






Fixing broken, deleted or otherwise lost links has many benefits. What if your link came from a well trusted, high quality source, wouldn’t you want it back?
Sometimes a link is removed or deleted. Maybe on purpose, or just maybe by mistake. With Majestic Site Explorer we can help you pinpoint exactly the reason behind why a link has been lost, making this easier to recover – if it is a good source.
With an entire tab dedicated to understanding these links, you can click and drag parts of the graph that catches your eye and take a look at the lost backlinks on these specific dates. Numerous different reasons will present themselves; such as technical issues, HTTP responses, sometimes it is due to the nature of a type of site.
In this post, we will cover (most) of the reasons you will come across when analysing your Lost Links within Majestic… like this:
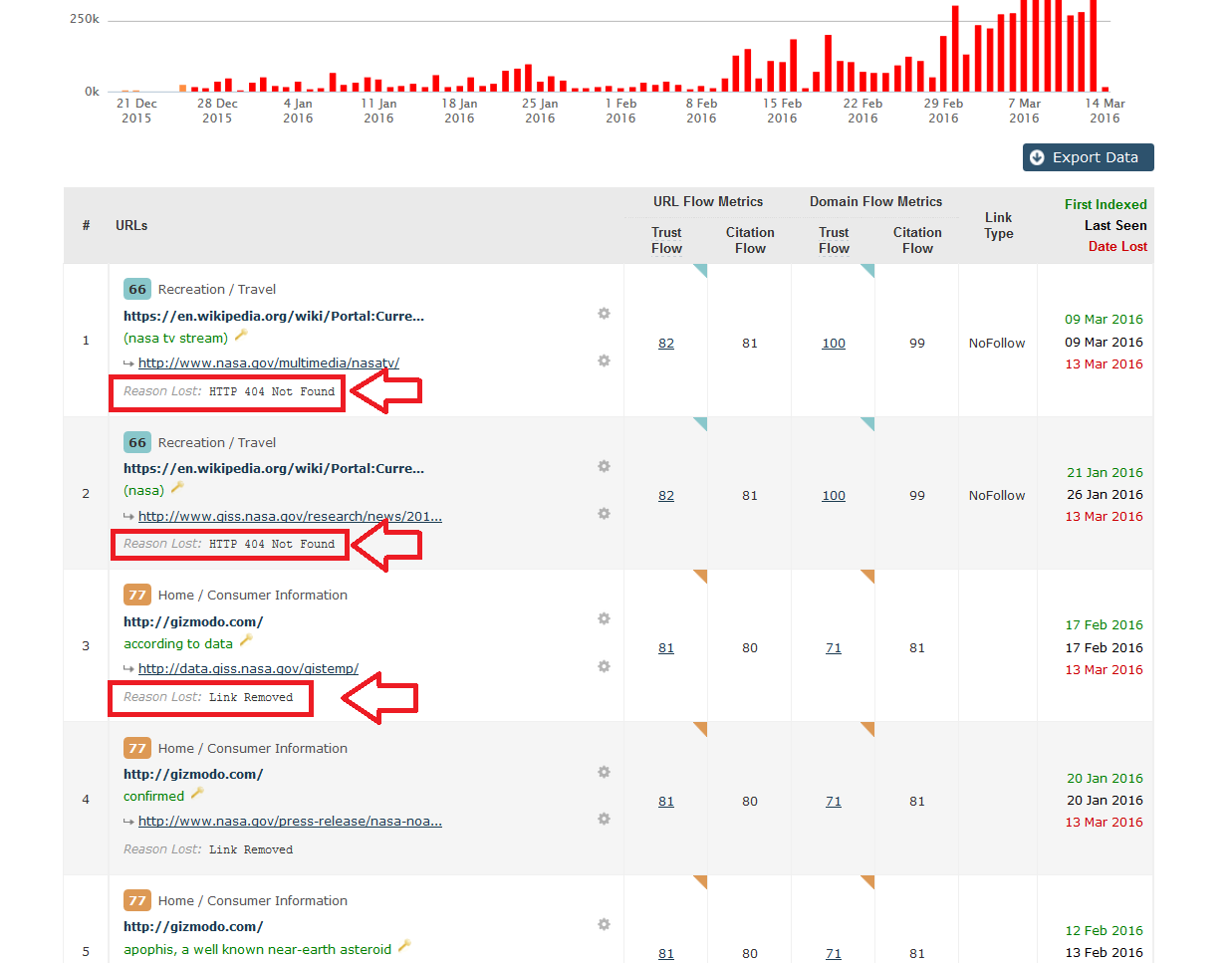
Reasons Majestic Reports for Deleted or Lost links:
Link Removed
This is the most common of reasons why a link is ‘lost’. Simply, it has been taken down by the Webmaster – who would have guessed!! However, to make things harder, this is not always the case. At times, it is the type of website your link has been found on. In the age that we are in, everyone is after fresh content all.the.time. RSS feeds for example, are constantly finding new content to ‘repost’ on their feed. Therefore your link is not static, and it will move further down the feed – eventually falling off the page altogether. If this happens, when our bot revisited the original URL your link is nowhere to be found. Your link is now on a new URL so of course our bots will report a missing link.
Unfortunately, it is hard for any bot to know the different between a ‘pushed’ link and a ‘removed’ link. My advice would be to look for clues. Can you see the word ‘feed’ in the URL? If so, I can almost guarantee that the link is just on the next page. Worst case scenario, you will need to use the ‘gear icon’ short cuts to visit the link directly and see for yourself. You could also check your New links to see if you recently received a link from the same domain.
Adverts can sometimes affect this too. If you have started a new campaign that included placing adverts on an ad network, one day when we crawled a particular page your advert may be showing but the next time we go back there is a new advert from another company. Again, the data would suggest that the link has been removed. Luckily, in these cases the link type is usually an image, so check this before you get too worried!
Redirect Canonical
Canonical tags are nothing new. These types of tags allow you to point Search Engines to the page that you want them to crawl instead of its’ duplicate – most likely we are talking www vs non www or http vs https. Sure enough, in these cases you will only need one page to be indexed by crawlers.
So why will it show as a lost link? Well, the canonical tag would state that the page should be on a different site. For example, a page is visible on www.site.com and site.com, Majestic will show the link on both of these. If after the fact, a rel Canonical tag is added to one of the pages to make www.site.com the page to take account of, the site.com page is now regarded as being redirected to www.site.com therefore the link would be lost from site.com.
HTTP responses
HTTP 301 – Permanent Redirect
This redirect is used when you want to move the entire page to a new location – forever. This type of redirect does pass link juice in the view of Search Engines, more so than other redirect options. Seeing this in your Lost tab most likely means that you will have a new link couple with this change on a new URL. This may take a few days for us to regenerate the new source page and add this into your profile.
HTTP 302/ 307 – Temporary Redirect
Webmasters may put this in place while the site is undergoing maintenance, redesign or there was a small issue. This type of redirect passes very little link juice as it is meant to just be a temporary change. If you spot this within your lost links, it is likely that the link will be back soon.
HTTP 403 – Forbidden
This would usually indicate that we have managed to reach that particular URL, they have responded but are refusing to let us in! Most of the time, it is due to some sort of issue from your host or service provider of your website. It may be due to security software and the default configuration setting is not allowing our bot to pass. To resolve, it is just a quick email to your host and request they whitelist the bots you want. It is hard to say what other bots they are blocking, but at the very least they are not allow the MJ12 Bot to pass. Unless you know the Webmaster of the source so you can contact them and request they take the right steps to remove this block, this may be the end of the road.
HTTP 404 – Page Not Found
Quite simply, the page has been removed. It’s nothing personal to your business or your link, the webmaster has decided to remove the content. If you spot this with your Lost links, you may want to try and get a link from a different page on the same domain. Just because the page is gone, doesn’t mean that the relationship you have with the site has to suffer also. Plus, some would argue it is an easy win.
HTTP 406 – Not Acceptable
Similar to HTTP 403, the 406 response on the other hand is sent when the server cannot fulfill the request made. Currently our bot is not able to do anything with images or movies, etc so to reduce bandwidth and load time we include with our request to only send a reply if the content is text/html/xml. If the server does not believe this is the case then it should send a 406 response. This may be because either we are requesting an image or other unacceptable content, or possibly because the mime types in your server are incorrectly configured.
HTTP 500 – Internal Server Error
Seeing this error means that our bot encountered an unexpected issue when trying to reach that page or domain. This response from the web server does not really specify what the problem actually is, which certainly makes things harder to resolve. The operators will need to track down the logs and analyse these to resolve the issue. By using a site like downforeveryoneorjustme.com can help you find out if the issue has been fixed. If so, resubmit the link to us using URL Submitter.
Technical Issues
Timeout
This happens when the requested URL takes too long to respond to the request our bot sends. Pretty simple really, if a page or domain is taking too long to load there is most likely some sort of technical fault.
Connect Failure
Similar to Timeout, this response means that there is a technical fault. This particular failure indicates some sort of infrastructure issue between server and website.
Domain Name Resolution Failure
This shows that there is an issue with the DNS server of the source domain, often due to a change in IP Address. After making a change like this it usually takes a little time for things to aggregate around the world. Another reason could just be that the DNS server is down. If it is down, then we cannot crawl the site.
- New Bulk Backlink Checker Features - May 13, 2016
- Finding New Link Opportunities Just Got Easier! - March 16, 2016
- Were Your Lost Links Really Deleted? - March 15, 2016