





On Thursday, Majestic’s October historic index was updated. No trumpets or fanfares, just a record breaking index of 3.4 trillion URLs. Here are the bare stats:
Historic Index |
|
|---|---|
| Unique URLs crawled: | 862,978,364,744 |
| Unique URLs found: | 3,395,758,635,853 |
| Date range: | 16 Feb 2010 to 18 Sep 2015 |
| Last updated: | 14 Oct 2015 |
Nearly 3.4 trillion URLs were found and stored in the index. That compares to 730 billion in the Fresh Index.
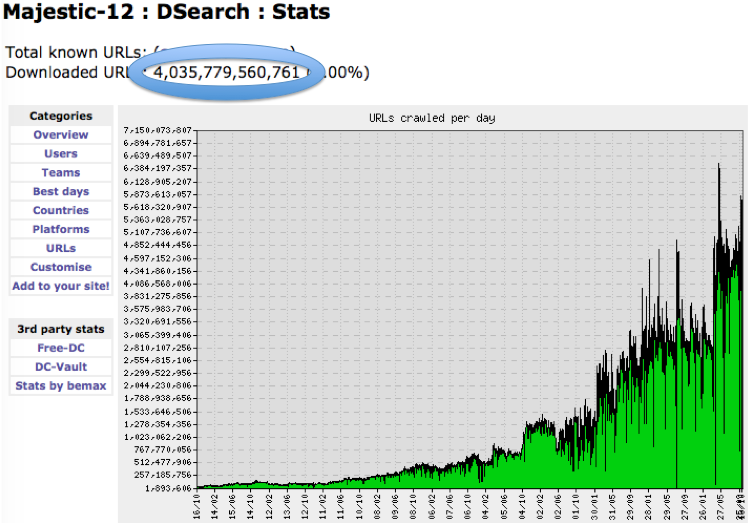
During the month I also had cause to look at the total number of URLs that we have downloaded, since we have started crawling the web. It was something I noted, because it was just hitting the 4 billion mark, so I thought this might be a good time for a short refresher on what all these numbers mean.
Fresh Index vs Historic Index
The Fresh Index covers any URL we have seen over a 90 day cycle. So it INCLUDES old URLs, not just new ones. The number of URLs is NOT the number of links. Every URL could easily have many links on them to external websites, so if we crawl a page, we will record all these as well. At the same time, there will always be URLs that we know about, but have not yet crawled. If you think about it, this always has to be the case if you assume that any page you crawl has a link on it… At some point you either run out of time or out of pages on the internet. We all know that the second thing is not going to happen any time soon because new URLs start appearing all the time.
So what else is in the Historic Index?
With the Historic Index being SO much larger than the Fresh Index, it helps to know its advantages and limitations. The Historic Index includes all the pages we have crawled over many years. However, just like the Fresh Index, if we see a page has dead links, we will flag those links as deleted. Unlike the Fresh Index, deleted pages will not drip out of the system. We keep that data for posterity. A little like Archive.org for links.
If the Historic Index has 3.4 trillion URLs, what is the 4.0 trillion?
The 4.0 trillion milestone is the total number of crawled URLs. Many are duplicates, so this leaves 3.4 trillion unique URLs. As you can see, we are now crawling close to 6 billion URLs A DAY. Some of these will be the same URL multiple times. Because Majestic has such a strong grasp on what is a good URL and what is just spam, we can use this to help direct and prioritise our crawlers. This efficiency decreases the load on the Internet and on websites.
So how many links are in the system?
Honestly? It is not something we publish. Much more than any of these other numbers though.
- How Important will Backlinks be in 2023? - February 20, 2023
- What is in a Link? - October 25, 2022
- An Interview with… Ash Nallawalla - August 23, 2022
wow didnt realize there were so many, i thought the total was around the trillion mark
October 21, 2015 at 2:37 pmOhh.. how did you guys managed the initial traffic ??
October 25, 2015 at 5:57 pmTraffic <> crawl velocity.
October 26, 2015 at 1:07 pmwoowwwww plz put the link of download
October 31, 2015 at 1:46 pmI have to ask… How big do you think that download would be in MegaBytes? 🙂
November 9, 2015 at 5:09 pm