





Content Creation is by far the most challenging of tasks we face to promote products and services online. We focus on keeping our content fresh and up-to-date to outpace and ultimately outrank our competitors.
This tutorial illustrates how to create and optimise content using a strategy based on the fundamental principles of Natural Language Processing.
In this article, you will learn the method and discover the tools to implement the procedure.
How do Words become Numbers??

The transformation from words to numbers is a fascinating procedure used to create a numerical representation obtained by organising a vocabulary of words extracted from a document. For eeach sentence, we can place a “0” or a “1” in the columns of our table, depending on the presence or absence of the word. The outcome of this simple exercise is a table of numbers, which is also a Vector space model of our content we can use to perform analyses to understand our document and compare it to others.
A more detailed explanation and importance of the procedure is available in the article The unknown side of search: when words become numbers.
What can we do with this model of our Content?
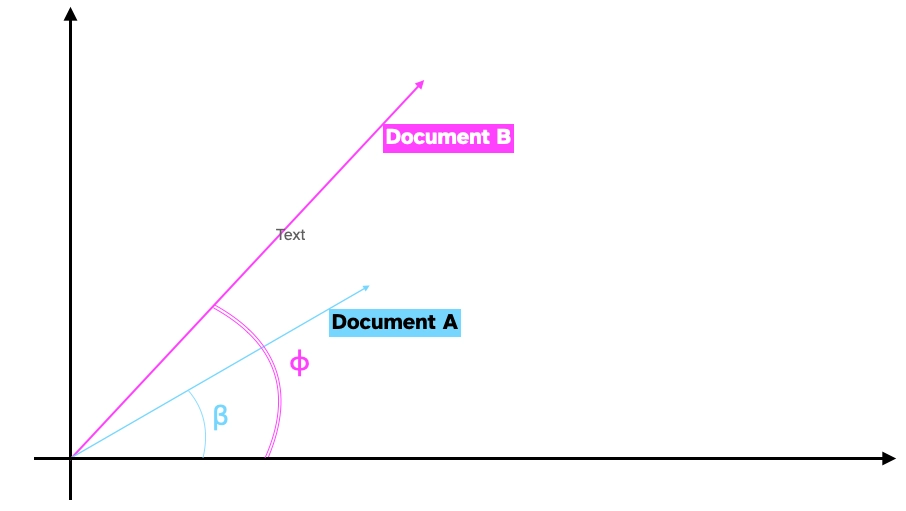
Modern search engine technology is built on these simple yet fundamental assumptions. Once we transform our corpus of documents, we’ll have a series of vectors: one for each document. Vectors are the primary building blocks of linear algebra. Each vector will describe a particular direction and magnitude in that vector space. So, for example, with this representation, we can efficiently run a duplicate content analysis to identify similar documents. In fact, similar documents will tend to align and have the same direction, hence cover similar topics: similar content means close alignment in the vector space!
In the first part of this article, we have “compressed” some fundamental principles related to how search engines work. We also provided an elementary example to illustrate how to analyse content. If you are interested in learning the supporting Data Science to support your SEO activities, keep in mind these key concepts:
- N-Gram: an n-gram is a contiguous sequence of “n” items from a given sample of text or speech (for example, in a sentence). [read: Keyword]
- TF-IDF: short for term frequency–inverse document frequency, is a numerical statistic that is intended to reflect how important a (key)word is to a document in a collection or corpus of documents.
The Procedure
This procedure is a simple yet powerful method. In fact, we have removed all reference to Python, allowing anyone with basic Excel familiarity to create and optimise content using NLP.
- Study your vertical
Which pages, with a similar search intent, are ranking in the SERPs? Start your analyses here to find relevant and interesting content that ranks. Search Engines populate the SERPs with a variety of pages, depending on the underlying intent of the query. The challenge is to identify similar pages we can use for our analyses. For example, product pages will predominantly populate the SERPs if a query has a transactional intent. As a result, we will not gather significant insights that can inspire a content creation strategy by analysing these pages. We are interested in finding articles on the topic. They may not be ranking prominently on the first pages, so we’ll need to dig deep and use our judgement and experience to harvest the right pages. - Identify affinities
Which Topics are they covering? How are those topics combined on the top-ranking pages? We need to answer these questions to understand the logic behind the answer provided by a search engine. Which are the most essential topics on each page? How are they combined to give a valuable solution to the user? By reviewing the cluster of documents, a trend will emerge. - Analyse and Optimise your content
Once we’ve identified a path, we can use our findings from the previous point to create new content and optimise existing articles.
 will reveal the most prominent and common topics amongst top ranking pages. This analysis requires experience and good judgement.")
Use Majestic Topical Trust Flow to enrich your analysis
Topical Trust Flow offers another opportunity to identify other similar pages. Top-ranking pages in the SERPs will probably have relevant backlinks: use Topical Trust Flow to research their backlink profile. Find other websites and pages relevant to your analysis and evaluate the possibility of adding them to your cluster of pages. Link Graph can help you navigate complex website architecture and identify useful pages intuitively.

Backlink profile analyses can also reveal the presence of artificial or unnatural link building techniques. For example, the following image is from the backlink profile of a prominent article. As we can see, the backlink profile analysis reveals a network linking out to the page with high rankings.

Analyse the Content
Now we have a list of pages we would like to analyse and understand why they are closely related to our query. We’ll need a tool to perform this for us. You can find a number of SEO tools by searching for the term keyword density. Don’t be fooled by the terminology. While such tools analyse how often a particular term appears on a page, we are not interested in keyword density as a critical parameter. Our measurements aim at understanding:
- The presence of a topic;
- The combination of topics;
- The prominence of each topic;
- How close topics are to each other.
Let’s demonstrate the procedure and analyse the content of a page with a tool you can download here. We outline the process in the following image:
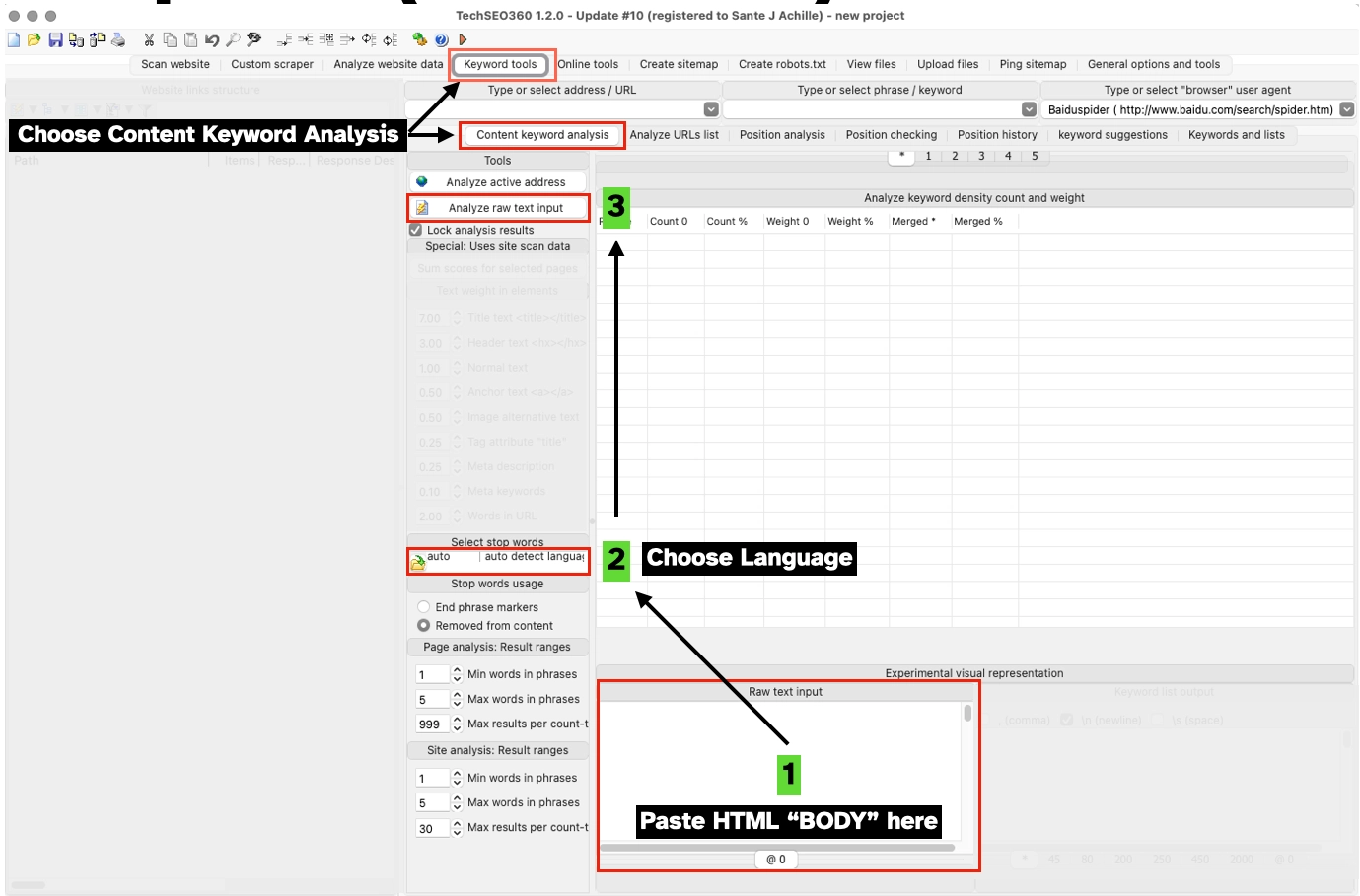
- After installing, click on Keyword Tools, positioned in the main menu, then on Content keyword analysis.
- For each page, copy and paste the HTML BODY of the page. You can use the tool with simple text as well.
- Choose a language to filter out so-called stop words. By eliminating generic terms, we can concentrate on the most significant N-GRAMS of the document.
- Click on the Analyse raw text input.
The workflow summary:
There is also an online N-gram analyser for those who like to work with online tools.
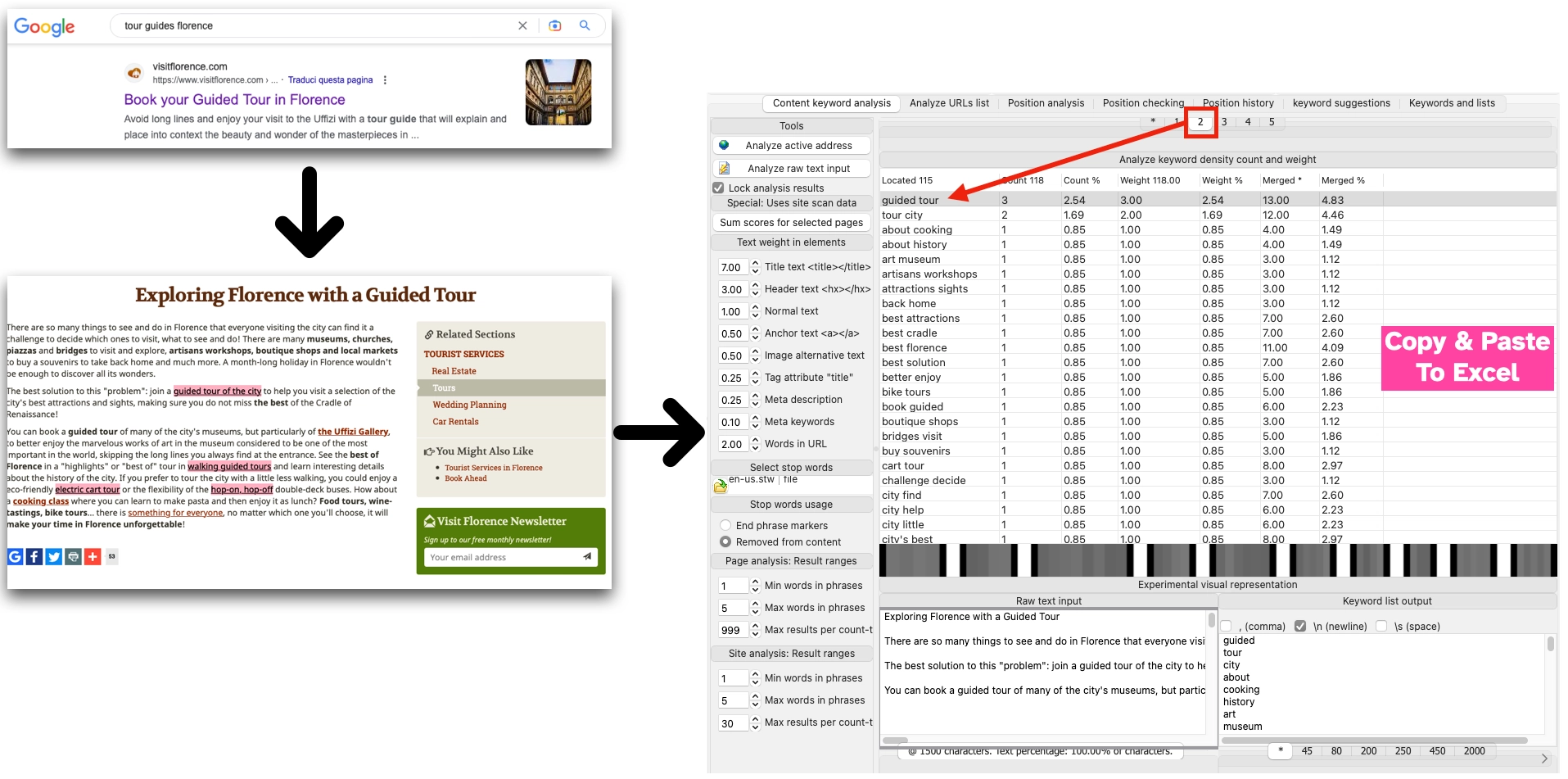
Looking at the content, now organised in this new and unusual way, it becomes easy to identify N-GRAMS (or keywords) most relevant to the meaning of the page.
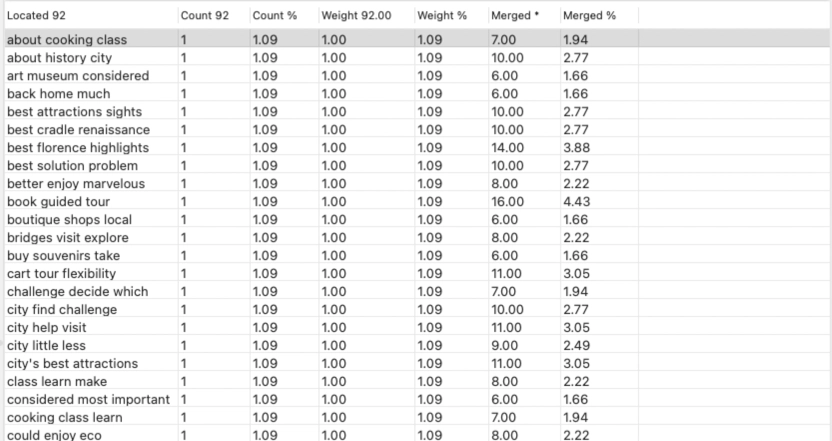
Performing such a manual process can take some time and may challenge your skills working with Excel, but, as they say, no pain, no gain!
Ultimately, you will have created a worksheet that should resemble the following screenshot from a similar analysis performed to identify the most relevant and frequent topics found in high-ranking articles around the Valentine’s Day Flowers query.
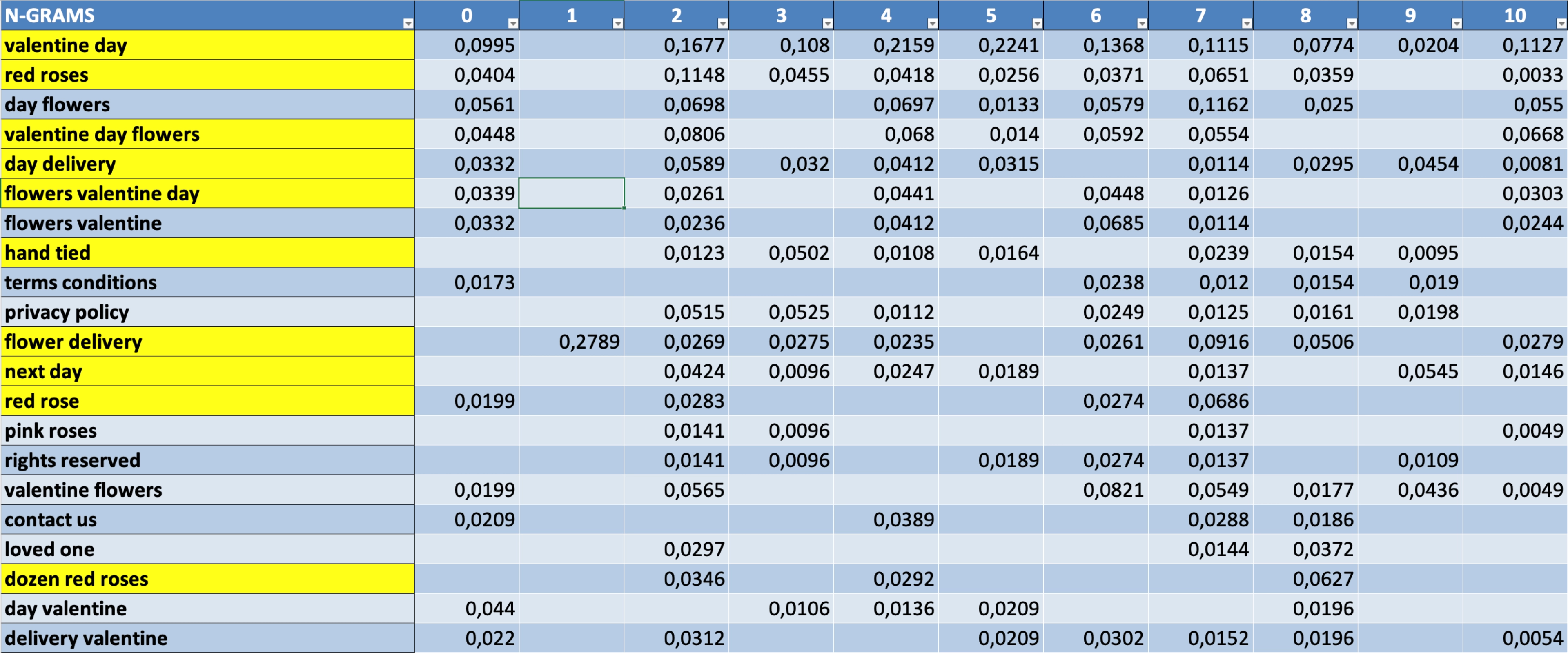
We performed this analysis using 30 documents and highlighted the important and most common topics in yellow. It’s easy to see how the key concepts are red roses, next-day delivery, and delivery on Valentine’s Day. Red roses and dozen red roses are also just as influential for search engines. If we are to create content around this topic, these concepts will most likely play an essential role.
If we have already written articles on this subject, we can edit and seek opportunities to use these and other related topics to increase relevance and gain precious positions in the SERPs.
Conclusions
This procedure using very basic Natural Language Processing is a simple yet powerful way to identify and use common concepts in a topically related cluster of pages (SERPs, Majestic Site Explorer/Link Graph). Such an analysis can help create new and optimise existing content by creating prominent clusters of closely related N-GRAMS or search terms.

He has an engineering degree, has worked for major aerospace organizations including the European Space Agency (Noordwijk - Netherlands), and has been working on the web since the very beginning of the commercial World Wide Web in 1994.
With 30 years of hands on experience, Sante has reviewed and optimized hundreds of websites and successfully cooperated with small local companies and large multi-national corporations, offering a wide spectrum of expertise essential to the success of a project.
Sante is a seasoned bi-lingual SEO & web marketing consultant offering services in organic placement, paid search, and content creation, in both English and Italian.
Sante regularly attends and speaks at search marketing conferences and teaches, and offers SEO related courses. Sante is the Majestic Brand Ambassador to Italy.
More information on Sante:
Twitter: @sjachille
Linkedin: https://www.linkedin.com/in/sjachille/
- Is metadata important in SEO? - October 30, 2023
- A Simplified Approach to Content Creation using NLP - May 11, 2023
- The unknown side of search: when words become numbers - November 18, 2020