






The topic of internal linking is one of the most exciting in SEO. In the last article I wrote for the Majestic blog, I focused on topic prioritisation of URLs before and after a migration; (which you can read here). But this article focuses on Orphan pages – what they are, how to find them, and why it’s important.
What are Orphan pages?
The technical term ‘Orphan pages’ describes URLs or sub-pages that cannot be found by internal linking, since they are not linked at all. These URLs that are not linked internally ‘float’ in the URL set of a domain without being found by a standardised web crawl. This means, that they cannot be found by the normal Google bot either. So, in other words, this URL, (page), falls through the cracks.
How can I find Orphan pages?
Orphan pages can only be found if different data sources are merged. A gap analysis can, therefore, lead to the discovery of Orphan pages, but just a word of caution here, that Orphan pages should not be confused with ‘dead end pages’ which in turn have incoming but no outgoing links; these pages, therefore, represent a ‘dead end’, which admittedly, can also be a problem for internal linking, but are not instrumental to Orphan pages and as such will not be discussed further in this article.
How can I find Orphan pages with backlink data?
The most obvious thing to do would be a gap analysis with the backlink data of a domain.
The combination of web crawl data and backlinks is a first and easy step to discover Orphan pages. The exact method and how you do this probably depends on your preferences and the toolset available. If you have both a crawler and Majestic data at hand, you can compare the URLs from the web crawl with the link target URLs of the external links. The comparison of URLs, for example with a simple ‘SVERWEIS’ or ‘LOOKUP’ command in Excel, can be sufficient to detect any existing Orphan pages.

If you want something more practical and have to deal with significantly larger amounts of data, you can solve this with a tool like Deepcrawl, for example. In addition to the standard data of the web crawl, you can also add Majestic’s backlink data with just one click when creating a crawl. This function is free of charge for the user, as the Majestic data is added via a standardised API.
However, you can also add up to 100 MB of link data to the crawl manually. The result is an overview which reflects gap analysis whether the tool has tapped URLs from the web crawl or from backlink data.
In the best case, the report looks like this because no Orphan pages with backlink data are found here:

It is also possible that a certain number of URLs appear in the report that represents the Orphan pages searched for. These URLs should be further analysed. It should be examined whether these pages:
a) Have a real benefit
b) Where the pages have exactly come from
c) Whether these pages should be revised and upgraded because they have added value for the user or
d) Whether they should ultimately be completely eliminated.

Since we know now, how we can discover Orphan pages with the help of backlink data, we want to turn to further data sources, which can also contribute to the discovery; (just to note Deepcrawl was used for this as well).
Find Orphan pages through Sitemaps
This path is actually easy to check for Orphan pages and yet it is often a method that isn’t used. In most cases, you want to find out if your sitemap contains all URLs you want it to contain. It is rarely checked whether it contains URLs that cannot be found by a web crawl.
This typically happens when a new page is created that automatically generates the sitemap but forgets to link the page internally. Another reason would be if pages are only removed from the internal link, because they are no longer considered important, but the sitemap is not automatically adapted. Fortunately, various tools can help to control this as well. It doesn’t always have to be a large number of URLs it can find; everything between 1-10 can sometimes be enough, as the following screenshot shows.
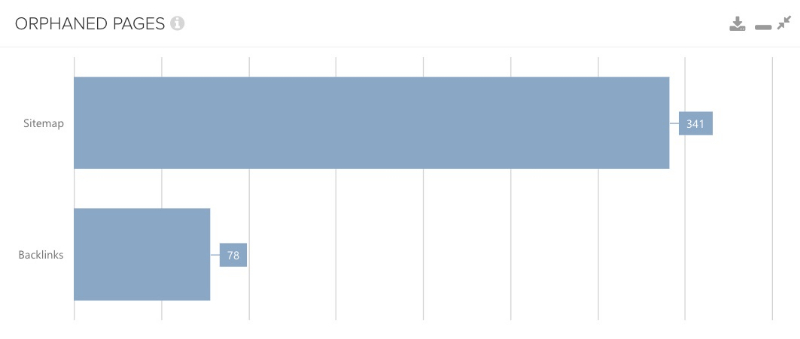
Since we have now also dealt with the discovery of Orphan pages via sitemap data, we come to another exciting and also important data set.
Find Orphan pages through Google Search & Analytics data
This comparison is perhaps the most interesting, as Google data is now explicitly used. So if we find Orphan pages by matching it with Google Search & Analytics data, the significance of this discovery may be a bit greater than, for example, through the sitemap.
Here we can be sure that Google knows these URLs – from wherever – and that we have not linked them internally any more. Of course, we do not assume that this is a URL difference, (which may have been caused by crawler control), and furthermore always presuppose unique URLs can be indexed; (in particular no parameter or sort pages).
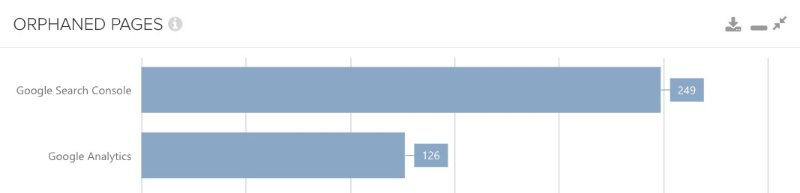
If you are interested in other ideas, you can use further data sources to find Orphan pages.
Finding Orphan pages through log files
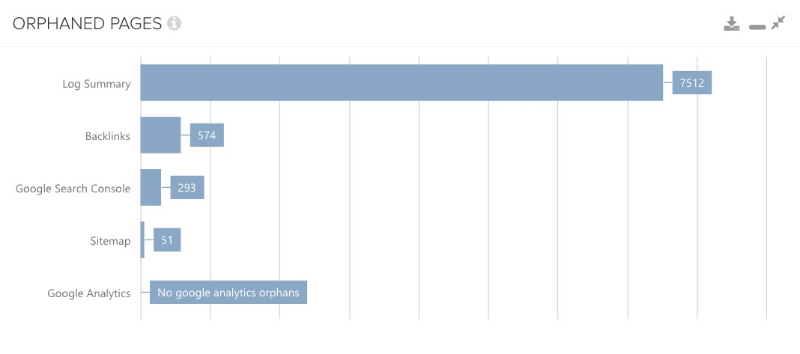
I mentioned that the comparison with Google Search Console & Analytics is exciting, but I should also say that the comparison with log files is actually even better and the reason for this is simple: log files are server-side data that are exact. Client-side data such as Google Analytics or data from the GSC, for which we basically do not know where they come from, are here as kind of a ‘black box’.
So if you have your server logs at hand, you can use them to make a comparison hoping that the result does not look like it does in the following picture. This is rather an alarming state.

If you still don’t have enough ideas on how to find Orphan pages, you can also export all created and active pages from your system and compare them with the URL set from the web crawl. One will be surprised how often results appear and how often there are Orphan pages. The reasons for this can be manifold, which brings us to the next section.
Reasons for Orphan pages
We have already dealt a lot with the discovery of Orphan pages, but not yet with the reasons for its creation, and these can be manifold. Here are some possibilities without claiming this list to be complete.
- Pages that have been completely or successively removed from the internal link without being finally switched off.
- ‘Test pages’ from the shop system, for example, to run A/B tests. The person in charge leaves the company at some point and nobody knows these URLs anymore.
- URLs from an old, previous CRM system were never completely deactivated.
- Landing pages for trendy/seasonal topics were never switched off.
- Incorrect use of the CMS, which generated pages.
- Categories taken offline were not forwarded.
- Pages were simply ‘forgotten’ during a migration.
The problem with Orphan pages
Sometimes there are really bizarre reasons that, funny as they may sound, distract from the relevance of the subject. One of the main reasons why Orphan pages can be unfavourable, besides the topic of index hygiene, is that they can cause problems in the keyword targeting of a domain. For example, in addition to the URLs for the main keywords Orphan pages, which no one knows but which are aligned to the same keyword or variants thereof (e.g. ‘fridge vs. refrigerator’ etc.), can harm the ranking success of a domain.
It would also be unfavourable if the wrong URL, although not (anymore) internally linked, would rank because it is perhaps historically linked better externally than the newer and better optimised page; (yes, sometimes pages are also not forwarded!). It can also be the loss of link force that can play a role in Orphan pages.
Of course, these pages should always be checked for traffic – it is not for nothing that they are compared with Google Analytics. However, it should also be considered that Orphan pages can disturb the link structure of a domain, for example, if they are – hierarchically seen – in the middle. That means the Orphan page only links to other pages, which therefore completely fall out of the URL structure because they are only linked from the Orphan page.
Finally, those who have not yet analysed their domain on Orphan pages now know what this is, why it is important and how they can proceed. Let’s hope you don’t find yourselves in a situation like this:
Why are Orphan pages important?
From an SEO perspective, Orphan pages mean that you may have strong and valuable content that isn’t linked to. That means Trust Flow or online credibility isn’t being passed through to these pages, which could help the visibility of your online profile. Furthermore, your readers and users could be missing really valuable content from these pages when searching your site.
So just do it – start searching for those Orphan pages now!
- Orphan pages: How to recognize them and what is the problem - August 20, 2018
- Domain migrations: watch out for the (internal) links! - May 21, 2018
- Have you considered these 7 factors with your Link Profile Analysis? - March 5, 2018
This is fantastic. Great approach and I love the details here. Thank you.
August 27, 2018 at 5:30 am-Sunny Kumar
Much love Andor Palau, looking forward to hearing about your next adventure.
August 30, 2018 at 6:39 pm-Peter Deski