





In this article, I will take you on a fascinating journey to understand how search engines work. This isn’t your typical description of web bots (or spiders) and how they crawl websites, but how they process content. Before moving on, let me explain why this is important for you and your career as a search marketer.
Why every search marketer should read this article
Many Digital Marketers, Social Media Managers, and SEOs do not have a technical background and know nothing about computer science. We all manage to do our jobs and have been more or less successful without knowing any of this jargon.
So far, you may have been comfortable with your job and probably don’t feel the need to know anything about computer programming or computer science.
Yet I believe we, as search marketers, should make an effort to understand what goes on inside a search engine. A few years back, I decided that my learning journey should include (some) computer programming. It was challenging but well worth the effort.
It is essential to stay at the forefront of developments and thrive as professionals to avoid commoditization. I can see how the search landscape is rapidly changing. By keeping on the cutting edge, you’ll maintain and increase your competitive advantage.
I trust this article will be inspirational and ignite your ambitions.
I’ve decided to share these insights to tickle your curiosity and reflect on where you are in your professional journey. This article will shed new light on SEO and hopefully trigger thoughts about your future.
This article will open a door on an unknown universe where Words and Language meet the Binary world of Bits & Bytes. What you will read in this article is a description of what I refer to, perhaps inappropriately, as real cyberspace, where code is poetry, where machines understand man and vice-versa. My ambition is to set you off on a very personal and essential journey.
I encourage you to undertake this journey and embrace the turmoil it may cause. Change is always challenging. No pain, no gain.
We live in a world where success is a combination of your will to adapt to situations and overcome adverse events and circumstances:
Adapt and Overcome (Cit. The Sniper Mind – David Amerland P. 217)
Good Luck.
What you will learn from this article
This article is a qualitative and very rudimental description of the search engine indexing process. I will describe and how you how words become numbers. It’s more of a discovery than anything else.
I’m not a computer scientist; I’m a Search Marketer like your yourself. I do not have the background nor the experience to explain the science or the technology in detail. My objective is to show you how the transformation occurs and share considerations on the implications.
Modern Search Engines: from full-text to natural language
Web Search engines have been online right from the start of the commercial usage of the Internet. There was an immediate need for tools to find data, news and gather information online. Many of you weren’t born yet in 1993 when I got my first coax cable connection at ESTEC and surfed the pre-historic web. It was the “Internet”. In those days, the Internet was a “loose” interconnection of networks. A typical online session would consist of point-to-point navigation between sites: you had to know where you were going.
The first attempt to organize resources online was the development of Gophers. Gophers consisted of curated collections of Internet URLs arranged in a menu format.
There was a rapid evolution of librarian flavoured taxonomy, in an attempt to create a catalogue of World Wide Web (WWW) resources. A flurry of other transitional technologies came about, lasting an Internet heartbeat: Archie, Veronica, Jughead. It was 1994 when the Internet welcomed its first successful full-text search engine: WebCrawler.
WebCrawler is the beginning of modern-day web search technology. It was a pivotal moment that has shaped the future generations of Search in general. Until then, a select clique of experts would access online services such as DIALOG or LEXIS-NEXIS.
Neither WebCrawler, nor other search engines that followed, took advantage of the stable and robust technologies used by the services as mentioned earlier and the extensive subject classification taxonomies which had evolved in over a century.
Web search engines had the vocation to serve the casual searcher, unfamiliar with the sophisticated rules and features such as Boolean or Regular Expressions. That vocation to serve the casual server has evolved into the objective to understand people who use their “natural” language to find data, information, goods and services.
The search engines have moved from a simple full-text search to understanding Natural Language. This is a radical shift in technology with a direct impact on SEO procedures and methods.
In 26 years, search technology has delivered progress at exponential growth rates. SEO was much easier back then.
It would be silly for us to understand, or even worse, attempt to emulate in any way these technologies and know-how which are driven by thousands of PHDs worldwide. However, we can understand the process and extrapolate some order-of-magnitude considerations.
Computers don’t understand Language.
Computers understand numbers. An average computer can crunch more numbers in a minute that an army of people in a lifetime, however, they don’t understand Languages. Yet modern search engines not only understand Languages but also extract useful information based on the needs expressed by the user through a query.
Languages are systems of communication.
Language plays an essential role in our lives. People have conventional ways and attribute traditional meanings to words related to their culture. Languages are a complex system of rules (structure and grammar). There are many dimensions in a language. For example, languages are characterised by:
- Domain-specificity: a shared understanding of words. Terminology and attributes of particular terms which are part of a culture or a profession.
- Context-dependence: everything we say or write depends on the context of the discussion, the document or book we are reading.
The Web is a messy place.
The web is the living image of ourselves and our lives: it’s chaotic. I would guess more than 90% of the content online lacks structure. Web pages are written in sub-standard HTML and often in poor Language, with many domain-specific and contextual words and phrases. Computer science can make sense of our content with Natural Language Processing (NLP). NLP is the technology used to “teach” computers a Language. But first we need to feed computers with words.
Feeding words to a computer
Our first step in this fascinating journey is feeding words to a computer.

Let’s consider a typical web page. First of all, a search engine or user must download and save the page. For those interested in the process of downloading content from the web, there is an excellent tutorial by Steve Pitchford on how to download a website with python.
Once downloaded, we need to “clean” things up. Just to give you an idea, here is a short-list of activities required to split a document into finite “bits” a computer can understand:
- Extract content from the markup language where it is embedded. In the previous paragraph, we mentioned downloading a Web Page. We must extract the content from the supporting HTML markup needed to position content (including images, video, and other elements).
- Remove all punctuation and symbols which are unnecessary, such as emoticons and other irrelevant elements.
- Remove “stop words”. Stop words are: the, in, at, that, which, and, on, or and the like. They are words which do not contribute to providing the meaning of the text.
- Create a vocabulary of terms which are present on our document. A vocabulary is not a simple inventory of words, but an extract of all the words present after performing Stemming and Lemmatization. Stemming is the process of combining words with similar meaning. Lemmatization, in linguistics, is the process of grouping the different forms of a word so they can be treated as a single term.
As you can imagine, Natural Language Processing is articulated, complex and comes with a lot of data scrubbing. You cannot process dirty data. Remember, the Web is a messy place.
It is well beyond the scope of this article to delve into the details of the programming and technology. You don’t need to know how it was developed, but understand how to use it 😉
So let’s let’s do it! Consider the following three phrases:
- Majestic is a link intelligence platform
- Find backlinks to your website with Majestic
- Sante is a Majestic Brand Ambassador
Let’s see how the three sentences become numbers and how the transformation occurs.
Start with the vocabulary
We must create our vocabulary, consisting of all the words used in the phrases. Our vocabulary is:
{‘ambassador’, ‘backlinks’, ‘brand’, ‘find’, ‘intelligence’, ‘link’, ‘majestic’, ‘platform’, ‘sante’, ‘website’}
For the sake of simplicity and clarity, this is our vocabulary. We have removed typical stop words. Our vocabulary consists of ten words.
Pay attention now, because this is where the magic happens.
Let’s organize the three sentences on separate rows and the words of our vocabulary in columns like so:
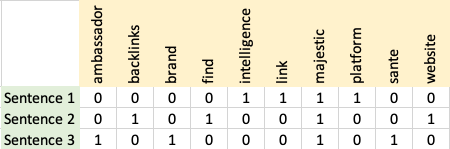
You can do this with any piece of content do it right now.
- Choose a set of phrases
- Remove stop words
- Draw a table and place a 1 in correspondence of a word in the phrase and 0 elsewhere
- repeat the process for each phrase.
Let’s take a closer look at this table of zeros and 1s: it’s a Matrix!
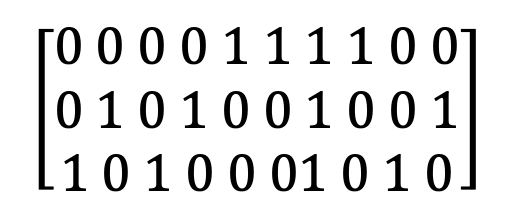
We have a Vector Space Model of our content:
Our words have become numbers
Now, we can apply linear algebra to the matrix. We can compare sentences which are now Vectors. We can perform numerous analyses. For example, we can determine the similarity of phrases in our document. We can also run keyword counts, sentiment analysis and much much more.
As Search Marketers, we need not to know all the science, but understand the principles and master the means to perform the analysis.
Conclusions
In this article, I illustrated how words become numbers – the very first step every search engine takes in the process to understand web pages. If you have done the previous exercise, look at the phrases and then look at the table of numbers. There is nothing we can relate to as humans. This consideration changed the way I see content, how I compile editorial guidelines and how I perform on-page optimisation.
The complexity of this task becomes even more evident if you have even minimal coding skills. Writing elementary algorithms in python or a computer language of your choice, reveals how much effort is required to “talk” to a computer and have it perform tasks on our behalf.
Ultimately this process has taught me to pay attention to even the smallest details in writing copy. At times even small, apparently insignificant, changes can have a significant impact on organic performance. What may seem like a small change to us is a variation in the position of those 1s and 0s in the matrix, making it something completely different. There is nobody on the other end (in the computer) who is going to interpret and correct any misinterpretations.
And finally, remember the technology is not perfect and it’s evolving: we know how it should work, but the results aren’t always what we expect and would like.

He has an engineering degree, has worked for major aerospace organizations including the European Space Agency (Noordwijk - Netherlands), and has been working on the web since the very beginning of the commercial World Wide Web in 1994.
With 30 years of hands on experience, Sante has reviewed and optimized hundreds of websites and successfully cooperated with small local companies and large multi-national corporations, offering a wide spectrum of expertise essential to the success of a project.
Sante is a seasoned bi-lingual SEO & web marketing consultant offering services in organic placement, paid search, and content creation, in both English and Italian.
Sante regularly attends and speaks at search marketing conferences and teaches, and offers SEO related courses. Sante is the Majestic Brand Ambassador to Italy.
More information on Sante:
Twitter: @sjachille
Linkedin: https://www.linkedin.com/in/sjachille/
- Is metadata important in SEO? - October 30, 2023
- A Simplified Approach to Content Creation using NLP - May 11, 2023
- The unknown side of search: when words become numbers - November 18, 2020