





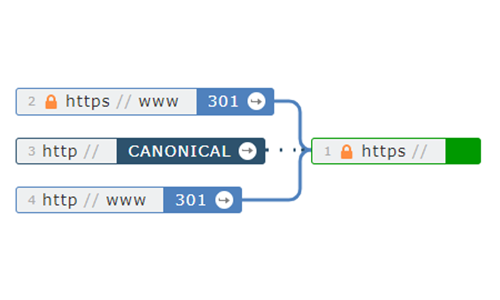
There is a new Majestic Site Explorer visualisation that gives you an at-a-glance view of the redirect configuration of the four variants of a homepage (www, non-www, http & https). It’s based on crawl data and available on the summary report in Fresh Index. If you prefer to jump straight in (rather than read blog posts), you can check it out here.
Websites come in many shapes and sizes. There have been many innovations since Tim Berners Lee invented the world wide web in 1989 while working at CERN . The addition of secure HTTP, known as HTTPS, facilitated secure transactions and paved the way for the commercialisation of the web. As technology developed, the cost of computationally expensive encryption dropped. HTTPS shifted from being a tool used during checkout and login to a server-wide means of delivering web pages.
Additionally, as the web soared in popularity, the use of “www” servers to host websites lessened, with more and more sites preferring to drop “www” and use the domain name only.
This all leaves us with four traditional variants of homepage on the web.
- https://www
- https:// (without www)
- http://www
- http:// (without www)
There are a lot of discussions in SEO circles about how to manage homepage variants, and the consequences of failing to do so. However, it’s pretty standard SEO practice to choose just one of the four possible homepage variants as your main site url, and redirect other variants to it.
But, which do you and your clients use? Can you remember how you set up redirects for some of your older domain names? You may have added HTTPS in a hurry a few years ago, promised yourself that you’d come back to sort out the different homepage variants, and then moved on to more important things!
This is where the Homepage Variant tool can help. We’ve had crawl results for individual homepage variants for years. But, for some reason, it hadn’t occurred to us to summarise in Site Explorer which site variant is the preferred one. That is until now. We hope this is a useful addition to help you with site audits and possibly client pitches.
To access this feature, check out a domain in Site Explorer. If you scroll down, you’ll see a basic table of data that shows the last crawl results for each of the four main homepage protocol/subdomain variants.
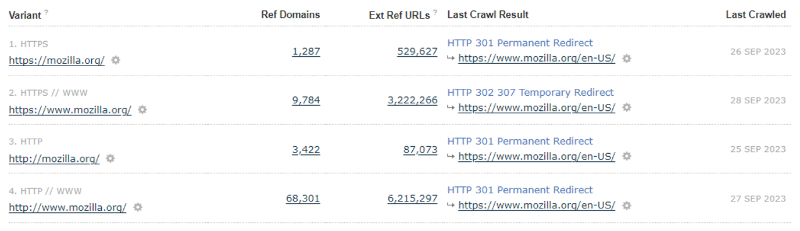
As lovely as the table data is, it’s sometimes difficult to follow what each different homepage variant is doing, and to where it may point.
So we’ve added a map of the resulting redirects, connections, timeouts, and errors for that site.
We think that this instant visualisation of the relationship between the variants will be a great addition to root domain and homepage searches in Site Explorer Summary, and we’d love for you to take a look.
How do you check a domain?
To check a website, perform any Fresh Index Site Explorer Summary domain search at either ROOT level, or URL level for one of the four variants. The new Homepage Redirects panel is near the top, just under the Outbound Links summaries for the domain.
If you don’t see the panel, it’s likely that you’re performing a non-homepage-variant URL or subdomain search, or a Historic Index query.
Some Examples
As the concept is relatively straightforward, rather than asking you to read endless paragraph descriptions, it’s probably easier to jump straight into examples.
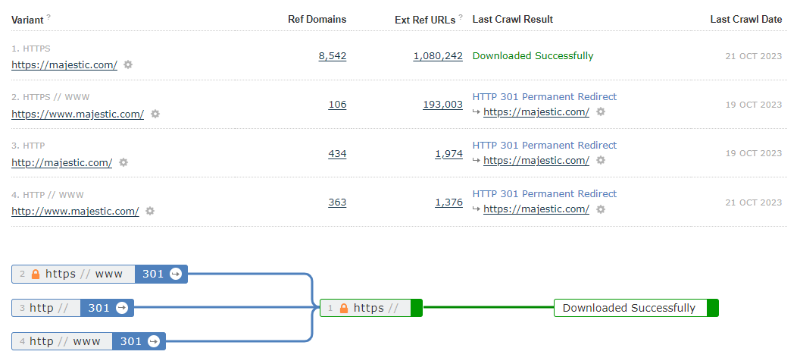
Here are the Homepage Variants for majestic.com. We use https:// (no www) as our homepage. The three alternative variants all have a permanent 301 redirect to that single point.
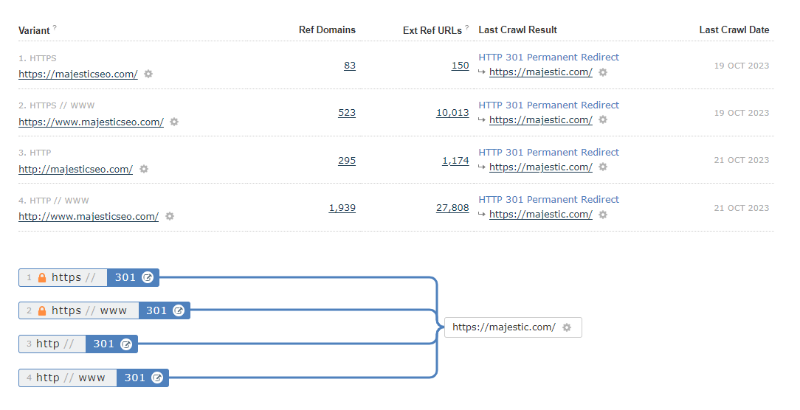
Here is another example. Each of the four variants for our old domain, majesticseo.com, have a permanent and off-site 301 redirect to majestic.com
Some non-standard examples
Obviously, if all potential homepage redirects were set up like this, then there wouldn’t be much point in this tool. But when you start to look at some other sites, you can see results that are slightly interesting.
Note: To keep domains (mostly) anonymous, we’re just going to share just the visualisation where possible.
For this site, http://and http://www both redirect independently to their https:// version. Our crawler was able to use either version, without being redirected.

Here is an example where the https:// and http:// variants (without www) redirect our crawler offsite to a separate domain. However, we were not able to crawl any of the //www versions (in this case, it was due to our crawler respecting robots.txt instructions).

This site has a mixture of permanent and temporary redirects to the https://www version. You can spot a temporary redirect in the map as they use a broken blue line.

Here is a site with three variants that all redirect to the same https://www URL, but the redirects are temporary, rather than permanent.

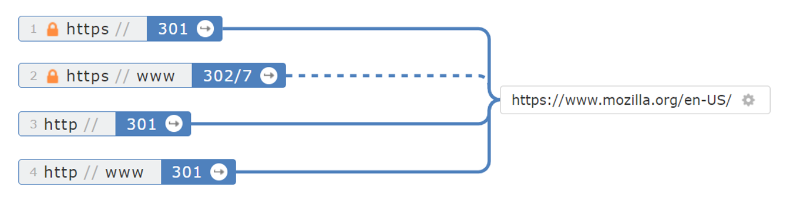
Here is a more complicated chain where two variants point to https://www. But then there is a further redirect as https://www and plain http:// then redirect to a separate URL on the same domain. To add to the unusual chain, three of the redirects are 301s, the other a 302/7.

Our crawls don’t just show redirect statuses. We also map crawl-time issues. Here is a site where we received errors for three variants, and a separate redirect to an off-site domain

Not all redirects are 301s or 302/7s; here is a domain that uses a META Redirect to an off-site domain. Note with this one, there are only three variants. It is normal that we may not have crawled every variant for some smaller sites.

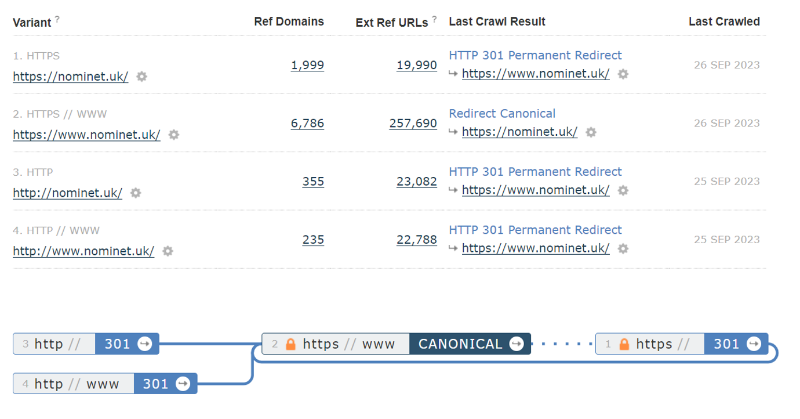
This is a site that uses 301s to redirect the //www versions to https://, but has a canonical redirect from the plain https:// variant.

Here is an example of a circular reference, caused by a redirect on http://www pointing to https://www. But then a Canonical meta tag on that page points straight back to http://www!

(The question mark beside https:// on the top row means that we have not crawled it in this index range.)
And here is another example, where a Canonical tag and a 301 redirect point at one another.
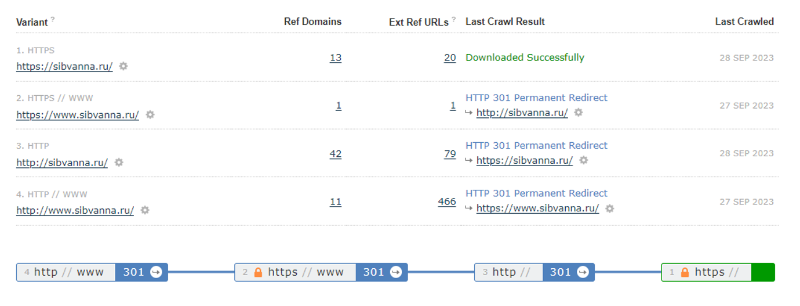
Finally, this is our favourite example. Each of the variants stacked together to make a 4-variant straight chain.
Some things to note
As usual, it’s incredibly difficult to fetch this type of granular data for the entire breadth of the visible World Wide Web. There are some things that you should be aware of.
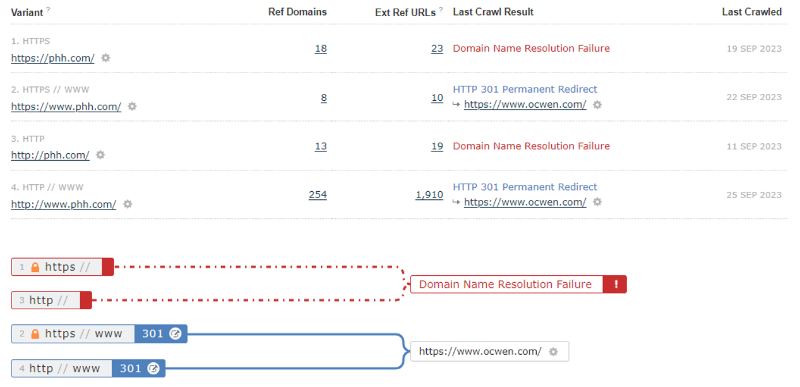
1 – The four variants may not have been checked during the same time period.
It’s easy to look at the visualisations and assume that these are the results of one crawl on the same day. For a small or medium site, it is probably more likely that each variant was checked on a different day.
This gives some results like this following example, where some crawls received a Domain Name Resolution Failure (on the 11th and 19th September), whereas two more crawls managed to resolve the domain name (on the 22nd and 25th September), then redirected to a separate domain.
The “Last Crawled” column will help you check the dates to see the crawl order.
2 – Individual crawls can receive one-off or transient results
Here is an instance where we received a HTTP 500 Internal Server Error on last crawl. This error was a one-off, and did not happen the next time we crawled the https:// variant.

Also, as we use an internationally distributed crawler, we can receive localised redirects that may change with each new index build. In this example, Nike directed one crawl instance to their GB site, and another to their Canadian version.

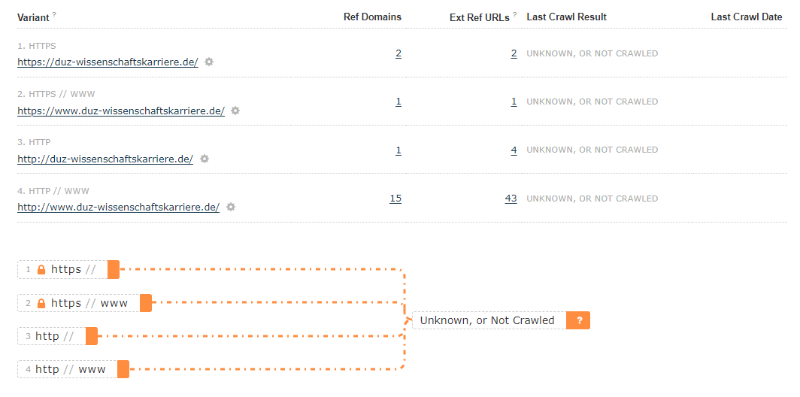
3 – We haven’t crawled every variant of every domain in the past 120 days
There are instances where we just haven’t crawled a site in the current index window.
In this example, all of the variants for this smaller site have inbound links, but we haven’t crawled any of them in the past 120 days of the Fresh Index.
If you would like to request a recrawl of a site’s variants, you can use the Submit URL request form at any time.
Now it’s your turn
Homepage Variants is available now for all Majestic subscribers. If you do not have a subscription, please come along and check it out with this week’s Demo site.
We hope that you find the new panel useful, as you check through your domains to see if there’s anything that may look unusual.
If you see something that doesn’t look right, is confusing, or you just want to share general feedback, please reach out to our lovely Customer Support team. We’d love to hear your thoughts.
- N-grams Near Links: Identify recurring phrases in the context around your backlinks - April 29, 2026
- TLD Checker – New for 2026 - February 26, 2026
- Welcome Hub – Improving the final step of your login journey - September 9, 2025