





Gabrielle Benedetti asked a brilliant question the other day:
 Why is Gabriele Asking?
Why is Gabriele Asking?
When using Majestic, there is a drop down (or if you have personalized your settings, radio buttons) after you hit the search button:
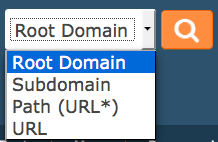 This drop down does not appear by default on the home page, as we interpret what we THINK you are requesting from your input. For example, if you enter bbc.co.uk then we assume you want the “ROOT” domain (the part before the top level domain extension). If you type in www.bbc.co.uk then this is infact a Subdomain of bbc.co.uk and www.bbc.co.uk/ with a trailing slash is actually interpreted at a URL – so we are assuming here that you want information about the home page on the BBC itself, not the whole site. There is another option – called path – which is rater more complex to explain). The question is – when reporting to a customer, which version should you use?
This drop down does not appear by default on the home page, as we interpret what we THINK you are requesting from your input. For example, if you enter bbc.co.uk then we assume you want the “ROOT” domain (the part before the top level domain extension). If you type in www.bbc.co.uk then this is infact a Subdomain of bbc.co.uk and www.bbc.co.uk/ with a trailing slash is actually interpreted at a URL – so we are assuming here that you want information about the home page on the BBC itself, not the whole site. There is another option – called path – which is rater more complex to explain). The question is – when reporting to a customer, which version should you use?
Apples and Oranges
The first thing to understand is that if you compare www.siteA.com with [non-www] siteB.com you ACTUALLY compare numbers that come from totally different calculations! So whilst one site might default to using www and the other defaults to non-www, they cannot be directly compared from a back link count, referring domain count OR a flow metrics count. Here’s why…
We Calculate Data at the URL Level
The Internet world is made up of URLs and therefore we first map the whole web and calculate scores for every individual page. This tells us things like… how many pages from other sites link to every page and how much “Trust” flows to every page. We end up with absolute scores for every page which we then convert to simple numbers to visualize, between 1 and 100 by normalizing the entire data set.
We then wrap up all the URLs for every sub-domain into another set of absolute numbers, which we again normalize against each other into simple numbers between 1-100.
We again wrap up the URLs for every root domain into a third set of absolute numbers, which we again normalize against each other into numbers between 1-100 for entire root domains.
So because we normalize each time, each dataset is compared using entirely different data sets. You cannot compare Apples and Oranges.
I am not mathematical – tell me another way!
A “real world equivalent” might be looking at the “number of unique words ever spoken” by each person on the planet, by country and by continent. You could take every person in the US, and give them an estimate of the absolute number of words they know. Then you could normalize the data so that every person has number between 1-100 where people near 100 know almost every word, whilst all newborn babies would be on zero. (A lot more will score zero than score 100 by the way.)
Now if we worked the same things out for everyone in America vs everyone in Great Britain, then first you would need to decide on a way to “roll up” the data. Would you use the Mean? The Mode? the Median? Whichever you choose, you have a score for each country, but then you would rank then numbers against each other to compare countries.
So a person could be REALLY linguistic, but come from a country that is ranked low or ranked high.
You should aim to compare Pages (for SEO) not roots or subdomains.
I think this example explains why…. Here are the top five results in my Google SERPS as I type for the phrase “Advanced style:
1: advancedstyle.blogspot.com/
2: advancedstylefilm.com/
3: advancedstylefilm.com/screenings
4: http://www.theguardian.com/fashion/2014/may/03/advanced-style-fashion-blog-for-older-women
5: https://www.youtube.com/watch?v=nWKTfqivbRQ
Now on the surface, result 1 is a sub-domain. Result 2 is a root domain. The others are clearly pages.
Look closer… the first two are ALSO URLS, BECAUSE THEY INCLUDE THEY TRAILING SLASH!.
In other words – Google is reporting at the page level. Even though some of it’s algorithmic factors are domain based, but most are page based. Yet again, some signals are server based or country based… but Google almost usually reverts back to its lowest unit of measurement when deciding to answer a query. If it doesn’t, then the chances are they can answer the question for you and not send you to any site at all! (Something they are doing increasingly often)
But the page Google returns doesn’t have any Backlinks!?
I think that the reason people keep looking at domain data is that the data on the surface appears meaningless at the page level. But a page ranks without external links to it, because it has INTERNAL links to it from other strong pages n the same website. That is why we pass Trust and Citation through internal links, even though listing all those internal links would require a 10 fold increase in storage at Majestic.
One page on Mashable.com can be brilliant, whilst the next may be completely ignored. The same applies to Wikipedia or the BBC or CNN or Blogspot… the truth is that a strong website has a more options on how it directs its users around a site – but ultimately, Google returns pages, not sites. A strong site linking strongly to an internal page increases the likelihood of a page ranking… but only if it links from its strong pages.
So in answer to Garbriele’s Question
In my opinion – assuming Gabrielle is asking as an SEO, then the answer is “Neither”. Instead, select the page that Google chooses to rank and then use that. Otherwise you’ll end up trying to compare apples with oranges – or small sites against Wikipedia.org. If, however, Gabrielle was asking as a share investor, then the root level is the key… unless a root domain has sold the sub-domains in their entirety to another party. because it is the accumulated power of the domain.
- How Important will Backlinks be in 2023? - February 20, 2023
- What is in a Link? - October 25, 2022
- An Interview with… Ash Nallawalla - August 23, 2022
Excellent article Dixon!
January 16, 2015 at 12:05 amThanks Philip. Someoene also asked about page level calculations vs domain level calculation in a webinar the other day, so I think it’s a timely conversation to have now.
January 16, 2015 at 10:33 amI stil have a hard time understanding why so often the TF/CF of root domains are lower than the TF/CF of the www. subdomain. Is it somehow related to the nomalization you refer to?
I’m using the metrics mostly to decide which domain has the most "power" if I buy the entire domain or get an article published on it.
I suspect the root domain metrics will most accurately show me what kind of linkjuice I can expect to flow from the domain to the articles (without adding additional external links).
Still… any new article that I publish will get its juice from a link at the www. subdomain, so it might be more revealing to look at the www. subdomain metrics to gauge the power my new article will get?
Any thoughts will be appreciated.
February 12, 2015 at 1:55 pmHi Kim,
February 12, 2015 at 2:48 pmIt really depands on how the site is designed. The TF/CF of the root domain will be an amalgamation of all the page level metrics. Including pages that have zeroes, and sub-domains that nobody remembers. So for most sites, there will be SOME PAGES that have a higher TF than the root domain as a whole, but many more that have less. The WWW will exclude all the subdomain URLs which we usually don’t use for the main site. For some sites that’s very few. For us, we’d exclude anything at blog.majestic.com for example, which would exclude some pretty high TF pages. The home page at www is often the strongest page on the site, because all the internal links go to there… but not always.