maybe more than one… which was getting absurd at the sub-domain level. We can live with a bit of spam here and there, but these sub-domains were all REALLY bad.
On the 12th October we had 473,173,079,983 sub-domains in our Fresh index. By the 17th of October we were down to 57,956,672,821 and we think that when this is all said and done, we may have dropped 50% more!
Anyway – these are now not in the Fresh Index. If you aren’t involved in anything shady, you probably didn’t notice… EXCEPT if you compare sites at the sub-domain level (more about that below). The backlinks counts to your websites will not have changed (Since we deleted low value pages we never crawled anyway), although, over time, we probably won’t crawl some of the backlink pages we had previously crawled ever again, because we’ll have a better crawl methodology moving forward. Eventually the worst of the URLs will be confined to the Historic Index, allowing the Fresh Index to find better data.
If my Link Count didn’t change, why has my TF?
If you are finding that your Trust Flow has dropped wildly, then this MIGHT be because you are looking at the www. version of your site, not the Root or the home page.
It is up to you which level to choose, but if you CHOOSE www then you are comparing your site with every single other sub-domain in the world. The TF score is a normalized score of all these sub-domains (so very few with 100, lots with zero). Since we have removed around 90% of all sub-domains, you can imagine the re-calibration is pretty significant! Because we removed a lot of REALLY BAD stuff, then this will mean that a lot of sites actually have TF going DOWN because we are now comparing your site against a set which is generally of better quality. Of course, if you are at the top of the pile, then you may have found your TF actually going UP at the sub-domain level.
Why does Majestic have so many versions of TF & CF
This is a criticism that gets thrown at us all the time. People just want ONE TF score, regardless of whether they enter a page, a subdomain or a root domain. We could if you like, delete all the other metrics except the page level… but then you wouldn’t have domain level information. We could just get rid of the subdomain level… but then how would you compare Blogspost sites? Whichever way you look, there are times you need each one. The important thing is not to compare different types. Never compare Subdomain level metric with a URL or Root domain metric.
If you are buying or selling domains, don’t evaluate at the sub-domain level if you are buying a Top Level Domain. There. You have been informed.
Did you do anything else to your Algorithms?
Since we are here, it is worth saying that we are beginning to understand why the search engines don’t talk about this stuff much. Some of you will have noticed that some third party tools that steal our data don’t work so well now. You’ll have to ask the people stealing our data about that. I would recommend that you only trust tools that are listed either at:
https://blog.majestic.com/majestic-seo-partners/ or
https://blog.majestic.com/majestic-seo-partners/openapps-directory/
Or ones using your own API keys (which you should keep secure!)
We also have made other improvements lately to our crawl methodology. In theory this won’t change anything fast, but should improve our data over time. Let’s see!
- How Important will Backlinks be in 2023? - February 20, 2023
- What is in a Link? - October 25, 2022
- An Interview with… Ash Nallawalla - August 23, 2022
How are you supposed to compare 2 websites if one is using www. and other is just on the root? You cannot?!
October 17, 2016 at 5:27 pmCorrect, you cannot. It is Apples and Oranges. You can EITHER compare them both at the root level (because that will aggregate the info from every link) or you could compare the Home page of each one, because then you will compare link info to each home page. If you compare (say) ebay.com/widgets with www.widget.com and widgets.blogspot.com then you are asking the real world equivalent of "Which of these apples is more juicy, the Orange or the banana?".
Search engines generally return URLs, not domains. SEOs tend to look at domain level data (or subdomain level data) because it is more manageable. Blogspot is a good example to demonstrate why that model breaks down at scale.
October 17, 2016 at 5:36 pmBut your data does not ‘aggregate the info from every link at the root domain’. If it did correctly you would never have www. version having higher Trust Flow than the root. The root domain should always have the highest trust flow metric.
I’d be happy to compare just the root domains of sites but you end up getting very misleading data if one of the sites is using www. Basically you can no longer use majestic to compare 2 sites, which is surely what the software is for??
October 18, 2016 at 9:44 amYes, it does aggregate. However – this is exactly WHY you cannot compare www with non www. Let’s say there are 400 million TLDs on the web, all with different total values (Not TF scores, but Before the scores are normalised). We then normalise these 400 million data points into numbers from 0-100 at the TLD level.Now let’s say there are 57,956,672,82 sub-domain scores (not TF scores but internal scores before they are normalised). We then normalise 57.9 BILLION data points into numbers from 0-100. See? Apples and bananas. >>you end up getting very misleading data if one of the sites is using www<< YES! DO NOT COMPARE SUB DOMAINS WITH ROOT DOMAINS! You make the point vary aptly.
October 18, 2016 at 11:02 amI’m not sure if this is a part of the algorithm update or not, but I’ve been noticing back links being labeled as "deleted", however the link and anchor texts are still live.
Are those back links part of the "stuff you never crawled anyways" or it is a possible error on your end?
Thanks!
October 17, 2016 at 7:20 pmNot directly related, but you’d need to first understand the reason why we marked it deleted. It is likely (if the link is still there for you) that our bot was unable to get back to the page in question, in which case we have to assume that the links on that page are also irrelevent/deleted. More on why you should let Majestic crawl your site <a href="https://blog.majestic.com/general/verifying-site-majesticseo-every-seo-audit/">here</a>.
October 17, 2016 at 10:54 pmWhat about blogs like using Web 2.0 platforms? Like i have my own network of expired tumblr which has great Trust flow before this update. Now i am seeing those are useless. What indication will i use to check the web 2.0 properties. Because those are subdomain also. Please anyone put some point on it.
Thanks a lot.
October 17, 2016 at 10:19 pmHi Sany,
October 17, 2016 at 11:04 pmWhen you say the Tumblr sub-domains were great before the update, under what measure? Our metrics at the sub-domain level (including Tumblr sub-domains) are far more representative of a human interpreted reality than they were previously. I am very happy to admit that it is likely that Tumblr sub-domains lost value on average in this update. I am moved to ask… what are you doing with a network of Tumblr sub-domains? When that is answered, look at sites at the sub-domain level now that have higher TF scores than yours and honestly ask yourself whether your Tumblr domains are "more trustworthy". I’m not trying to be facetious, I am just saying that most businesses didn’t even notice that we had killed off over 400 BILLION subdomains. Tumblr ones were NOT amongst the ones removed, so yours are still there, but now it is easier to see which sub-domains stand out.
Hello Dixon,
Got the point. Thanks a lot for clarifying this fact. I am using tumblr network to rank my couple of sites. Yes few blogs TF is dropped significantly and i removed those from my list. Only those are remain which has a good no of links and average TF.
Anyways you guys just killed some people’s so called high powerful PBN business.
October 18, 2016 at 9:50 pmHi Sany,
October 18, 2016 at 10:01 pmThanks. I guess we probably did and sorry if I sounded abrupt. That wasn’t the aim. The aim was to improve our view of what’s important in the Internet world. But I guess that happened too. At least if people buy and sell domains now, they are a little better informed I guess. Also, we can use the hard drives (and I’d guess there are many!) for more productive purposes than storing spam.
Great job, thanks for these informations.
Dixon, can you please make things cleariest about this statement ? :
"If you are buying or selling domains, don’t evaluate at the sub-domain level if you are buying a Top Level Domain. There. You have been informed."
People might thinks that subdomain metrics are totaly useless.
Lets talk about expired domains for exemple. Assume we are (for SEO purpose) interested in 2 expired domains, and we must choose between them.
Going back to the past, we notice that the first domain name was redirecting to the www subdomain and the second was directly on the root.
It’s obvious that the first one has his relevant backlinks pointing on the subdomain. But if we take a look to his root metrics, we find interesting things.
The root obviously has always more refering domains than the subdomain, and if we look better we can see that a lot of these backlinks (that are pointing to the root) comes from scrapy websites, whois, seo statistics and all this kind of stuff.
Almost of these referals having very low metrics, makes our root metrics lower to. right ?
Asuming that Google most probably ignores these backlinks (and what we need is to rank on Google not on Majestic), don’t you think is better to look at the sub domain in that case ?
If yes, we have now another problem. Analysing the first expired domain, if we can choose to look at his subdomain metrics, we can’t do the same for the second. Also if we could, as you said we can’t compare bananas and apples.
Is it a good idea to evaluate the first on the sub domain, and the second on the root… but of course against different criterias. (stupid exemple: If ex root >= 20, and if ex subdomain >= 35) ?
Thank you
October 18, 2016 at 2:39 pmHi Antoine. Sub-domain metrics are not useless. They are good for comparing to similar sub-domains.
For example: https://rowadelmadina.wordpress.com/ with http://bastille.tumblr.com/ but let’s be honest, they ARE useless for buying a domain, because – and this I cannot emphasize enough – you are not buying a sub-domain! If you are choosing between two expired domains, use the DOMAIN level! That’s what you are buying/selling. If you find links redirecting to the www, then that juice ALSO directs into the root domain. Just because the root domain looks like a lower score does not mean it is of lower value. Would you rather own ebay.com or "yourshopname.ebay.com"? I ASSUME you would rather the multi-billion pound company that owns the ROOT domains, because they ultimately also control the sub-domain.
You CAN NOT compare a Trust Flow of a www to the Trust Flow of a non WWW. I don’t know how many other ways I can explain the apples and oranges idea. One data set seeks to "order" a set of 400 million (that number is made up) domains so that the best gets 100 TF and the worst get zero. The OTHER data set (totally different) has now 57 Billion sub-domains and also puts them into a list with 100 TF at the top and loads with zero TF at the bottom. So 57 Billion – 400 Million = 56.6 BILLION subdomains are underneath the 400 Million subdomains that represent the "best variant" of a sub-domain. so YEAH – it is pretty easy to inflate a www to look a load higher than the root, because it is at the top of a very big, very poor pile of other sub-domains, so the relative number between 0 and 100 is higher.
In terms of Google, It is best to understand that they rank pages. Not websites.
(In fact they have now gone further and understand entities which transcend websites, but let’s please save Entity search for another day.)
If you really want to buy a site because of its potential to influence Google then firstly – that’s your risk, not Majestic’s recommendation (we are a map of the Internet, a specialist serach engine, not a consultancy) but also, you should look at the pages tab in Majestic and see the breadth and quality of content on the site and consider the TF of each individual page in context, because it is each page that ranks, not each site.
Your last question: “Is it a good idea to evaluate the first on the sub domain, and the second on the root… but of course against different criterias. (stupid exemple: If ex root >= 20, and if ex subdomain >= 35) ?”; NO. Why? because you cannot compare a subdomain with a root domain. There is no mathematical correlation between these two data sets that would be consistent. If you HAVE to compare www.siteA.com with (non-www) siteB.com then I would add a trailing slash/ and just compare the home pages of these two, because… even though it is a third data set, you are at least comparing a page with a page. Or – just look at the links themselves and engage Brain 1.0
I’m not trying to blind everyone with maths here. They are different data sets. Pretending they can be mapped is to fundamentally misunderstand how Flow Metrics work.
October 18, 2016 at 5:22 pmWorst update I must say.
Rip Majestic
October 18, 2016 at 4:47 pmThere’s always a few unhappy people – but no – It is simply maths. Just because it doesn’t appeal to people selling domains based on sub-domain metrics doesn’t make it worse and "worst" isn’t even grammatically correct I am afraid.
October 18, 2016 at 5:32 pmWorst was correct in his context. Just FYI lol.
November 4, 2016 at 7:51 pmIs there any intention of releasing which subdomains you removed? i.e. Blogspot and WordPress.com are often abused, however, there are tons of great sites on there as well and if you’re banning subdomains on those types of platforms I think we should know that.
October 18, 2016 at 7:53 pmWe didn’t block any WordPress, Tumblr or Blogspot sites. They were FAR too good for the stuff we removed! 🙂 – I don’t think we have any inclination to go further, but I would be surprised if a human even noticed the dross we removed.
October 18, 2016 at 8:20 pmGood deal, thank you.
October 18, 2016 at 9:28 pm@Dixon
October 19, 2016 at 3:46 am1. I don’t sell domains, I am a buyer and I must say i really picked some shitty domains because of your highly inaccurate metric.
2. English is not my first language. Enjoy your internet brownie points.
3. You know your metrics are inaccurately when wikipedia.com has a trust flow of only 33.
Hi Glen. The metrics are very useful when correctly used. For example, Wikipedia primarily operates on the TLD Wikipedia.org. Currently that has a Trust Flow of 99.
[Add] I apologize for correcting your grammar. I am constantly amazed at people’s ability to master a second language. I am also sad if you have been sold domains based on sub-domain metrics. This algorithm change and this post should help to change this moving forward – but it always makes sense to look at the underlying data to understand the links that help to craete the metrics. Otherwise a domain seller would simply 301 redirect their best links to sites for sale purposes, then remove the 301 after the purchase.[/ADD]
October 19, 2016 at 8:29 amIs Majestic now going to automaticaly remove such spam content form its database ? Or is this cleanup only done on manually selected spam-networks ?
October 19, 2016 at 12:54 pmHi Heinrich, Over the next 90 days or so there I would expect a much milder realignment at the sub-domain level as pages crawled on the network pass through the Fresh Index. The network is unlikely to come back into the system, but I cannot say what we will be doing with spam moving forward I am afraid.
October 19, 2016 at 4:31 pmHi Dixon thank you so much for this answer.
I understand that we can’t compare root and subdomain, this is clear, it’s not the same stuff.
Take a look at this extreme ase (quiet impossible maybe)
WWW => TF 40 CF 40
Root => TF 11 CF 22
This domain is probably not that so good deal right ?
October 19, 2016 at 7:36 pmWell I would ignore the 40/40 as I could not possibly tell.
At the same time, TF11 at the root is starting to show signs of life. It’s fine for a personal blog, but bad for a big corporate.
My guess? (It is a guess based on JUST the Flow metrics…) on the whole a TF 11 is a one man/woman band usually. The CF 22 suggests to me that it’s probably more a virtual thing than a "bricks and mortar real life entity" thing, but TF 11 can be achieved with just one or two decent links, so – like everything – TF is a guide. The real understanding is in looking at the links and/or the quality of the people visiting. Not just the quality – but the relevance if those people to your business. Then again, the last domain I bought was Majestic.com… which had a TF of about 11 at the time and we spent a LOT of money.
A site with Root TF 11 is still in the top 2% of all domains on the planet though (by our maths)! Which probably helps to demonstrate just how much dross is out there that we have to trawl through to find ANY signs of life.
October 20, 2016 at 10:04 amHi I you say here that Majestic is deleting backlinks to domains if they cannot reach the URL that the backlink points to:
"Not directly related, but you’d need to first understand the reason why we marked it deleted. It is likely (if the link is still there for you) that our bot was unable to get back to the page in question, in which case we have to assume that the links on that page are also irrelevent/deleted."
Doesn’t this kind of kill Majestic for people that use it to find the metrics of expired domains? For example wouldn’t the metrics of an expired domain drop drastically since you are deleting backlinks to it regardless if they still exist or not?
October 19, 2016 at 7:57 pmHi Zach,
October 20, 2016 at 9:42 amThat was in response to Jon’s specific question. This feels like Matt Cutts of old, with the world trying to think around every word that’s said to find hidden meaning! 🙂 (Including me… I do that too!). But no. We will still record the link to a page… although if page does not load for us (the target page) then we have to also assume that all the links previously on the page do not pass Trust Flow anymore and are effectively broken.
Dixon, any way you can share what kind of terrible blog networks you deleted from the index. I’m just curious more than anything.
Are these old school 1999 style blogs with 10,000 plus links on each page?
October 20, 2016 at 4:27 amIt was primarily an Asian based spam. May have been targeted at manipulating Baidu, I have no idea. Whatever it was, it was WAY worse than anything that humans actually care about. None of it was Blogspot, WordPress, Tumblr or any of that sort of thing. Way poorer! By removing it all, this recallibrated the sub-domain level scoring. So nobody’s site get better or worse… the maths just measures the subdomains with a different yardstick now.
October 20, 2016 at 9:32 amFor those who still need some explanation as to why you can’t compare TF of root and sub-domains:
October 20, 2016 at 9:02 amhttps://blog.majestic.com/general/the-difference-between-root-domain-subdomain-and-url-level-explained/
Thanks Emily! Good to know we we talked about this before. We also highlight it when people try to mix these up in bulk back-link comparisons.
October 20, 2016 at 9:24 amHi Dixon,
We’ve seen an increase of "deleted" backlinks in Majestic on our site, when the website are fully available, as usual I would say.
October 20, 2016 at 9:46 amI can understand a few errors there and there, but the proportion has drastically increased those last days. Is there any known robot malfunction lately that could explain this behavior?
You should take that to a support ticket please, Clement. The bot seems to be finding links fine. For example, in the <a href="https://majestic.com/share/1f5f6be480e7ea5caae5bc5acfae67ae">Majestic in Space campaign</a>, we see as many links to the NASA site as we have ever seen. Miss Universe seems to be losing links – but most are going up. There are no problems that I know of with the bot.
October 20, 2016 at 10:13 amHi Dixon, it’s great to have clear answers thank you !
Do you think that the following stuff could help us in dealing better with flow metrics :
You just told me that a domain with TF 11 is still on the top 2% of the domains in the planet, that’s maybe a strategic data that we can access too.
Espacialy when dealing with topical Trust Flow. It’s interesting for me to know if the mean of Computer Science Trust Flow is higher than the Food Trust Flow
At the same when i m looking for a domain it could be great to know that is in the top 2 % of all the domains on the web, and in the top 12% of the domains relying on a particular topic. Right ?
October 20, 2016 at 10:51 amHi Antoine,
Thanks! It’s hard to get the balance between being open and blowing everyone’s minds because this isn’t an excel spreadsheet! 🙂
Actually – I had to go and ask some Hadoop boys to confirm it was in the top 2% before I posted it. We look at the way in which the different topics "decay lines" (I made that word up) correlate. This is way off the thread, but the REALLY keen could go and have a look at one tiny snapshot example – a 2015 snapshot of the <a href="http://labs.majestic.com/2015/social-explorer">top 10 Twitter profiles in each topic</a>. Look at the visualization and hover over the various categories and you’ll see the approximate percentages for that tiny dataset (yes, Twitter is tiny in the greater scheme of thongs). I have no idea whether this would be similar at the root domain level – probably not – but imagine that X 400 million and you’ll get why we haven’t worked out the answer to your question about whether the mean of Computer Science TF is Higher than the Food Trust Flow.
I can’t go further answering the topical data line of questions here. Not because I don’t love talking about it, but because for every person that understands it, there will be 10 that ask another question. Hope it has helped, Antoine.
October 20, 2016 at 5:30 pmThe title of this article is appropriate — Yo-yo.
I do dozens of monthly reports for our clients. In almost all cases, TC flow scores in September were higher by a significant amount. Then, this month (October), those same scores are down by a similar amount.
Obviously, this is not a good thing from a monthly reporting standpoint.
I will be moving to another, more reliable service.
October 20, 2016 at 2:20 pmHi Frank,
October 20, 2016 at 4:36 pmI do hope that you choose to reconsider. The reason your scores (AT a Subdomain level only) may have gone up could well be because someone in Asia created 500 BILLION extra subdomains, which were all rubbish. That means your subdomains (and everyone else’s) are relatively better, compared to the whole data set. When we took them all out of the list, the entire Sub-domain data set is recallibrated.
Hi Dixon
October 20, 2016 at 10:54 pmGreat article 🙂
I have a little question, if we have 2 expired domains : domain1 and domain2,
domain1 Was Directly on the root.
domain2 Was redirecting to the www subdomain
they receive exactly the same backlinks (backlinks pointing on the subdomain for domain2 and pointing on the root for domain1)
So, if we compare the TF root for both domains, it will have the same TF root?
or TF root domain 1 will be superior than TF root domain2 ? (assuming that both domains receive identical backlinks)
Hi Ronaldo,
October 21, 2016 at 10:45 amGreat question and in THEORY I think the answer is *nearly* yes – if the links came from the same a pages as each other. It is only a theoretical example though and would never likely happen in practice. There are many other nuances that would affect things though… whether there are 301s, the internal link structure, whether our crawler followed all the links in equal measure or even crawled them at the same time (which it can’t do as links are not all crawled in parallel.) Whether we can reach the target pages in timely manner and from there, how the site’s outlinks are constructed will affect internal page TF on each site.
Hey Dixon, can you guys maybe add a tab called "Highest Domain Trust Value" or somthing along those lines that way we could get a quick glimpse at what metric the domains is that have the highest metrics instead of having to flip threw www. version and root and URL?
Maybe combine the three and out of the highest display that in the tab labled "Highest Trust Value"
October 21, 2016 at 2:21 pmHi Bill. No – that would be wrong to do. As this thread tries to explain, you can NOT "combine" all three.
October 21, 2016 at 3:32 pmAlthough, that said, you might be onto something there… We have all three shown in the toolbar. Maybe we can think about that idea a bit more.
Today there is a huge DDOS taking down half the interwebs (http://gizmodo.com/this-is-probably-why-half-the-internet-shut-down-today-1788062835).
If the Majestic bot can’t crawl these sites how would that affect the fresh index? I’m sure there must be a "The Interwebs is custard today lets not update" feature ??
October 22, 2016 at 4:08 amSlightly uncharted territory, but important links will just get seen again when everything calms down. Could explain some blips if they occur though.
October 25, 2016 at 7:31 pmHi there– it might be useful if you covered (maybe in a future blog post) things people could do to INCREASE their TF if they see that it has dropped. Just a thought.
November 2, 2016 at 11:52 pmHello again,
Thanks so much for answering my previous question, I really appreciate it! I have another question regarding trust flow and the way it "flows" through a websites internal link structure.
Let’s say I want to view the URL version of the root domain (http://domainlove.com) and its metrics are 25/30 tf-cf. In theory, if I put an external link on that page, the backlink that page would receive would have the same metrics (25/30 tf-cf).
Would this be the same if I made an internal link on that same page? I’m aware that you currently don’t track flow metrics for internal links, but I’d like to know if it’d still work the same way.
Thanks
November 4, 2016 at 1:28 pmYes, Trust Flow passes through most internal links. This means it is entirely possible (and common) for pages with zero external links pointing to them to still have Trust Flow scores, due to internal site links.
November 5, 2016 at 1:01 pm