





Analysing the web’s biggest sites using Majestic SEO
Although Majestic SEO has a massive crawl capability, every system at scale has technology limitations. Google, for example, has considerable limitations which it disguises brilliantly:
Whilst the search giant may TELL you that there 1.4 billion results for a particular keyword, it only shows you the top 10 (or if you change the settings the top 100 or so) at a time. Further, if you use Google Webmaster tools to download your backlinks to a given page, Google limits the CSV file to 200 lines of data.
Majestic SEO goes back much further than this by default. Even in the Site Explorer mode, we’ll show you up to 10,000 rows of link data in a platinum level subscription and up to 20,000 in a standard report. We’ll also give you everything we have for most sites in an advanced report.
But with really big domains, giving you every link is not only technically difficult on our end, but also a huge challenge to analyse. Take Wikipedia.org’s historic index. If we actually gave you a CSV file with nearly 8 BILLION lines of data about anchor text and ACRank, what on earth would you do with it? Let’s face it, Excel struggles with 100,000 lines of data. You are not going to be able to slice and dice this:
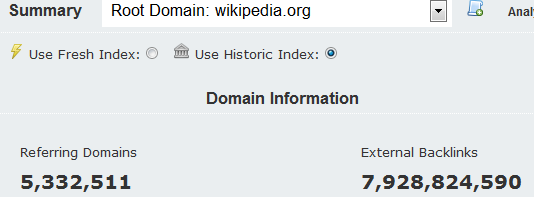
So here are some tips for analysing backlink profiles for large sites, using Wikipedia to demonstrate. I will assume that people analysing the large sites are not confined to the free version of our site – and I will personally be using a Platinum subscription for my numbers and charts – but many of these tips will work on a silver subscription.
Using the backlink history comparison graphs
Most of our users will already be using the backlink history graph using the historic data. In case you aren’t, here’s the history of Wikipedia vs about.com and Youtube:
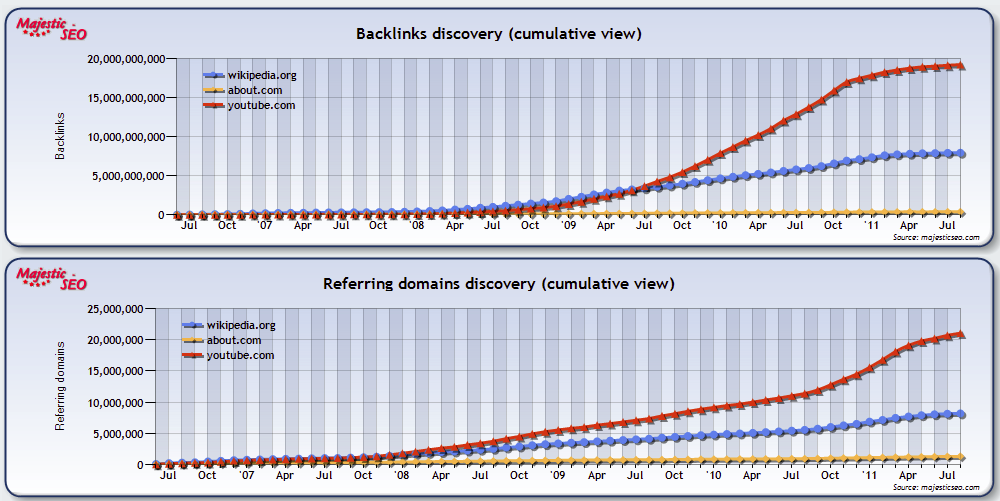
The two charts here show that YouTube has, since around April 2009, started to outpace Wikipedia. It suggests that Video is overtaking text as a way to communicate ideas, but also shows that YouTube has a much broader appeal – covering everything from news and education through to celebrity gossip and music. Wikipedia, by contrast, is limited to what one might describe as “evergreen” content – although in this regard they are certainly outpacing About.com.
The second way to use the backlinks charts is to understand the fresh charts and look at the “decay rate” of links. The chart below compares the Daily Fresh review rate of links to Wikipedia with links to StumbleUpon and Tumblr.
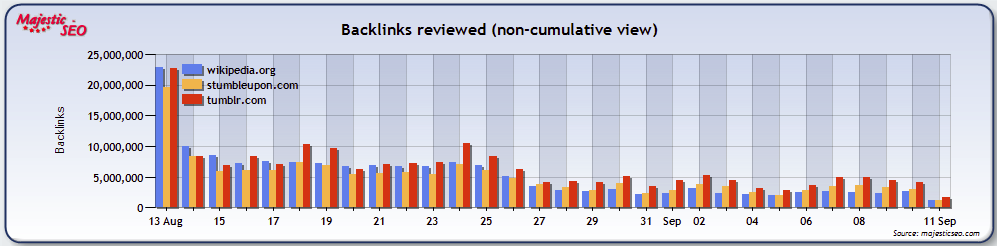
I have switched the chart to a column based output – as this will make more sense. Here we see how many links have been seen over a 30 day period (whether they are new links or not) and how early in the 30 days we saw those links. So whilst at first glance you might say that the “best two” are Wikipedia and Tumblr, on closer inspection you can see that after one day, the Tumblr links drop off much more rapidly than Wikipedia. About 5 days in they come back but what this is telling me is that both Wikipedia and Tumblr have a similar link strength at the head of their link funnel – as these links are being seen every day (or every hour). However, many of Tumblr’s links rapidly decay into areas of the internet that our crawlers frequent less regularly. We do get there, but the chances are that less people visit these pages than the Wikipedia pages, because Wikipedia has stronger links from “B-league” pages. If you wanted, you could more or less plot this decay rate and use this and a measure of link longevity.
Worldwide Distribution
Because it is impractical to get a list of all the links in an advanced report, the ‘links by country’ report is also not practical. But there is another way to look at how Wikipedia is disseminating itself across the globe. You can look at ‘links by language’. Whilst the compare backlinks history charts only work at the TLD level, Majestic Millions allows you to compare up to 10 sites at the sub-domain level. This means we can see the ‘links by language’.
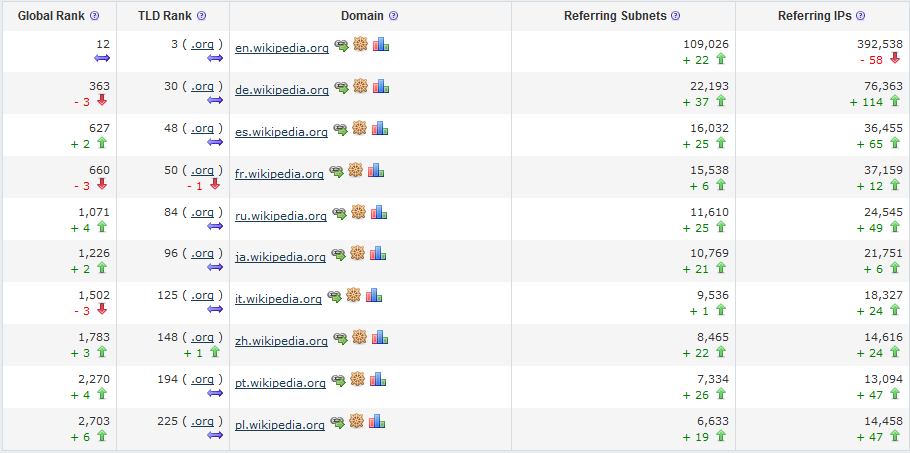
The great thing about the Majestic Millions chart is that it gets updated daily and if you were to look at this data over time, you would also see the global ranks against all other sites trend up or down. It would be reasonable to look at the spread of links by language as a proxy for traffic by language should you so wish.
Looking at the strongest pages in Wikipedia
In Site Explorer, we show you the top pages. This report breaks down the site into the number of links to each constituent page within the site. This will tell us different things for different sites, however I would urge Google’s Matt Cutts to have a look at just how much interest there is in the links to the Search Engine Optimisation page… Maybe a topic for another post.
Here we can see that Wikipedia is proving especially useful in helping us understand the Syrian uprising, the Indian Social activist Anna Hazare and the Asian (US) census, who all have pages in the top 100 list on Wikipedia. It would not be a wasted exercise to go through this list of 100 and look at what is generating the imagination of what must be a fairly intelligent audience, to select maybe 5 or so topics that might be the basis for blogs and developing social media equity
Looking at the top line numbers
One set of metrics that does not fall down on scale is the headline counts. Here we have a number of useful metrics. I am using the fresh data here – and plotting the changes to this fresh data daily over time is even more helpful. Here are some observations:
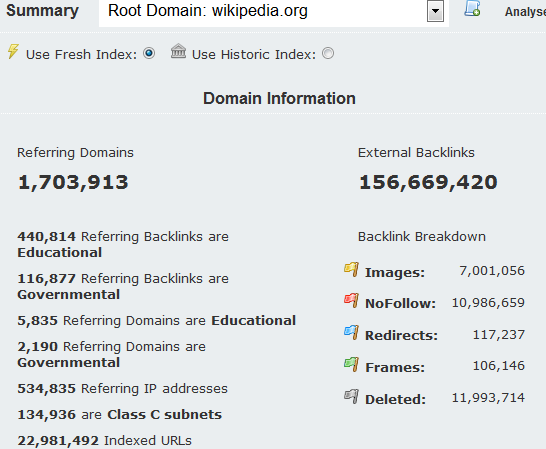
Looking at the educational and government strength
Not surprisingly, Wikipedia has plenty of links from Educational domains. Comparing this with another site (as a percentage of total referring domains, rather than as an absolute comparison) will give a good indication as to whether Wikipedia is trusted amongst the educational sites more than other sites. One potentially alarming item here is just how many government-run sites link to the public encyclopaedia. Wikipedia is (as the links to the Search Engine Optimisation page makes clear) extremely easy to change and manipulate. If Governments are sending their citizens to Wikipedia as the fount of all wisdom, then there surely has to be a question as to whether there is the potential to undermine sectors of society by changing these pages slightly.
Another Decay Metric
These top line numbers also give another indication of decay, with the “deleted” figure in the fresh index. Increasingly, links are coming via blog posts, and the most active blogs add content every day. This means that within a reasonably short amount of time, a link may drop off the home page of a website. After that point, it will be marked as “deleted” when our crawlers next come to the home page, but will still be present on the inner pages. From the numbers above, we can see that about 7.6% of links decay over a 30 day period for Wikipedia (11.9K/156.7K). Again, this looks like the site is stronger than Tumblr, which has a comparative decal rate of 11.3%.
Looking at individual Backlinks by Page, not by Site
usually, when we pull a full report, we simply pull a report for a domain. With a site like Wikipedia, this would give you 20,000 links to the home page in a standard report. This barely scratches the surface. However, by pulling reports by PAGE/URL you get much more targeted data. For example, one of the top 20 pages on Wikipedia is the page about the Libyan conflict. This has 19,000 links to it. If you click the little “report” tab next to that link, you can get a standard page report containing all 19,000 links to that individual page – and it only costs one standard report! Quick – Focused – and Detailed.

And there’s More…
I think the conclusion is that whilst trying to analyze sites with Billions of links, you need to first focus on what you are really trying to measure, before going too granular in your analysis. we would love to hear other thoughts from readers as to how they look at very large websites.
- How Important will Backlinks be in 2023? - February 20, 2023
- What is in a Link? - October 25, 2022
- An Interview with… Ash Nallawalla - August 23, 2022
I think it’s crucial to know from the outset what you want to get from the data. If you just put in a site download the report and then mess with it nothing is really achieved.
However, if you know you are looking for links in common with your own site, or new high quality links, or poor links to get rid of you can refine the report and make the data easier to digest.
Some excellent points in this post on how to do this well, although I don’t think I will be doing a backlink analysis on Wikipedia any time soon!
September 15, 2011 at 12:59 pmMajestic SEO is the best tool for investigating the biggest sites as it covers so many algorithmic factors that need to be taken into acount if a business has sites in competing against their biggest competitors. It’s also interesting in how these algorithmic factors change for example the article highlighted the increase trend with video as a way to communicate.
September 15, 2011 at 6:22 pmMight be interesting, though to use Wikipedia to look at a non-commercial vertical. So… Take the link profiles for the “London” page vs the “New York” page for example.
September 15, 2011 at 8:29 pmIt really is quite remarkable how effective the Majestic SEO system is. As a Design and Development firm, we regularly use their stats and reports to augment our services. An invaluable asset to all in this industry!
September 17, 2011 at 6:56 amIs it possible to analyse new trends, as example if a new startup company is getting tons of new high quality backlinks it might be an indicator that their business is growing and running well.
This information might be very interesting for investors and analysts. Perhaps there is a filter to show the sites with the most growth in high quality backlinks to find the most interesting companies.
September 17, 2011 at 3:00 pm> For this, a deep fulltext analysis would be very helpfull. Just look what is possible with IBM Watson, creating such a machine wich is able to acces fulltextdatabase would be very efficient in forcasting future events and trends on the market.
Google is allready working on this, perhaps Majestic will also provide fulltext one day 😉
September 19, 2011 at 10:37 amMajestic SEO is one the best tool for investigating the website.Through which a design and development firm can analyze their stats and can implement for further.we regularly uses this for our design and development firm.
September 19, 2011 at 11:31 am