






Whilst on holiday this summer, a Mathematics teacher approached me in a restaurant and asked me to explain the PageRank formula on my T-Shirt – which is really the key to understanding Google’s algorithms. It made me think and create the best explanation of PageRank that I can find. Hopefully better than the others I have seen on Youtube.
The PageRank Formula at the heart of Google’s Algorithms
Of course – being a Geek – I was wearing the Matrix form of the PageRank algorithm. The algorithm that has made Larry Page and Sergei Brin two of the richest, most powerful people in the world. This is the math that built Google.
Reading this literally says;
“The PageRank of a page in this iteration equals 1 minus a damping factor, PLUS… for every link into the page (except for links to itself), add the page rank of that page divided by the number of outbound links on the page and reduced by the damping factor.”

Easy right?
Well – maybe for a few of you. But this algorithm is fundamental in understanding links and in particular, understanding why most links count for nothing or almost nothing. When you get to grips with Google’s algorithm, you will be light years ahead of other SEOs… but I never really see it properly explained. I guarantee that even if you know this algorithm inside out, you’ll see some unexpected results from this math by the end of this post and you will also never use the phrase “Domain Authority” in front of a customer again (at least in relation to links).
I am not asking anyone here to know much more than simple Excel.
PageRank in Practice
I am going to start by showing you how that maths applies to this representation of a VERY small Internet system with only 5 nodes. Then we will look at a very slightly different map which has profound consequences for our results.
Before we start, maybe have a look at this and GUESS which node has the highest PageRank (The head of the tadpole lines are the “arrows” to show the direction of the links).
The PageRank algorithm is called an Iterative algorithm. We start with some estimates and then we continually refine our understanding of the ecosystem we are measuring. So how can we see how this formula applies to this ecosystem?
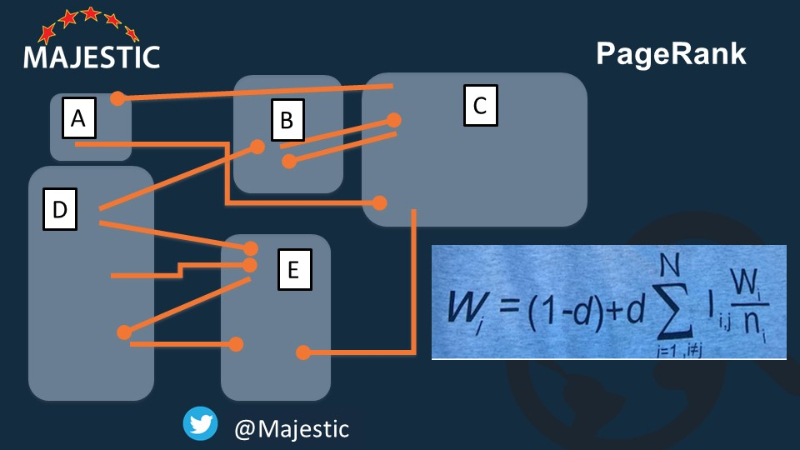
Firstly, we need to create a matrix… we have nodes A to E. I’ll call them pages for now, because it is a terminology we understand, but the hardcore fans should know I mean “nodes”, as this is important later.
- Start Value (In this case) is the number of actual links to each “node”. Most people actually set this to 1 to start, but there are two great reasons for using link counts. First, it is a better approximation to start with than giving everything the same value, so the algorithm stabilizes in less iterations and it is so useful to check my spreadsheet in a second… so node A has one link in (from page C)
- Now let’s map out all the blanks in a matrix…. Starting with every page cannot link to itself (OK… it can… but not in Google’s algorithm)
- Node A ONLY links to C
- Node B ONLY links to C
- Node C to A, B& E
- D – Links to B and 3 TIMES to E! Do you count it once or 3 times? I’m going to count it ONCE right now, but we’ll come back to that oddity later.
- E only links out to D
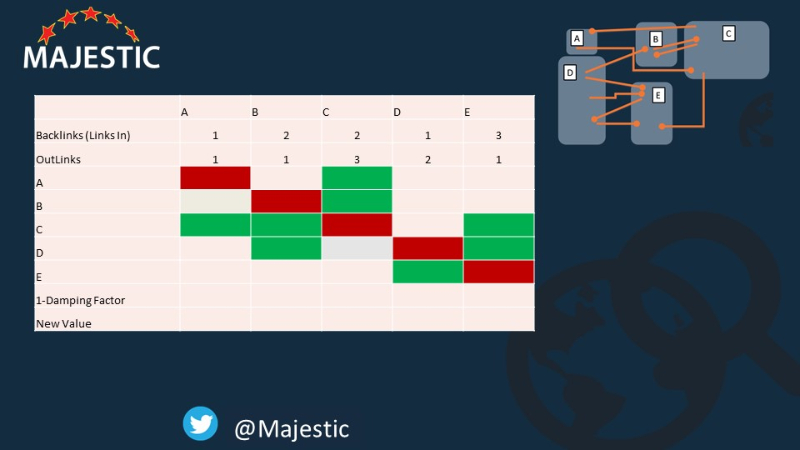
So here’s the grid. We can check a few things here… 8 green boxes= number of links in our algorithm (if we only counted the 3 links from D to E once).
Also – note that the majority of this grid is red… most pages on the Internet do not link to each other.
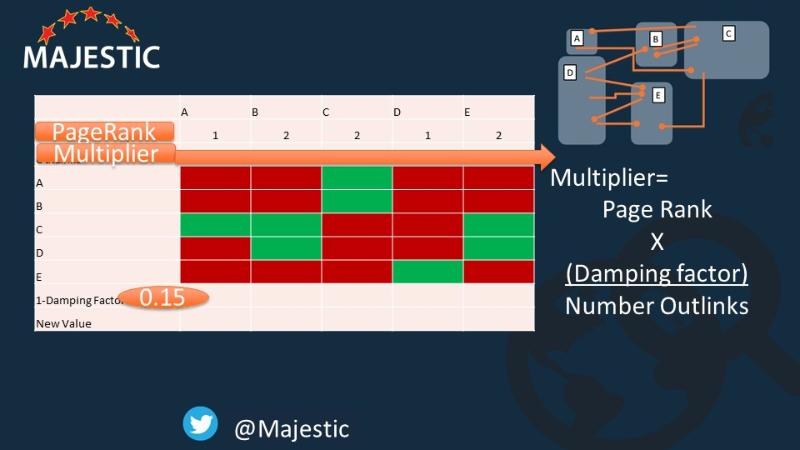
This is a simplification of that formula. It’s not TOO scary now is it? So now we can add the multiplier to each column. This is how much of its value each link will pass on to pages it links to.
So – for example, Page A has PR 1, Multiplied by 0.85 and divided by its single outbound link. So the multiplier is .85
On page C, the PR = 2. the Multiplier 2 X 0.85 all divided by the three outbound links. This means each one lends a score of 0.566666.
(This presentation is not going to go into the case of when the Outlinks is zero.)
So now we go along the green boxes, filling in the green boxes. So…
Page A gives one link TO page C… each link it gives has a value of 0.85… so we put 0.85 in this box.
Page C links to THREE pages, giving 0.5666667 to each one…. And so on until the green boes are filled.
Now… if you remember, we took off the damping factor before we started this, so we need to add the damping factor back to every page. This means the total amount of PageRank will stay stable.
Then we add up the columns, to find new PageRank values for each page! Here’s the completed grid:
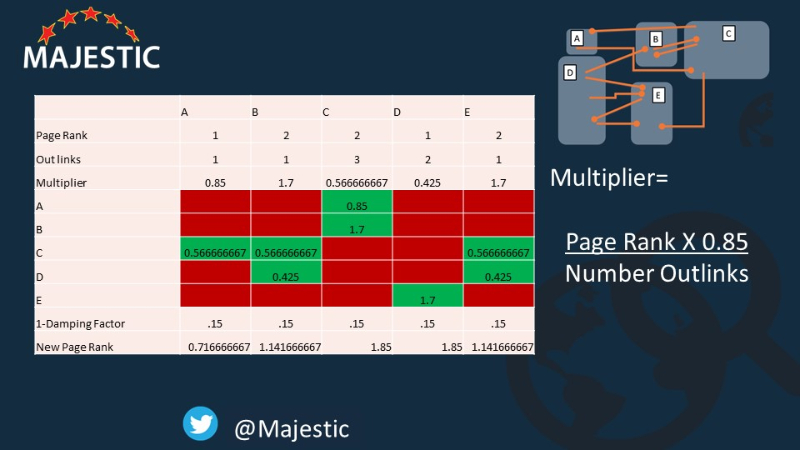
[EDIT Mar 7 2019: Thanks to Pablo Rodríguez Centeno for pointing out column C should add up to 2.7, not 1.85 in the table above. Nice spot!]
Now that is really all there is to the PageRank Algorithm – but I did say it is iterative. So you need to do it again and again to get to the real PageRank for every page. I therefore cut and paste the values back into the start values to get the next iteration. My boxes are already referenced, so the next iteration is worked out instantly…
If you want to see my Excel spreadsheet, by the way, here’s what to do.
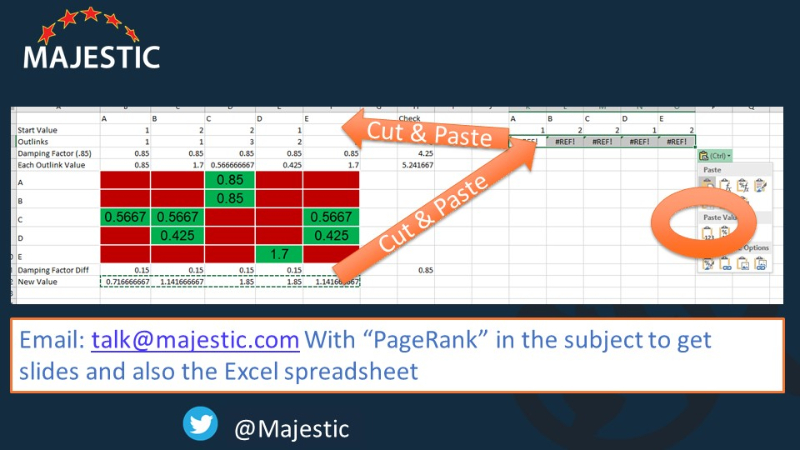
…I take the numbers at the bottom…
And put them into the top… giving me new numbers at the bottom, which I…
Cut and paste into the top again to get the third iteration… and again and again.
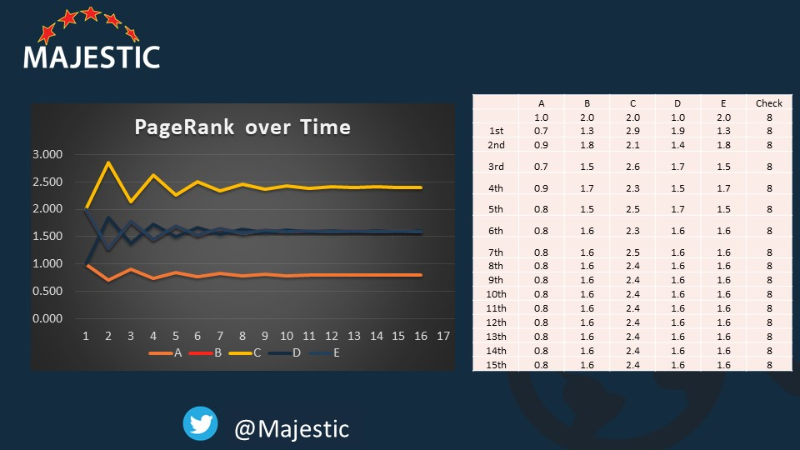
This is what happens to the numbers after 15 iterations…. Look at how the 5 nodes are all stabilizing to the same numbers. If we had started with all pages being 1, by the way, which is what most people tell you to do, this would have taken many more iterations to get to a stable set of numbers (and in fact – in this model – would not have stabilized at all)
Now we have done the math, we can see which is the most important page on our Internet.
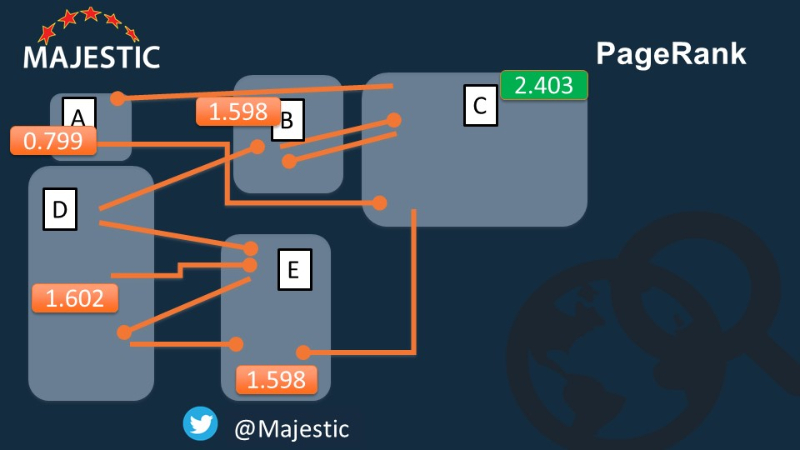
Was it the one you guessed? Well whether you said “yes” OR “no”…. It’s now time to reveal the wider story.
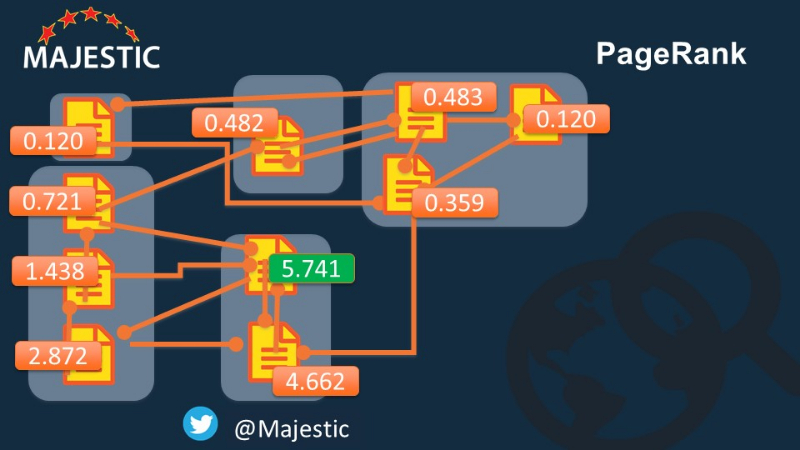
You recall I said “nodes” instead of “pages”? That’s because this was doing the PageRank at the lowest common denominator I had…. 5 nodes. But what If these were actually domains, not pages?… now I will put in the pages for each domain and start again…
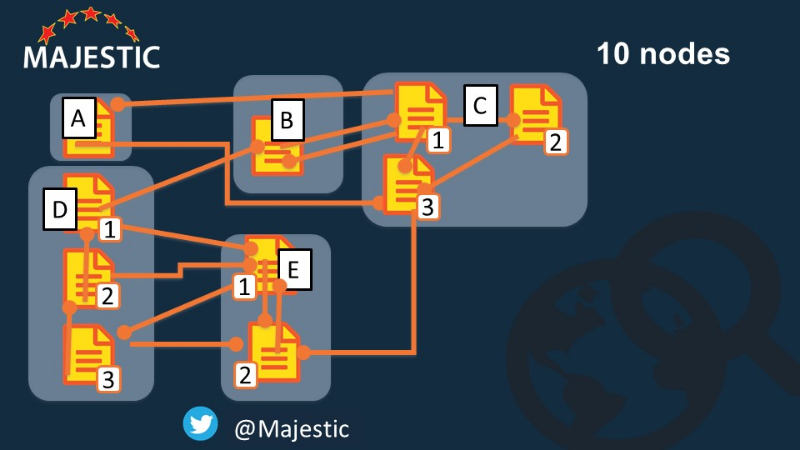
So now we have 10 nodes, not 5… and IMPORTANTLY, we now have some internal linking….
Where do you thing the power will lie in this version of the Internet?
Am I mad enough to do all of the calculations again? Oh Yeh…
… and here is the actual scores for every page.
The winning page being Node E1.
Some Interesting Observations
The winning Domain was site C in the 5 node model, so if you had used the domain level modelling, you would have hoped for links from pages which amongst the WORST at the page level.
The internal links on a site you cannot control dramatically affect the PageRank of your own pages!
PageRank was only EVER done at the page level… Majestic does our calculations at top level, Subdomain level and Page level – and in the quest to show our customers higher link counts, we default to TLD first – as do our competitors… but it is the PAGE level that counts.
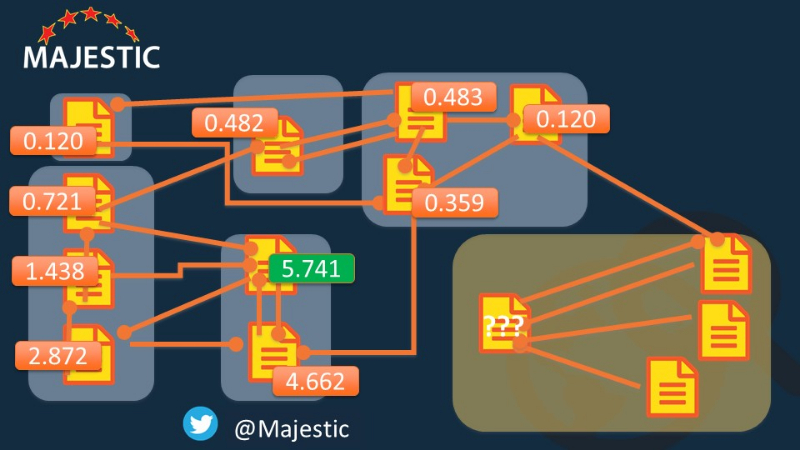
If you build a new site and only used Domain Authority to create links, you could EASILY have got linked from the worst page possible, even if it was from the best domain, because of the INTERNAL LINKS of the other web pages! How on earth are you going to be able to see the strength of a link if that strength depends on the internal links on an entirely different website?!
Second observation is that the data does not have to be complete, but it works best with a universal data set.
Back in 2014, one of our researchers wrote this blog post after a study using the PageRank algorithm ONLY on Wikipedia showed Carl Linnaeus as more influential than Jesus or Hitler.
Majestic’s Citation Flow, as a proxy to PageRank, could have told the researcher a different, more likely result, as our data uses a larger section of the Internet.
The next oddity is that the majority of pages have hardy any PageRank at all!. The top three pages in this 10 node model counts for 75-80% of the entire PageRank of the system.

“Link Counts as an initial estimate for PageRank sucks as a metric”
The next oddity is – the original guess… of using Link Counts as an initial estimate for PageRank sucks as a metric. This chart has plotted the PageRank of each of the pages as an area. When we started, page C3 was our the best guess for the highest PageRank. But look at how much love it loses by the end of the modelling.
“PageRank doesn’t Leak”
In both versions of my model, I used the total of my initial esitimate to check my math was not doing south. After every iteration, the total Pagerank remains the same. This means that PageRank doesn’t leak! 301 redirects cannot just bleed PageRank, otherwise the algorithm might not remain stable. On a similar note, pages with zero outbound links can’t be “fixed” by dividing by something other than zero. They do need to be fixed, but not by diluing the overall PageRank. I can maybe look at these cases in more depth if there is some demand.
The web is big
I’d like to leave you with these thoughts. I have shown you how this works in a world 10 pages big.
10 Pages X 10 calculations (albeit many multiplied by zero) and then 15 iterations is 1,500 bits of Maths.
Majestic does a similar (but different) calculation over 500 billion URLs a day for our Fresh index and currently 1.8 Billion pages a month on out Historic Index.
PageRank Proxies are HARD to build!
… which is just one reason why Google still cannot let it go… This is a Tweet from Google Gary.
Lastly – PageRank is not about Rankings, because Pure Pagerank does NOT consider context. So be very wary of using page metrics that are based on search visibility. Majestic’s Citation Flow is about the purest correlation to PageRank currently available, although the algorithm is a little different.
References for the Reader
PageRank is a Trademark of Google. The algorithm is protected (in the USA) by patent US6285999 and assigned to Stanford University. Whilst Majestic’s formula correlates closely to PageRank in tests, it has some unique differences which we do not make public.
- How Important will Backlinks be in 2023? - February 20, 2023
- What is in a Link? - October 25, 2022
- An Interview with… Ash Nallawalla - August 23, 2022
Fantastic video, thanks Dixon.
I was testing my ‘pagerank instincts’ by really pouring over your 10 node chart, the one under the line ‘The winning page being Node E1’ on this page.
The numbers didn’t quite sit right with me because there didn’t seem to be enough juicy inbound links to the winning page. Then I noticed that two key links were missing from the 10 node chart with the PageRank metrics on it when compared to the previous chart without the metrics. The two missing links are the two coming from node 2 to node 1. Suddenly it all made sense again and it was obvious why that page won.
So, just a heads up, two (very juicy) links are missing in the diagram with the PageRank metrics when compared to the previous diagram of the 10 node linking structure alone.
Cheers.
October 26, 2018 at 2:12 amThanks for the heads up. That’s now fixed in the blog post screenshots. I’ve just shown one link from E2 to E1, because this matrix form says a link relationship either does or doesnt exist (a binary decision) so two links just confuse the reader this for into the logic.
October 26, 2018 at 10:43 amGreat read.
Will Majestic ever get to the point of providing page rank estimates on page level? You have all the data Google has by crawling the web.. So it would certainly be interesting to see.
October 26, 2018 at 6:17 amMitch – Citation Flow (CF) already correlates (.83 when tested) with PageRank at the page level. On Site Explorer, switch to the URL mode to see the home page CF.
October 26, 2018 at 10:18 amThank you for this, but I’m really trying to understand it since I’m Spanish and it still hard for me, you could create this to the Spanish Language in your Spanish blog.
Thanks again.
October 26, 2018 at 1:15 pmI am really not sure it is easy to translate! 🙁 – Better for a Spanish SEO to do it. Maybe you could ask ask Miguel Lopez to take my slides and do a voiceover? If he did that, I would of course suggest we publish it, but it’s quite a commitment.
October 26, 2018 at 2:23 pmGreat article and it explains things well. Do you use a number for the CF calculation regarding the relevance of content (maybe using AI to determine page content) to rank certain pages better?
October 26, 2018 at 2:46 pmWe have other ways to consider relevence. Topical Trust Flow is one and page titles and anchor texts are others. If you put a search term into our system (instead of a URL) you actually get back a search engine! we don’t profess to be a Google (yet) but we can show our customers WHY one page is more relevent on our algotithm than another page. This could prove useful for SEOs. We actually launched that in 2013, but the world maybe never noticed 🙂
October 26, 2018 at 3:06 pmHi Dixon,
The original Random Surfer PageRank patent from Stanford has expired. The Reasonable Surfer version of PageRank (assigned to Google) is newer than that one, and has been updated via a continuation patent at least once. The version of PageRank based upon a trusted seed set of sites (assigned to Google) has also been updated via a continuation patent and differs in many ways from the Stanford version of PageRank. It is likely that Google may be using one of the versions of PageRank that they have control over (the exclusive license to use Stanford’s version of PageRank has expired along with that patent). The updated versions of PageRank (reasonable surfer and Trusted Seeds approach) both are protected under present day patents assigned to Google, and both have been updated to reflect modern processes in how they are implemented. Because of their existence, and the expiration of the original, I would suggest that it is unlikely that the random surfer model-base PageRank is still being used.
October 27, 2018 at 2:39 amHi Bill, Yes – thanks. I think I’ll have to do more of these. I couldn’t really go beyond Pagerank in an 18 minute Pubcon session. Although the random surfer model expired (and wasn’t even assigned to Google), it is still a precursor to understanding everything that has come after it. I think I would love to do more videos/presentations on both Reasonable surfer patent, Dangling Nodes and probably a lifetime of other videos in the future. To be able to demonstrate these concept without giving people headaches, though, the PageRank algorithm in Matrix form provides a good understanding of why you can’t "just get links" and expect everything to be at number 1.
October 28, 2018 at 10:15 amSee the Reasonable Surfer Model patent (assigned to Google) and
October 27, 2018 at 3:14 amThe trusted Seed Set patent (assigned to Google) which are both more modern versions of PageRank, which haven’t expired like the original Stanford patent has.
Reasonable surfer is next on my list (after explaining the divide by zero case “dangling nodes”)
October 28, 2018 at 10:17 amVery interesting post, I was searching this kind of a stuff on the internet and now I have found it. I use your method to optimize my blog. Lets hope good for the time. Thanks
October 30, 2018 at 10:21 amHi Ifran. Oout of curiosity, how have the results been thus far?
December 21, 2018 at 5:45 pmThanks a ton Dixon! For the first time ever, I can say to someone that I do somewhat understand Page Rank now 🙂
October 31, 2018 at 3:10 pmGlad I could help! Doing this exercise really helped me as well.
October 31, 2018 at 6:28 pmNice post
November 4, 2018 at 8:52 am[Link removed]
> Do you count it once or 3 times? I’m going to count it ONCE right now,
> but we’ll come back to that oddity later
One question, since that example took a different course: What if there really are multiple links from the same document to another document (as it happens all the time on the web)?
Most implementations count them as once, but the original patent does not seem to cover how multiple nodes should be handled. My guess would be: A random surfer would be more likely to move vom D to E if there are three links leading there?
November 6, 2018 at 7:28 amAh – well the Reasonable Surfer is a different patent (and therefore a different algorithm) to PageRank. I would imagine that initially, only the first link counted – simply because there either IS or IS NOT a relationship between the two nodes. This mean it was a binary choice. However, at Majestic we certainly think about two links between page A and Page B with separate anchor texts… in this case in a binary choice, either the data on the second link would need to be dropped or, the number of backlinks can start to get bloated. I wrote about this on Moz way back in 2011!
In my view, the Reasonable Surfer model would findamentally change the matrix values above, so that the same overall PageRank is apportioned out of each node, but each outbound link carres a different value. In this scenario, you can indeed make the case that three links will generate more traffic than one, although the placement of these links might increase OR DECREASE the amount of PageRank that is passed, since (ultimately) the outbound links from page A to Page B are dependent on the location of all other outbound links on Page A. But this is the subject of another presentation for the future I think.
November 6, 2018 at 10:12 amHold on a second, the PageRank is not used anymore, is it? Even Google folks themselves said it. They are using much more in-depth, even AI-based algos now.
December 3, 2018 at 2:19 pmPageRank IS an AI algo. Specifically it is a Machine Learning algo, which is a form of AI. All URLs in the Google Index still have PageRank scores, but these are no longer shown to the public. All of the AI algorithms that Google may be using now can still draw upon PageRank as part of their learning, so I would not be hasty to say AI has replaced PageRank.
June 10, 2019 at 1:13 pm