






A recent Incapsula survey on Bot activity helped me to bring together a combination of thoughts about why crawling smarter is so much more important than crawling faster. Incapsula have been running the report for several years now. Novices and some experts alike may be alarmed to note that only half of your web traffic is from real people.
This post looks at some of the consequences of a crawl race, its impact on Index quality and some attempts by spammers to frustrate the bots. Yes – I’ll be outing a link network technique, a really dumb one for sending up such a red flag.
Good Bots and Bad Bots

Incapsula have identified that most of the world’s bot traffic comes from 35 “Good” crawlers (including Majestic) and a bunch of bad bots which we will not go into too much today. Although, it is notable that some particularly unsophisticated firewall systems block some bots by user agents without giving their customers any way out, this is ill advised. Here is the relative impact of each bot on the overall bandwidth of the Internet.
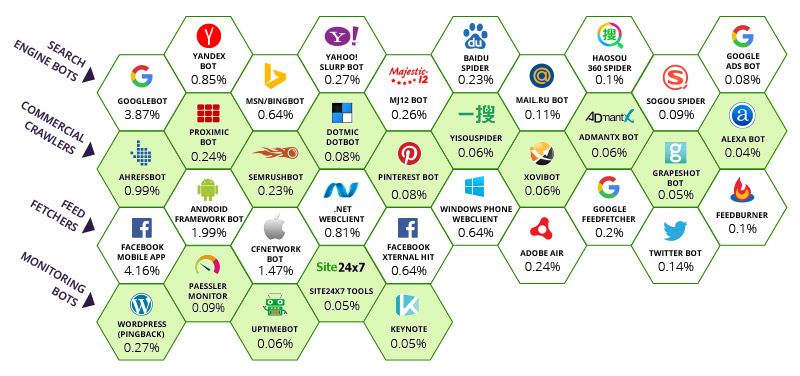
The numbers below each bot represents the percentage of visits to the pages tracked that were attributed to each bot. So at the top, Facebook’s mobile app grabs a whopping 4.16% of bandwidth. Google is commanding 3.87% of the entire world’s bandwidth. It’s actually more when you look at the other bots owned by Google. This is, I would say, fair enough. Google and Facebook have been instrumental in helping to keep an otherwise chaotic system integrated, connected and navigable. Clearly the top row of Search Engines have that in common, although Majestic is grateful to Incapsula for categorizing Majestic as a search engine and on the top row. We do appreciate that we have several peers on row two and Majestic would not have looked out of place there.
As a top 10 crawler, based on the table above, Majestic has a responsibility to know when to STOP crawling as much as when to crawl. There is a clamour within the SEO community to get “ALL” the links or at least as many as possible. This creates a paradox. When do you stop crawling the infinite web?
The Infinite Web
The recent antics involving Majestic and the International Space Station were not all about a publicity stunt. It was in part to highlight the infinite nature of the Internet. This infinity has profound repercussions for link tools. A few months ago, Majestic removed billions of web pages from its crawl. These were all subdomain pages that were being generated on the fly (automatically). It caused quite a furore at the time for a few domainers that were using the Trust Flow of the “www” version of a domain (which is technically a subdomain variant) to evaluate websites for selling in the domain name aftermarkets. The Lego pyramid helps to visualize the dilemma:

Imagine this pyramid represents all the subdomains on the Internet, the ones at the top being Trust Flow 90-100 and the ones at the bottom being TF 0. In fact, Majestic were finding that the subdomains at the bottom were way less than zero. They had no inbound links from anything but the same root domain and they were getting so numerous that they were not just accounting for the bottom rung, but the next rung too. The Majestic TF algorithm maintains something like the pyramid pattern, so the more rubbish at the bottom, the higher the Trust Flow of anything even remotely better than spam. Because this is an infinite problem, a Crawler cannot solve it by simply crawling more. All that would achieve is to make the next rung up the ladder looking better than they should and we would still not have anything like “all” the links, because anything divided by Infinity is still not a big percentage. Majestic could have a football pitch sized server farms and still not fix the issue. So instead, Majestic decided to cull the bottom two rungs. In the Lego representation above, that accounts for over half the data! (36 out of 70 bricks = 55%). Every single one of them being a page that no human ever saw and no self-respecting search engine should ever crawl.
The effect was to resize the pyramid. Suddenly sites that were on the third rung of a 1-100 scale were on the bottom rung. You can imagine the panic that ensued in the domaining community and you can almost see it in the comments on that thread.
This is not the only way in which an infinite web is created. Majestic.com itself (and any search engine) creates potentially infinite loops simply through its core purpose. You can enter any random set of characters into Majestic.com and the system will endeavour to interpret the results. This in turn creates SERPs (Search Engine Results Pages) which in turn creates links. These links should now link to pages that already exist, so this is a closed loop, but the search URL itself can be infinite in nature. Majestic (and Google) help other search engines to spot this and both make use of their Robots.txt files to tell the other that they should probably not waste their precious resources crawling these infinite URLs.
Spammers Double the Problem
The start of this post indicated that it would “out a link network technique”. It’s not something that I would normally do, but this particular network was particularly dumb and particularly pernicious towards MJ12Bot. I started the post as well pointing out that user agents are optional. Majestic chooses to identify itself. If you would like Majestic to NOT crawl your site, then use Robots.txt to give those instructions. Do NOT – as this link network did – seek to 301 (redirect) Majestic’s bot to its own home page. The effect is a very interesting Email Alert in my inbox, showing me a massive influx of links to Majestic.com:
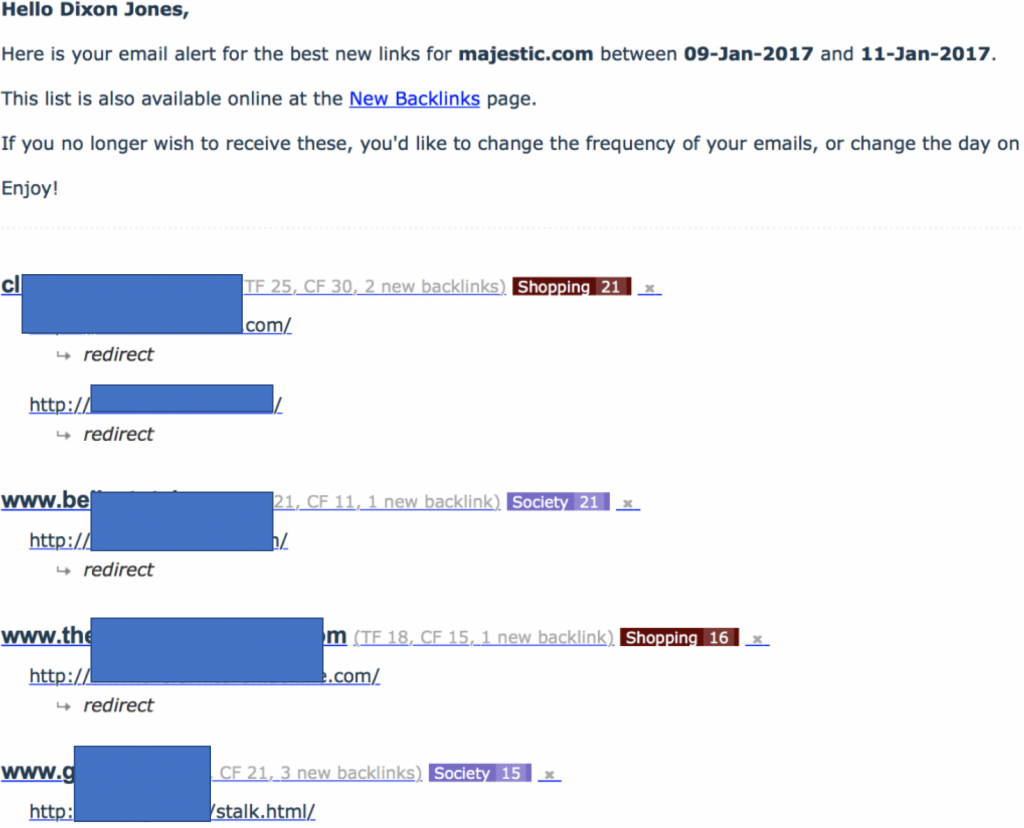
Notice that all of the newly found links to Majestic.com were apparently redirects from these websites. This was the red flag, because when I looked at the sites, they were clearly link farms, but they were also NOT linking to Majestic. This meant that they had to be cloaking MJ12Bot (hiding content from our bot). I was particularly amused when the network started using filenames like “stalk.html! When looking at these pages on a normal browser they all look like this:
User Agents are Optional
The last step in working out exactly what was happening was to use a third party tool to verify that the network was doing a 301 redirect based on the user agent. If you look up “Http Header Checker” you can do this for yourself, but it is especially useful to use SEOBook’s Header Checker or you can use Screaming Frog as they both let you change the user agent in a drop down box. Simply put – these sites were cloaking by user agent. If Googlebot or a human arrives, then they see the page you see above. If MJ12Bot arrives, it sees Majestic’s own site through a 301 redirect.
Back to Crawlers Becoming Responsible
The network highlights a challenge. This causes a crawler to look at two IP numbers, not one. This may not be significant given that in this case one site is a spammer and the other is Majestic, but it does highlight that 301 redirects are not perfect. They have an increased load on the Internet. A more efficient way to redirect would be to use domain name aliases, but this causes other problems for search engines, as the canonical (preferred) domain cannot be identified from the dns tables alone.
So with infinite webs and potentially load bearing redirects and all manner of other ways to hold up the efficiency of a crawler, it becomes illogical to continue to try to crawl spam… even if only to weed the spam links out. A far more practical approach is to gather enough data about a site to see some links from every domain and then move on. The trick is in NOT redrawing the trash… whether the trash is at the page level with infinite pages or at the subdomain level with infinite subdomains or at the page level with infinite near duplication, search results or redirects.
To do this, the crawlers that can crawl smarter are able to put considerably less load on the web than those that crawl faster. Crawling smarter works if a crawler is able to understand any of the following signals:
- Is it an important page?
- Does it update or is it static?
- Is it auto generated?
- Is it spam?
In particular, Majestic is good at the top and bottom observations. Flow Metrics give Majestic an edge over other bots and in particular I am looking at BingBot. I am confident that BingBot is more aggressive than Majestic, but I am not so confident that it needs to be. Perhaps Bing does not have such a pure number like Trust Flow or PageRank (yes they still use it) to help the crawl process, but I do not believe they are discovering significantly more pages as a result of crawling 250% faster than MJ12Bot. The same goes for our peers in the second row of the Incapsula chart.
The better approach – for Majestic at least – is to crawl enough to be able to find all the referring root domains linking to a site and then demonstrate and show enough backlinks from that site for our users to be able to easily identify the nature of the link pattern. One very easy way for users to see this is in the referring domains tab. Put in your domain and sort by Backlink count, descending and you see the link counts by domain, where you can drill down on the screen to get instant insights. Here’s majestic.com’s own site:
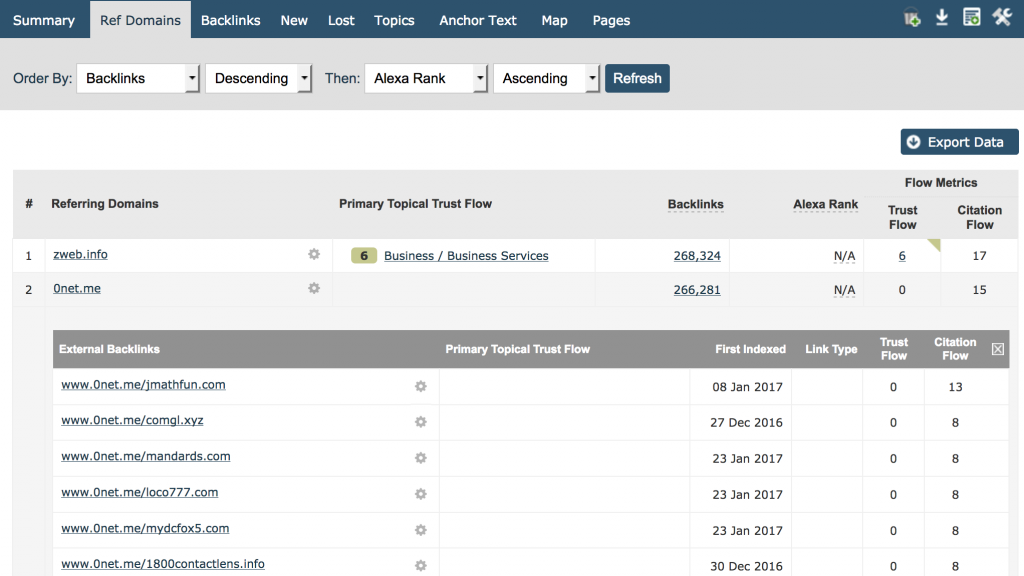
I think we can all agree that 266,281 links from www.0net.me does not tell us much more than, say 100,000 links from www.0net.me!
The domain tab is perfect for quickly identifying some of the worst spam links to your site. It is also useful in this post for identifying areas where a bot could become more intelligent and therefore efficient in its crawl.
Cheap Hosting Kills

Another problem aggressive bots can cause is when there are too many websites on the same server. Unfortunately cheap hosts find bots to be more of a problem than more robust hosting companies. This is because cheap hosts tend to put hundreds – if not thousands – of small websites on the same physical webserver. (You can use Majestic’s neighbourhood checker to see how many sites are on your server.) Majestic obeys Crawl Delay in Robots.txt but is also becoming smarter about the kinds of sites on these servers. It matters to you, as well, if you care about Google. Googlebot does not obey crawl delay! Instead they use an overall limit per server to determine the maximum crawl rate for that machine to not cause undue stress on the server. If your site has 1000 other sites – some with 1000s of pages more than you – on the same server, you have to ask yourself what share of Googlebot’s crawl on your server will actually be looking at pages on your site.
The Decision Tree for a Smarter Crawler
Now we have a number of elements that can help a crawler better manage its own resources and thereby reduce the impact on the Internet. It is a quest that creates a win-win situation, better data and faster Internet.
Decision 1: Discovery vs Integrity
In order to maintain a web index the size of Majestic’s, time is a natural destroyer of integrity. Every second that passes, new content is created, but also existing content is destroyed or changed. Imagine that in a split second… Majestic has a choice on what to crawl next… A URL it has never crawled before or one it crawled yesterday. What does it choose? The new one? Great! But what about the next choice? Or the next? We have already identified the concept of the infinite web, so this logic is flawed if you NEVER check back to see if a page has changed or dropped. Majestic cracked this in 2010 and have in fact resolved it in more than one way. If Majestic’s bots get over enthusiastic on the discovery side, vs the Integrity side, then there is a fail-safe in the Fresh Index, because after 90 days, a page that has not been re crawled would drop out of the index altogether. This means that the Fresh index will never have data that is more than three months old. Fortunately, however, that rarely happens… at least not with pages that people actually care about… because our flow metrics help us to prioritise in a more balanced way, so that important pages can be revisited with more frequency than less influential pages. If Majestic relied solely on link counts to make these decisions, then the bandwidth required would increase significantly.
Decision 2: Crawl Depth
How many pages is enough!? A spammy directory has more web pages than the BBC! But surely the BBC needs ALL the pages regularly crawled right? Well, not necessarily. The BBC produces news which, by its nature, becomes old news. Eventually it isn’t news anymore at all and ultimately even the BBC drops the page. Before that, the BBC tends to orphan the page, so that you can only find it via a search engine through a third party link. The problem gets even more complicated on sites like eBay and Mashable where the content is user generated and there becomes a grey line between quality and quantity. Here Flow Metrics help immensely. Other tools in the SEO industry are able to employ other tactics to make this decision. In particular they can take a proxy for “quality” by scraping the Google SERPs at scale and then using a visibility score to help make this decision. I have no inside knowledge as to whether they do this, but given that they look at SERPs data at scale, it would make some sense if they did take this as a signal.
But ultimately, we again need to guard our crawlers from the infinite Internet problem. We also need to avoid crawling the same site (or server) so much that it affects the latency for real users.
Decision 3: What to Discard
I was going to make that heading “How many hard drives to buy”, but ultimately that is not a theoretical decision that needs to be made. Having understood that the crawl problem is infinite, and then the question has to eventually be one of “what to discard”. What data in the crawl is so useless that it simply should not have been crawled in the first place – except perhaps in an attempt to root out other bad content – with the aim of removing the cancer from the data. This is what Majestic has been successfully tackling over recent months and the effects have been impressive to say the least. As soon as this becomes a factor, then the quest for crawling faster becomes an irrational one.
Save
Save
- How Important will Backlinks be in 2023? - February 20, 2023
- What is in a Link? - October 25, 2022
- An Interview with… Ash Nallawalla - August 23, 2022
Well put Dixon.
Crawling at scale is no easy task with no perfect answers to any of the questions. I may be biased as I was sold on the power of Majestic12 before MajesticSEO even existed, but I still believe that what you, Alex and the MJ team have built is the more valuable link resource available to anyone to us.
Thanks from a happy SEO
March 16, 2017 at 1:16 pmThank you Jason and your free beer is in the post 🙂
March 16, 2017 at 2:23 pmHi, what this article istn saying at the end and in my opinion should say what to do with old news like bbc site? From SEO perspective it should be 301 to the news category if it has SEO value.
March 17, 2017 at 8:04 amThat is a philosophical question and may be a fair SEO argument. In terms of Fake News, though, this would not be such a good plan, as it would mislead people intending to read one story on the BBC and instead they read something entirely different.
March 19, 2017 at 2:57 pmI have been working with SEO for a while now in the (link removed) Lo Angeles Home Health Care Field; and I often did wonder how many pages a good site needs. I think the content is of more importance than number of pages
March 20, 2017 at 11:32 pmthx, very informative!
March 21, 2017 at 3:39 pmI get a shed load of 404’s from Majestic and other crawlers – why can’t you crawl properly or reign your crawlers in when they hit x amount of 404’s?
March 24, 2017 at 5:28 pmOK. That’s interesting. Sorry about that!
March 27, 2017 at 4:31 amI assume it is not the domain on your email address, as we only have 4 URLs for that. Sorry if we are hitting 404s. This may happen because there are other pages on the web with links to those 404 urls. We do not crawl them when we see those URLs on other pages. Instead we store the information for a crawl at a later point. Most people like to see the 404s as they suggest that something is either misconfigured somewhere on the web or someone is linking to pages that do not exist on your site for some reason. One way to slow our bot is to use Crawl delay, but there must be an underlying reason as to why we are seeing so many 404s.