






In this post, we take two articles on the same topic from different quality newspapers – one article ranks high on Google, the other doesn’t. ‘Why?’ is the obvious question. A significant part of the answer is revealed by Google’s Natural Language Processing API says Dixon Jones – and he shows how you can easily use the same technique with your own, and your competitor’s content.
This month I have been testing Google’s Natural Language Processing API tool, and I found it to be a great tool to help SEOs write stronger content where “stronger” becomes a numerically measurable score as to what Google understands about the material. Anything measurable is RARE for an SEO tactic! You can even test whether the content is more relevant (or salient) than the content currently ranking on Google. It’s a powerful tool, most likely leveraging many of Google’s algorithms, so let’s dive in.
Using Google’s NLP Step by Step
The magic all starts here: https://cloud.google.com/natural-language/ which is Google’s powerful text analysis engine. Unless you can code, you will need to scroll down this page. When you scroll down, you will see that Google Cloud has built a web-based interface that lets you cut and paste any text into the page. (Screenshot below.)
This box is where the magic happens. It will analyse the text to tell you what it is about. You should see a box like this when you scroll down, which is pretty intuitive:

By all means try the sample text Google puts into this box, but I used it to work out why a really good page of content in the New York Times gets no higher than page three of the SERPs whilst the Telegraph can get their content at the top.
First I looked at a page my colleague, Ken McGaffin talks about in the NY Times on Craft Beer.
The NY Times is a great paper (most of the time) and you would think that their content ranks generally well, but according to the team over at SEMRush, this page could do with some help:
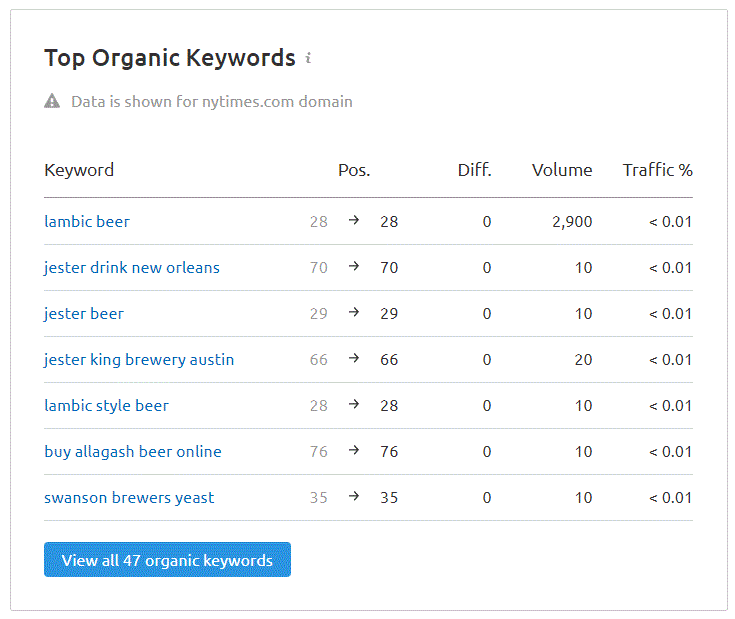
In the above chart, it seems this page is STRONGEST (In Google’s eyes) for the phrase “Lambic Beer”… but it only ranks 28. We can see just HOW much Google thinks this article is about Lambic Beer by cutting and pasting the body of the text from the article into the Google Cloud NLP “try it” box. When doing so, we see initially see this:

Google’s NLP AI takes the content and splits it up into what we understand as “entities”. The Entities are shown in colour with a little number below each one. The numbers are actually relative rankings based on the SALIENCE of the entity within the article itself. So the most salient entity is “(mr.) stuffings”(!) – It seems that the phrase “mr” is scored, but then dropped in th final analysis. If you scroll down below this table, you see these entities listed, in salience order, and with a score between 0 and 1 for each entity:
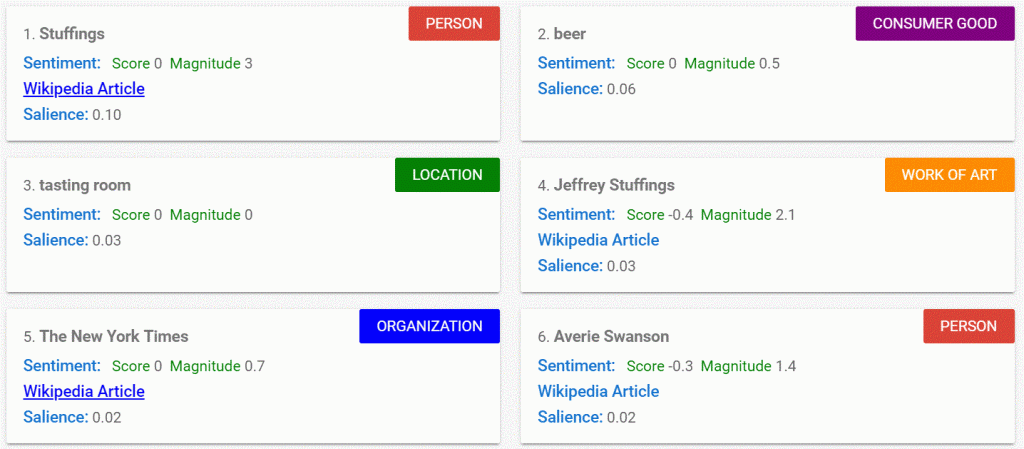
These are the top six entities… the word “beer” is the second most saleint (or relevant) entity with Mr. Jeffery Stuffings seeming to appear twice. “Lambic beer” which is the best organic performing phrase according to SEMrush only starts to make an appearance at position 8:

So now we have some absolute numbers. The salience of “beer” in this article is 0.06 (out of a maximum of 1). The salience of “Lambic” is 0.02 out of 1. Without a comparison, it’s hard to know whether this is good or bad, so let’s type in “Lambic Beer” into Google and pull out a competing article. I pulled out this one from the Telegraph. Once again I cut and pasted the body of the story into the Google NLP tool. This time there is a huge difference!

Google’s NLP tool shows that the word “Lambic” is the number 1 most salient entity mentioned in this article. The score is 0.25 out of a maximum score of 1. That is a LOT stronger than the 0.02 we saw in the first article.
Not only this, but Google has also shown us the entity types… “organisation”, “person”, “Consumer goods”, showing how Google has not just understood the words, but what they mean as well.
Surfacing the Relevance and Saliency of a piece of Content
Google has understood for some years now that unstructured content is hard to file and categorise. If you go to a real world library and ask for a book on the “Earth”, does the librarian direct you to the Astronomy section or the Geology section? The History section or the Maps section? Without more information about your request, the librarian cannot say, but here’s the rub that kills libraries: They need to have already put each book in one section, before you ask the librarian! A really clever library might have several copies of the right book in several sections to cover all the bases, but ultimately, the limitation of the library is that moving the books (or pages or chapters) between sections is just not possible.
By reading ALL of the content of all of the unstructured pages, Google is breaking down the bits of content, each individual piece of meaning, into smaller and smaller components. Now, not only is a website about many things, even a PAGE is about many things. In fact, even a single sentence can (and is) about many things.
The natural endpoint of this, several years from now, is that Google will hardly ever return actual web URLs, which is a philosophical point that I enjoy debating with SEOs at conferences. In the meantime, SEOs want traffic to their web pages, so the challenge remains the same if that is the goal… how to make YOUR web page content more salient than that of the competition?
Google’s Natural Language Processing API Toolkit
Google and the information retrieval industry have now spent immense resources developing multiple approaches to Natural Language Processing. There is CBOW (Continuous Bag of Words), Word2Vec, Skipgrams, nGrams, Harmonic Centrality and Topical PageRank to name a few buzzwords – all of which are backed up with research papers and patents and algorithms. But how do we know what ones Google actually use, and what will happen if we develop a new methodology only to find Google changing its algorithms just as we go live?
I think the answer is to use Google’s own Natural Language Processing API when creating your content. Google’s NLP API is not only publicly available, but you also do not have to be a programmer to use it! True – I imagine after reading this post, most of the SEO tools will start asking for your Google API keys so they can leverage this data, but right now I’m going to show you how Google interprets not only your content but your competitor content as well.
Hypothesis: NLP Salience is a big, and measurable Search Factor!
Barry Schwarz broke the news back in 2016 that content is one of the three main factors in Google’s algorithms (as of the date of his post) with this now infamous headline:
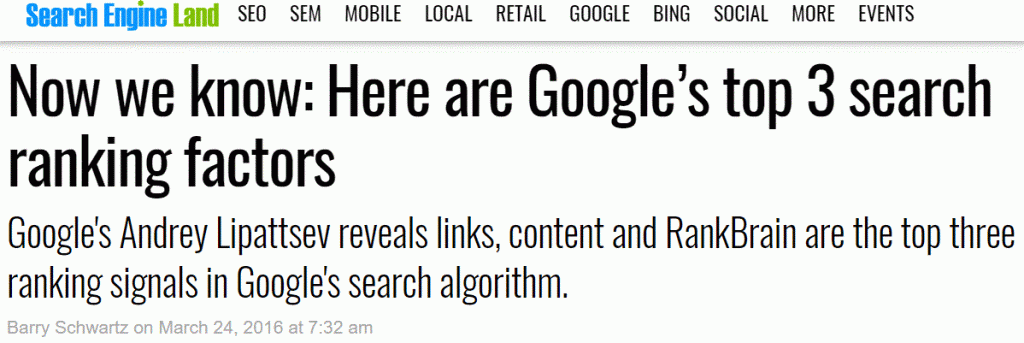
I think that you could do a LOT worse than using the salience score to assess how Google rates and interprets your content. Google’s FIRST objective (even more than money) is to try to return RELEVANT results to the user. Failing to do so, will rapidly result in a loss of trust by customers. So it makes sense that Salience/Relevance beats Expertise, Authority and Trust to a point. Google must FIRST feel that the candidate result overcomes a saliency threshold before it can turn to these other factors to differentiate different content which it can confidently describe as being about the same entity.
Here is another way to think of this. In our “Lambic Beer” example, Google found a top result that it was confident enough to be about Lambic beer, All things being equal, the user probably would only care if they were trying to find the organization behind Lambic Beer, but since it is a generic product, there isn’t one (at least, not a significant one that Google could find) so Google can then focus on E-A-T factors, in the safe beliefs they are improving a dataset’s order, rather than losing the salient information.
Keyword Relevancy vs Keyword Density
Back in the golden days of search, we used to use a phrase called “keyword density”. It was really never was a good metric… it was encouraging keyword stuffing instead of conveying useful information. Over the years, SEOs started to become over obsessed with keywords, looking at which words had the most views by using the Google Adwords API and other tools and then writing content that tried to fill in the gaps. Eventually, the approach became so omnipotent, that Google took away the AdWords API from the pure SEO tools. You can still find plenty of Keyword suggestion methodologies though. I am not going into these today.
For a short while there, Google convinced us that we should not be chasing keywords. Instead we should “just concentrate on good content that people will love”. (That – right there – is a chasm of the same philosophy described with different sentiments. )
Interestingly, Google’s relentless move towards turning unstructured data into structured data is in danger of bringing SEOs full circle.
There is Much Left for SEOs to Test
This approach makes intuitive sense, but other SEOs should look at this tool further and try to understand how important the algorithms are behind the tool. I noticed a number of unanswered things when doing this test. For example:
- Google treats capitalised words differently to non-capitalised words in the NLP entity output. How does it then work out a lazy surfer from a non-lazy search?
- “Mr. stuffings”, “stuffings” and “Jeffery stuffings” were all itemised in the text list, but “Mr. stuffings” and “stuffings” were ranked as the same entity, whilst “jeffery stuffings” was unique. They were all identified as an individual and linked to the same Wikipedia article, so why separate them at all?
- Note how much Google is relying on Wikipedia to provide some kind of validity to its scoring… but this is a bias in their algorithms which may cause concern in the longer term. One rogue Wikipedia editor can cause havoc, editing the competition.
- Lastly, looking at the entity’s attribute in the top right corner of each box, this looks like the entity “type” as described in the documentation, however, a single entity can have many types, so it is intersting to see that Google has selected a type in context.
I invite SEO practicioners to look at this in more depth. I imagine some will jump on the API and feed it into their SEO suites… Google actually looks happy to charge the end users for their use if you do this.
If you want to read further into Google’s different algorithms, we have a selection of articles for you to read:
How PageRank Really Works: Understanding Google
Google’s updated guidelines – what’s changed?
Video: Google’s now 20 years old – what does the future hold?
- How Important will Backlinks be in 2023? - February 20, 2023
- What is in a Link? - October 25, 2022
- An Interview with… Ash Nallawalla - August 23, 2022
Thanks for this post! NLP really is one big chunk to digest and the API makes it so much easier to implement language processing for any businesses.
March 8, 2019 at 1:13 pmThanks!
March 20, 2019 at 11:59 amGreat post on a potentially fantastic feature from Google.
March 18, 2019 at 1:12 pmI have a few issues using this tool IRL and as you state yourself the tool obviously treats capitalized words differently than the non-capitalized ones.
In general I see that the tools somehow returns a great deal of duplicate entities.
With the content from a German webpage, the top 12 most salient keyword contained two words that was duplicate 4 times each with exactly same spelling and casing. I.e. 8 out of top 12 were duplicates.
I don’t expect you to answer why that is – I just wanted to add one to your experiences/questions and hopefully someone reads this and enlightens us all.
I also found an unanswered question on stackoverflow adressing the same issue.
After all, due to my example above (and many others) I find the tool close to useless for now.
Thanks for the additional info, Soren. Yes – the tool is rather granular! Then again. "Majestic" capitalised and "majestic" non-capitalised make for very different entities, I would imagine. There are other projects/algorithms at Google which bundle up these split entities into groups, I would assume. Certainly, Google derives "topicality" from links, so those topics are probably important and misunderstood by us as SEOs.
I wonder, though, whether the 8 out of 12 duplicates in your list doesnt give us a clue to better content SEO? If you are ranking WELL, on that page, then I guess Google has correctly bundled the duplicate meanings together well. if not, then perhaps this tells us that the content uses too a vocabulary that is too varied? I uderstand, though, that German is a very different language structure to English. Perhaps this works better in some languages than in others?
March 20, 2019 at 12:08 pmThat’s the amazing post, Dixon!
Looks like non-standard approach (instead of classic keyword stuffing) in content SEO. I appreciate it.
Cheers!
March 24, 2019 at 10:11 amThanks!
May 9, 2019 at 11:43 amHey Dixon, thanks this is super insightful for me.
Should I use this as a guide to help me increase saliency of the topics I want to rank for?
If so, then I agree with your comment that this may bring us SEOs full circle on the practice of keyword stuffing hahaha.
March 28, 2019 at 2:28 pmI don’t know about using it as a guide! I think it needs a little more depth of testing to make sure it can actually improve a page. The problem seems to be that the algorithm does not collect thoughts in the way one might expect. I’ll take a few pages, run them through this and try and rewrite my content and report back! 🙂
May 9, 2019 at 11:43 amThanks a lot for the API. Can I do this on my site?
April 1, 2019 at 11:10 amOne can use the NLP api, to ‘crawl’ a complete website, that of yours and your competition. That will give you all keywords and topics used on a particular website. Whichs is a treasure trove for (competetive) keyword research. I think it’s like the internal links feature of screaming frog, where you easily calculate all links and anchors. This tells you site wide what keywords are used. Nice post Dixon!
April 15, 2019 at 8:42 pm